Parametry dwuwymiarowych zmiennych losowych
Dwuwymiarowa zmienna losowa: zdarzenie elementarne można opisać za pomocą
uporządkowanej pary liczb (xi, yi), np. pomiary prądu i napięcia na oporniku.
Kowariancja
xy EX E ( X ),Y E (Y ) cov( X , Y )
dla zmiennej losowej ciągłej
xy x x y y f ( x)dxdy
dla próby n-elementowej wylosowanej z populacji
1 n
S xy xi x y i y
n i 1
gdy xy=0, to te dwie zmienne są niezależne.
Współczynnik korelacji liniowej
xy
dla populacji generalnej
x y
r
S xy
dla próby
SxSy
(1)
Współczynnik r jest estymatorem zgodnym (ale obciążonym, E(r)) współczynnika .
Współczynnik korelacji musi być zawarty w przedziale (-1, +1). Gdy =0, to nie zachodzi
korelacja, zmienna X nie wpływa na zmienną Y. Korelacja jest maksymalna, gdy =1.
Wzory do obliczania kowariancji i współczynnika korelacji liniowej
S xy
1
1
xi x y i y x i y i y x i x y i x y
i
1
i 1
i 1
i 1
n
n i 1
n
n
n
n
n
n
xi y i
i 1
n
n
y
xi
i 1
n
n
x
yi
i 1
n
1
( nx y )
n
n
xi y i
i 1
n
yx x y x y
1 n
1 n n
xi y i 2 xi y i
n i 1
n i 1 i 1
(2)
xi x
n
S x2
i 1
n
2
n
1 n 2
1 n 2
1 n 2
2
2
2
2
xi 2 x xi nx xi 2nx nx xi nx
i
1
i
1
i
1
i
1
n
n
n
(3)
1 n
1 n 2
xi2 2 xi
n i 1
n i 1
Zatem współczynnik korelacji liniowej z próby
n
r
S xy
n
n
n x i yi x i yi
i 1
i 1
i 1
n x 2 x n y 2 n y
i 1 i i 1 i i 1 i i 1 i
Wzór powyższy otrzymuje się po podstawieniach równań (2) i (3) do (1) oraz pomnożeniu
licznika i mianownika przez n2.
Wnioskowanie dotyczące korelacji. Odpowiadamy na pytanie, czy istnieje korelacja pomiędzy
dwiema zmiennymi.
2
2
Sx Sy
n
n
2
n
2
Hipoteza zerowa:
H0: =0 (nie ma korelacji)
Hipoteza alternatywna
Ha: >0
Funkcją testową jest zmienna losowa Studenta t o (n-2) stopniach swobody
t
r
n2
1 r 2
0.40
0.35
0.30
0.25
0.20
1-
/2
0.15
/2
Z tablic rozkładu Studenta
odczytujemy – dla wcześniej
przyjętego poziomu istotności wartość krytyczną tn-2,. Jeżeli
obliczona wartość t znajduje w
dwustronnym obszarze krytycznym
(-, - tn-2,), (tn-2,, +), to H0 należy
odrzucić na korzyść hipotezy Ha
0.10
0.05
0.00
-3
-2
-1
-t
0
1
2
t
n,
3
n,
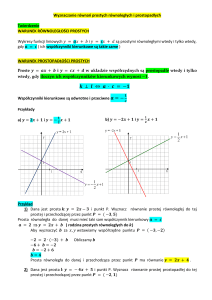
Regresja liniowa
Równanie wiążące dwie zmienne losowe, wchodzące w skład dwuwymiarowej zmiennej
losowej nazywa się równaniem regresji. Gdy równanie to jest liniowe, mówimy o regresji
liniowej.
Dla populacji
Dla próby
y=x+
y=ax+b
, - współczynniki regresji
a, b – współczynniki regresji
liniowej w populacji
liniowej dla próby
Współczynnik kierunkowy prostej a i współczynnik przesunięcia b są estymatorami
współczynników i . Empiryczne współczynniki regresji liniowej a i b oblicza się metodą
najmniejszych kwadratów. W metodzie tej minimalizowana jest pewna funkcja S(a, b) zależną od współczynników a i b - będąca sumą kwadratów odchyłek punktów
doświadczalnych od poszukiwanej prostej. Ogólne równanie na funkcję S można zapisać w
postaci
S w( xi )xi X i w( yi ) yi Yi
n
i 1
2
2
gdzie (xi, yi) są zmierzonymi parami punktów, (Xi, Yi) odpowiadającymi im punktami na
prostej, w(xi) i w(yi) – wagami, odpowiednio x-ową i y-ową punktu i-tego. Wagi są
odwrotnościami kwadratów niepewnościami odpowiednich punktów pomiarowych,
2
2
w( y i ) 1 / y i , gdzie oznacza odchylenie standardowe. W
zatem w( xi ) 1 / xi ,
zależności od naszej wiedzy o niepewnościach mierzonych punktów pomiarowych można
rozpatrzyć 5 przypadków wyznaczania prostej metodą najmniejszych kwadratów.
(I)
Gdy y=ax+b jest prostą regresji cechy Y względem X. Jest to historycznie pierwszy
rozpatrzony wariant metody dopasowania prostej do wyników eksperymentalnych (Legendre,
Laplace, Gauss). Można go nazwać normalną metodą najmniejszych kwadratów (ang.
normal least squares). Stosujemy ten przypadek wtedy, gdy niepewnościami obarczone są
1
jedynie wielkości yi, zatem Xi=xi. Przyjmujemy, że wszystkie wagi są równe 2 . Odchyłka i
tego punktu (xi, yi) od linii prostej będzie równa y y i axi b . Zaznaczona jest ona
odcinkiem prostej na rysunku poniżej. Suma kwadratów S, którą minimalizujemy będzie
równa S
1
2
2
i .Aby wyznaczyć współczynniki a i b różniczkujemy S względem a i
n
i 1
względem b, a otrzymane pochodne
przyrównujemy do
S
S
0,
0 . Mamy zatem
zera:
a
b
układ dwu równań z dwiema
niewiadomymi:
n
y i a bxi 0
i 1
n
y i a bxi xi 0
i 1
Rozwiązując ten układ równań
otrzymamy
20
15
Y
10
5
0
-5
0
2
4
6
8
10
X
n
a
n
n
n xi y i xi y i
i 1
i 1
n
n xi xi
2
i 1
b
i 1
n
2
n
n
i 1
i 1
n
n
2
xi y i xi xi y i
n
i 1
i 1
n
n xi xi
i 1
2
i 1
2
i 1
Powyższe wzory na współczynniki a i b można także zapisać w zwięzłej postaci:
ar
Sy
S xy S y
SxSy Sx
S xy
b y ax
S x2
Otrzymana prosta przechodzi przez punkt ( x , y ) .
(II)
Gdy y=a’x+b’ jest prostą regresji cechy X względem Y. Stosujemy ten
przypadek wtedy, gdy niepewnościami obarczone są jedynie wielkości xi. Wtedy metoda
najmniejszych kwadratów daje
następujące wzory na a’ i b’:
20
Sx
15
Y
10
2
1 Sy Sy
a'
r S x S xy
5
b' y a ' x
0
-5
0
2
4
6
X
8
10
Także ta prosta przechodzi przez punkt ( x , y ) . Gdy współczynnik korelacji r ma wartość 1,
to proste (II) i (I) pokrywają się. Gdy 0<r<1, to obie proste przecinają się w punkcie ( x , y ) ,
tworząc pewien kąt między sobą.
(III) Gdy y=a’’x+b’’ jest prostą regresji ortogonalnej. Stosujemy ten przypadek wtedy,
gdy niepewnościami o takiej samej wielkości obarczone są zarówno x jak i y, jak
również i wtedy, gdy niepewności nie są znane. Model ten nazywany jest także
modelem standardowym z wagami (ang. standard weighting model). Zakładamy,
że wagi w funkcji S są wszystkie takie same i równe jedności. Odchyłką jest w
tym przypadku odcinek prostopadły do
20
linii prostej (rysunek obok), zatem
y
i minimalizowana suma
1 a2
axi b
kwadratów S
.
i 1
1 a2
Metoda najmniejszych kwadratów
daje następujące wzory na a’’ i b’’:
n
y
15
2
10
i
Y
5
0
Sy Sx
2
a' '
2
S
2
y
-5
S x 4S xy
2
2
0
2
2
4
6
8
10
X
2S xy
b' ' y a ' ' x
Model standardowy z niezależnymi wagami
(IV)
W modelu tym (ang. standard independent weighting model) niepewności występują zarówno
dla xi jak i dla yi. Wszystkie niepewności x-owe są takie same, tzn. w(xi)=w1, a także
wszystkie niepewności y-owe są równe, tzn. w(yi)=w2. Dla każdego punktu pomiarowego (xi,
yi) wprowadzamy efektywną wagę (taką samą), zdefiniowaną następująco
w1 w2
w
w1 a 2 w2
co spowoduje, że funkcja sumy kwadratów S przyjmie postać
n
S (a, b) w ( yi axi b) .
i 1
Przyrównanie pochodnych cząstkowych tej funkcji do zera daje nam dwa równani, z których
można obliczyć współczynniki a i b;
1/ 2
2
2
2
2
2
2
n
2
n
n
2
n
2
2
2
2
2
w2 n y i y i w1 xi n xi
w n y i y i w1 xi n xi
i 1
i 1
2
i 1
w1
i 1
i 1
i 1
i 1
i 1
a
n
n
n
n
n
n
2 w2 n x i y i x i y i
2 w2 n x i y i x i y i
w2
i 1
i 1
i 1
i 1
i 1
i 1
b
n
n
i 1
i 1
y i a xi
n
Równanie na współczynnik a daje dwie wartości; jedna (właściwa) odpowiada minimum
funkcji S, druga odpowiada maksimum funkcji S dla dowolnej linii prostej przechodzącej
przez punkt ( x , y ) .
(V)
Model z niezależnymi wagami
W modelu tym nierównymi niepewnościami obarczone są xi i yi. Wprowadźmy efektywną
wagę i-tego punktu
w( xi ) w( yi )
w( xi ) a 2 w( yi )
Wtedy funkcja S przyjmie postać
wi
n
S (a, b) wi ( yi b axi )
i 1
Przyrównanie pochodnych cząstkowych tej funkcji do zera daje nam dwa równani, z których
współczynników a i b nie można wyznaczyć analitycznie, a jedynie metodą iteracji.