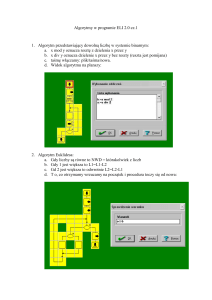
Złożoność algorytmów
Literatura: 1. The Euclidean Algorithm, Michael Monagan, [email protected];
2. W.M. Turski, Propedeutyka
1. Złożoność obliczeń
Podamy kilka przykładów algorytmów i omówimy ich złożoność, efektywność,
w sensie czasu wykonania.
1.1. Algorytm
Turski: Algorytm – informatyczny opis rozwiązania.
Nazwa algorytm pochodzi od nazwiska arabskiego matematyka Muhammeda
ibn Musy al-Chorezmi (z Chorezmu), który opisał system dziesiętnego kodowania
liczb i sztukę liczenia w tym systemie. Było to ok. roku 820 n. e.
Obecnie przez algorytm rozumie się opis obiektów wraz z opisem czynności,
które należy wykonać z tymi obiektami, aby osiągnąć określony cel.
Opisy obiektów występujących w algorytmie będziemy nazywać deklaracjami,
a czynności – instrukcjami.
1.2. Algorytm Euklidesa. Co to jest złożoność algorytmu
Cel jaki stawiamy przed sobą to poznanie algorytmu Euklidesa znajdowania największego
¯
wspólnego dzielnika (nwd) dwóch liczb całkowitych dodatnich i szczegółowe opra¯
¯
cowanie tego prostego algorytmu.
Co to jest nwd? Jeśli zapiszemy dwa ułamki 64/20 i 16/5 to różnica między nimi
polega na tym, że pierwszy ma licznik i mianownik większe od drugiego o czynnik 4.
Oba są jednak takie same. Ułamek drugi jest skróconą wersją pierwszego. Wspólnym czynnikiem przez które podzieliliśmy licznik i mianownik jest liczba 4. Jest to
największa z liczb, przez które obie liczby 64 i 20 dzielą się bez reszty.
Można rozłożyć obie liczby na czynniki pierwsze i napisać
64 = (2)6
20 = (2)2 (5).
Widzimy, że maksymalny czynnik wspólny wynosi (2)2 = 4. Metoda rozkładu liczb
na czynniki pierwsze nie jest najlepszą z metod znajdowania nwd. Załóżmy bowiem,
że liczby, których nwd szukamy są liczbami o ok. 100 cyfrach. Kiedy znajdziemy tą
metodą wszystkie pierwsze czynniki obu liczb?
Około 300 lat p.n.e. Euklides, który nie znał żadnego języka programowania,
zapisał w języku greckim algorytm znajdowania nwd. (I hope that what follows is
not a Greek to you. Monagan, M., ETHZ). Algorytm Euklidesa jest prosty. Załóżmy,
że mamy dwie dodatnie, całkowite liczby a i b. nwd posiada następujące własności
1. nwd(a, 0) = a,
2. nwd(a, b) = nwd(b, a),
3. nwd(a, b) = nwd(a − b, b).
1
(Trzecia własność: Jeżeli g = nwd(a, b) i h = nwd(a −b, b) to g = h. Najpierw
pokażemy, że g dzieli h (co zapiszemy g|h), a następnie, że h|g. W ten sposób h = g.
1. (pokażemy, że g|h) Mamy g = nwd(a, b), a więc g|a i g|b. Stąd a − b = g ∗
(a/g) − g ∗ (b/g) = g ∗ (a ′ − b ′ ), tzn. g|(a − b). Stąd g|h = nwd(a − b, b). 2.
(pokażemy, że h|g) Mamy h = nwd(a − b, b). Stąd h|(a − b) i h|b, a więc h|a i
dlatego h = nwd(a, b) → h|g.)
Algorytm Euklidesa oparty jest na fakcie, że nwd(a, b) = nwd(a − b, b) Jeżeli
a ≥ b to korzystamy z własności nwd(a,b)=nwd(b,a) i przezywamy liczby a ↔ b, a
w przypadku b = 0 mamy nwd(a, 0) = a.
Algorytm obliczania nwd wygląda więc następująco.1
START
w razie, gdy b=0 -> a
w razie, gdy a<b -> nwd(b,a)
-> nwd(a-b,b)
KONIEC
Algorytm jest rzeczywiście prosty. A oto wyniki pośrednie otrzymane na drodze
zastosowania tego algorytmu dla liczb a=64, b=20:
(64,20)
(44,20)
(24,20)
(4,20)
(20,4)
(16,4)
(12,4)
(8,4)
(4,4)
(0,4)
(4,0)
->
->
->
->
->
->
->
->
->
->
=> 4.
Zapiszemy jeszcze inną wersję słowną algorytmu Euklidesa:
START
dopóki a <> b, dopóty wykonuj
jeśli a > b to a-b -> a
w przeciwnym wypadku b-a -> a;
wypisz(a)
KONIEC
1.3. Złożoność algorytmu
Czy algorytm Euklidesa w przedstawionej postaci jest efektywny? Pomyślmy co
się stanie gdy a = 1010 a b = 10. W tym przypadku będą wykonywane kolejne
odejmowania, aż otrzymamy zero. Odejmowań będzie 1010 , czyli 1010 kroków albo
elementarnych instrukcji. Licząc, że w czasie 1 sec wykonywanych będzie 1 milion
takich operacji na wynik obliczeń przyjdzie czekać kilka godzin. To co wykonuje
algorytm to odejmowanie b od a, aż do chwili, gdy mamy a < b. Inaczej mówiąc
algorytm jest algorytmem obliczania reszty z dzielenia a przez b. Oznaczmy ją przez
mod(a, b). Zamiast korzystać z nwd(a, b) = nwd(a−b, b) można więc wykorzystać
związek nwd(a, b) = nwd(mod(a, b), b). Najczęściej jest tak, że różne funkcje, takie
jak mod, są częścią języka wyższego poziomu (np. Pascala).
Algorytm obliczania nwd można teraz przepisać do postaci
1 W zapisie jaki tu stosujemy konstrukcja w razie gdy b=0 -> a oznacza, że ten fragment
programu daje wynik a jeżeli b=0.
2
START
w razie, gdy b=0 -> a
w razie, gdy a<b -> nwd(b,a)
-> nwd(mod(a,b),b)
KONIEC
Inną wersją tego algorytmu, która wykorzystuje instrukcję "dopóki W, dopóty
R"jest
START
c:=a, d:=b
dopóki d>0, dopóty wykonuj
r:=mod(c,d)
c:=d
d:=r
koniec pętli dd
KONIEC
(*
pętla dd
*)
Ile operacji wykonuje algorytm w czasie jego realizacji dla liczb a i b mniejszych
od n? Parametr ten można też nazwać złożonością algorytmu. Algorytm Euklidesa
ma złożoność rzędu n2 . Będziemy zapisywać to w postaci Θ(n2 ). Oznacza to, że
liczba wykonanych operacji jest równa
LE = Cn2 , c = constans
Jeśli więc podwoimy liczby a, b to czas obliczeń, który jest proporcjonalny do ilości
operacji, a więc do złożoności algorytmu, staje się czterokrotnie dłuższy.
Efektywność przedstawionego algorytmu Euklidesa jest taka sama jak efektywność
mnożenia liczb całkowitych. (W sprawie LA patrz: Knuth, The art of computer programming, t II).
Z najgorszym przypadkiem spotykamy się wtedy, gdy liczby a i b są liczbami
Fibonacciego.2 Są to liczby ciągu 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, . . . Zadane są one
związkiem rekurencyjnym
f1 = 0, f2 = 1, fn = fn−1 + fn−2 , n = 3, 4, . . . .
Chcąc policzyć nwd(fn , fn−1 ) musimy policzyć nwd(fn−1 , fn−2 ), . . . , czyli musimy
policzyć wszystkie liczby Fibonacciego w odwrotnym porządku. Nasz algorytm zastosowany do liczb a = 55 i b = 34 daje
c
55
34
21
13
8
5
3
2
1
d
34
21
13
8
5
3
2
1
0
r
21
13
8
5
3
2
1
0
→1
Czy można wyznaczyć nwd(a, b) za pomocą mniejszej liczby operacji niż Θ(n2 )?
Okazuje się, że tak, ale nie można zrobić tego tak szybko jak w przypadku dodawania
liczb całkowitych dla którego złożoność jest Θ(n).
Zakończmy ten fragment uwagą o tzw. "Binarnym algorytmie nwd". Ten nadaje
się szczególnie dobrze dla maszyn cyfrowych. Jest on też rzędu n2 . Jego przewaga
2 Fibonacci, właściwie Filius Bonacci czyli syn Bonacciego. Studiował Al Chorezmiego. W
roku 1202 opublikował Liber abaci, w której to książce rozpatrywał m. in. problem rozmnażania się królików, prowadzący do liczb jego imienia.
3
nad poprzednim polega na tym, że jeżeli a i b zapisać w systemie dwójkowym to
pewne operacje można wykonywać szybciej. Liczba operacji może spaść o połowę.
Zaobserwujmy mianowicie, że nwd(2a,2b)=2nwd(a,b) oraz, że nwd liczb nieparzystych jest liczbą nieparzystą, a różnica liczb nieparzystych jest parzysta. Algorytm
zaczyna się od zapisania
a = 2i a ′
b = 2j b ′ ,
gdzie a ′ , b ′ są nieparzyste. Stąd nwd(a, b) = 2min(i,j) nwd(a ′ , b ′ ). Wyznaczanie
i, j i dzielenie przez 2i lub 2j jest bardzo proste gdy liczby całkowite zapisze się w
postaci dwójkowej.
A oto cały algorytm.
nwd(a,b):=
START
b = 0
a = 0
mod(a,2)=0 i mod(b,2)=0
mod(a,2)=0
mod(b,2)=0
a < b
-> nwd(a-b,b)
KONIEC
->
->
->
->
->
->
a
b
2*nwd(a/2,b/2)
nwd(a/2,b)
nwd(a,b/2)
nwd(b,a)
Procedura ta jest szybsza niż oryginalna wersja algorytmu Euklidesa ponieważ w
dwu krokach dzieli przynajmniej jedną z liczb przez dwa. Dzieje się tak nawet wtedy
gdy a i b są nieparzyste gdyż odejmując je od siebie dostajemy wynik podzielny przez
dwa.
1.4. Złożoność algorytmu podwajania
Literatura: M. Davies, Czym jest obliczanie, w Matematyka Współczesna, Dwanaście esejów, red. L. A. Steen, WNT, Warszawa, 1983.
Przypomnijmy jak wyglądał algorytm programu Turinga-Posta podwajania liczby
jedynek umieszczonych na tasiemce papierowej lub magnetycznej. Jak pracuje program podwajania?
1
2
3
4
5
6
7
8
9
10
DRUKUJ 0
(* jeśli jest 1 *)
IDŹ W LEWO
IDŹ DO KROKU 2 JEŚLI PRZECZYTAŁEŚ 1
DRUKUJ 1
IDŹ W PRAWO
IDŹ DO KROKU 5 JEŚLI PRZECZYTAŁEŚ 1
DRUKUJ 1
IDZ W PRAWO
IDZ DO KROKU 1 JESLI PRZECZYTAŁEŚ 1
ZATRZYMAJ SIE
Liczbę jedynek podwaja się poprzez ich kopiowanie jedna za drugą. Każda jedynka jest chwilowo zastępowana przez zero, które odgrywa role znacznika miejsca
(krok 1). Dalej obliczenia przesuwaja sie na lewo przez wszystkie jedynki (wraz
z tymi, które w procesie obliczeń zostały wydrukowane na nowo), aż do nieużywanego (pustego) kwadracika (powtarzane kroki 2, 3). W kroku 4 jedynka zostaje
skopiowana. Nastepnie obliczenia idą na prawo aż do napotkania zera, które zajmuje
miejsce właśnie skopiowanej jedynki (kroki 5, 6 - powtarzane). Skopiowana jedynka
jest ponownie zapisana (krok 7). Obliczenia idą dalej w prawo w poszukiwaniu
4
nowej jedynki, którą trzeba skopiowac (krok 8). Jesli istnieje nowa jedynka to obliczenia przenosza sie do kroku 1. W przeciwnym razie idą do kroku 10 i zatrzymują
sie (kroki 9, 10).
Algorytm ten jest wygodny dla celów dyskucji któą chcemy teraz przeprowadzić.
Zauważmy, że algorytm ten i każdy jego fragmenty, można powtarzać dowolną
liczbę razy dzięki instrukcji IDŹ DO, która powoduje powrót do wcześniej wykonanego polecenia. Taka sama instrukcja IDŹ DO pozwala też przeskoczyć do przodu
grupę poleceń.
Widzieliśmy, że kod zero-jedynkowy tego programu (tablica kodowania jest podana poniżej) ma postać 1 000 010 110 110 001 011 110111110 001 011 11010
100 111 i pomijając znaki przestankowe: 1 na początku i 111 na końcu oraz nieznaczące znaki puste, które zostawiliśmy dla przejrzystości zapisu, liczy 41 znaków.
Kod
Instrukcja
000
001
010
011
101 |{z}
0...0 1
i
110 |{z}
1...1 0
100
i
DRUKUJ 0
DRUKUJ 1
IDZ w LEWO
IDZ w PRAWO
IDZ do KROKU i JESLI PRZECZYTALES 0
IDZ do KROKU i JESLI PRZECZYTALES 1
ZATRZYMAJ SIE (stop=100p)
Zastanowimy się teraz nad problemem jak złożony musi być program Turinga-Posta,
aby w wyniku jego działania otrzymać dany wynik.
Rozpatrzymy tylko przypadek, gdy na taśmie w chwili zakończenia obliczeń znajdują się co najmniej dwie jedynki. Wynik składa się wtedy z ciągu zer i ciągu jedynek
położonych pomiędzy skrajnymi jedynkami na taśmie (znakami przestankowymi).
Załóżmy, że jako wynik chcemy otrzymać ciąg 1022 jedynek. Jeśli dodamy do tego
dwie jedynki ograniczające to taśma w chwili zakończenia obliczeń ma zawierać
1024 jedynki. Reszta taśmy ma być pusta. Możemy wprost zapisać te 1024 jedynki i
uważać, że zrobiliśmy co należy. Możemy jednak postąpić lepiej. Wystarczy napisać
na taśmie 512 jedynek i uruchomić program podwajania opisany przed chwilą. Jak
wiemy, program ten składa się z 41 bitów (bit oznacza z ang. binary digit czyli cyfrę
dwójkową). Mamy zatem opis ciągu 1022 jedynek, który używa 41 + 512 = 553
bity. Można postąpić jeszcze lepiej. 1024 = 210 , a więc można zastosować program
podwajania dziesięciokrotnie zaczynając od jednej jedynki.
Poniżej (Davies) przedstawiony jest 22 krokowy program, który to robi jeszcze
inaczej. Pierwszych 9 kroków pokrywa się z programem podwajania. Proces obliczeń rozpoczyna się od danych
1 0 11
. . . 1} .
|{z}
| {z
n
↑
Po wykonaniu obliczeń na taśmie znajdzie się blok 2n+1 jedynek.
1
2
3
4
5
6
7
8
DRUKUJ 0
IDŹ W LEWO
IDŹ DO KROKU 2 JEŚLI PRZECZYTAŁEŚ 1
DRUKUJ 1
IDŹ W PRAWO
IDŹ DO KROKU 5 JEŚLI PRZECZYTAŁEŚ 1
DRUKUJ 1
IDŹ W PRAWO
5
9
10
11
12
13
14
15
16
17
18
19
20
21
22
IDŹ DO KROKU 1 JESLI PRZECZYTAŁEŚ 1
IDŹ W PRAWO
IDŹ DO KROKU 22 JEŚLI PRZECZYTAŁEŚ 0
IDŹ W PRAWO
IDŹ DO KROKU 12 JESLI PRZECZYTAŁEŚ 1
IDŹ W LEWO
DRUKUJ 0
IDŹ W LEWO
IDZ DO KROKU 16 JESLI PRZECZYTAŁEŚ 1
IDŹ W LEWO
IDZ DO KROKU 18 JESLI PRZECZYTAŁEŚ 1
IDŹ W PRAWO
IDZ DO KROKU 1 JESLI PRZECZYTAŁEŚ 1
ZATRZYMAJ SIE
Opiszmy pokrótce działanie tego programu. Kroki 1-9 to poznany wcześniej
program podwajania. Część ta podwaja liczbę jedynek znajdujących się na lewo
od zera. Kroki 10-21 wymazują jedną jedynkę znajdującą się na prawo od zera i
następuje powrót do kroku 1. Gdy program wymaże wszystkie jedynki znajdujące
się na prawo od zera to w kroku 11 zostanie przeczytane zero. Wtedy nastąpi skok
do kroku 22 (do przodu) i program się zatrzyma. Liczba jedynek, które znajdują się
początkowo na lewo od zera, jest podwajana tyle razy ile jedynek znajduje się początkowo na prawo od tego zera. Kod całego programu zajmuje 155 bitów. (Zadanie:
Sprawdzić to przez kodowanie zgodne z poprzednio zdefiniowanym.) Aby otrzymać
żądany ciąg 1024 jedynek, potrzebny jest ciąg danych 10111111111. Prowadzi to
do 155+11=166 bitów co stanowi znaczną poprawę w stosunku do 553 bitów.
Podamy teraz pewną definicję. Przez w oznaczymy dowolny ciąg bitów. Mówimy, że w posiada złożoność n (lub pojemność informacji n, co zapisujemy jako
I(w) = n, jeżeli
1. Istnieje program P i ciąg v, takie, że długość kod(P) i długość v wynoszą razem n, oraz takie, że jeśli program P rozpocznie obliczenia na v, to zatrzyma się
ostatecznie z wynikiem w (tzn. z ciągiem 1w1) zajmującym niepustą część taśmy
oraz
2. Nie istnieje liczba mniejsza od n, dla której to samo zachodzi.
Jeżeli w oznacza ciąg 1022 jedynek, to pokazaliśmy, że I(w) ≤ 166. Ogólnie można
pokazać, że dla ciągu bitów (zer i jedynek) o długości n złożoność I(w) ≤ n + 9
W szczególności, jeśli program P składa się tylko z jednej instrukcji: Zatrzymaj
się to ponieważ nic on nie robi, więc rozpoczynając obliczenia z danymi 1w1 zatrzyma się natychmiast i pozostawi na taśmie niezmieniony ciąg 1w1. Ponieważ
kod(P)=1100111, więc prawdą jest, że I(w) musi być mniejsze lub równe długości
ciągu 11001111w1, tj. mniejsze lub równe n + 9. Liczba 9 wynika z przyjętej metody
kodowania i nie posiada żadnego teoretycznego znaczenia.
Policzymy teraz ciągi o długości n takie, że I(w) ≤ n−10? (Zakładamy n > 10.)
Każdy taki ciąg jest związany z programem P i ciągiem danych v takich, że kod(P)v
jest ciągiem bitów o długości mniejszej lub równej n − 1. Ponieważ łączna liczba
ciągów bitów o długości i wynosi 2i , to istnieje tylko
2 + 4 + . . . + 2n−10
ciągów bitów o długości ≤ n − 10. Jak łatwo policzyć jest to liczba równa 2n−9 − 2
(suma ciągu geometrycznego). Ponieważ istnieje 2n ciągów bitów o długości n to
stosunek liczby ciągów o długości n i o złożoności ≤ n − 10, do liczby wszystkich
ciągów o długości n, nie przekracza liczby
1
1
2n−9
= 9 <
.
2n
2
500
6
Jest to mniej niż 0.2%, a więc więcej niż 99.8% wszystkich ciągów o długości n ma
złożoność I(w) > n − 10.
Literatura: W. M. Turski, Propedeutyka informatyki, Warszawa, 1989
n - charakterystyczny rozmiar zadania. Często, zamiast trudnej do ustalenia
dokładnej złożoności obliczeniowej wprowadza się oszacowanie w postaci pewnej
funkcji f(n), takiej że ∃n0 ∀n > n0 {LA (n) ≤ f(n)}. W roli f(n) występują takie
funkcje jak n, n3/2 . . . . , log n, n log n, . . . , 2n ,. . . , pomnożone czasami przez stałe
współczynniki. Ponieważ zależy nam na tym by jak najlepiej oszacować złożoność
obliczeniową danego zadania, to spośród funkcji, które można przyjąć za oszacowanie wybieramy tę, której wzrost wraz z n jest najwolniejszy. Jeżeli od pewnego n0
zachodzi LA ≤ n, a od pewnego n1 mamy LA ≤ n2 to za f(n) bierzemy n.
Mówimy: złożoność obliczeniowa jest rzędu f(n) (np. mnożenie liczb posiada
złożoność rzędu n2 , a dodawanie rzędu n).
Znajomość złożoności obliczeniowej danego algorytmu pozwala oszacować czas
wykonywania zadania.
Przykład. Jak już wiemy, ciągiem Fibonacciego nazywamy ciąg liczb zadany zależnościami:
f1 = 0 , f2 = 1 , fi = fi−1 + fi−2 , dla i > 2.
(1)
Problem polega na znalezieniu n-tego wyrazu tego ciągu. Za rozmiar charakterystyczny można przyjąć numer n wyrazu.
Algorytm 1 Wykorzystujemy bezpośrednio związek rekurencyjny (!) (1). bliczamy
f1 , f2 i dalej kolejne wyrazy ciągu, aż do chwili gdy obliczymy interesujący nas
wyraz n-ty. Wykonanie jednego kroku polega na wykonaniu jednego dodawania.
Złożoność algorytmu jest więc rzędu n.
Algorytm 2 (patrz: Turski) Można sprawdzić (przez indukcję), że
f2k
=
f2k + f2k+1
f2k+1
=
(2fk + fk+1 )fk+1 .
(2)
Rozwinięcie dwójkowe liczby n jest:
n = cl 2l + cl−1 2l−1 + . . . + c1 2 + c0 ,
(3)
gdzie każde ci jest równe 0 lub 1. Krok przygotowawczy algorytmu polega na znalezieniu współczynników rozwinięcia (3) i ustaleniu bazy dalszych obliczeń
b1 = f 1 = 0 , b2 = f 2 = 1 .
W kolejnych krokach (i = 1, . . . , l) postępujemy zgodnie z następującym schematem.
1. Z wzorów (2) obliczamy nową bazę
b1 = f2k , b2 = f2k+1 ,
gdzie numery k i k + 1 są numerami wyrazów ciągu Fibonacciego uznanych za
ppoprzednią bazę.
2. Sprawdzamy jaki jest współczynnik cl−i rozwinięcia dwójkowego (3). Jeśli
cl−i = 0 to kończymy krok i-ty, w przeciwnym wypadku obliczamy nową bazę
b1 = f2k+1 , b2 = f2k+2 ,
wykorzystując związek
f2k+2 = f2k+1 + f2k .
7
(patrz definicja ciągu Fibonacciego (1)). Znaleziona baza stanowi podstawę wykonania następnego kroku ((i+1) -szego). Jeśli i = l to algorytm jest zakończony,
a obliczony w nim pierwszy element bazy, b1 jest poszukiwanym wyrazem ciągu
kn .
Przykład. Znajdziemy f23 . Mamy 23 = 1 · 24 + 0 · 23 + 1 · 22 + 1 · 21 + 1, a więc
c4 = 1 , c3 = 0 , c2 = 1 , c1 = 1 , c0 = 1 oraz l = 4. A oto kolejne kroki.
Krok 0
b1 = f 1 = 0 , b2 = f 2 = 1
Krok 1
b1 = f2 = f21 + f22 = 1 ,
b2 = f2 = (2f1 + f2 )f2 = 1
c3 = 0 .
Krok 2
b1 = f4 = f22 + f23 = 2 ,
b2 = f5 = (2f2 + f3 )f3 = 3 .
c2 = 1 , f6 = f5 + f4 = 5 ,
b1 = f5 = 3 ,
b2 = f6 = 5 .
Krok 3
b1 = f10 = f25 + f26 = 34 ,
b2 = f11 = (2f5 + f6 )f6 = 55 ,
c1 = 1 , f12 = f11 + f10 = 89 ,
b1 = f11 = 55 ,
b2 = f12 = 89 .
Krok 4
b1 = f22 = f211 + f212 = 10946 ,
b2 = f23 = (2f11 + f12 )f12 = 17711 ,
c0 = 1 , f24 = f23 + f22 = 28657 ,
b1 = f23 = 17711 ,
b2 = f24 = 28657 .
Wynik f23 (= b1 ) = 17711.
Zadanie 1. Złożonośc algorytmu 2
3
Pokazać metodą indukcji słuszność algorytmu 2 znajdowania wyrazów ciągu
Fibonacciego.
[Spis]
Złożoność obliczeniowa algorytmu 2 jest rzędu log n, a więc jest dużo mniejsza od złożoności obliczeniowej algorytmu 1. Wykonanie algorytmu 2 przebiega
w l-krokach, przy czym l ≈ log2 n, a na każdym kroku wykonuje się 4 mnożenia
i 3 dodawania. Czynności wstępne polegające na znalezieniu rozwinięcia liczby n
wymagają również rzędu log2 n operacji, bo wykonuje się je znajdując reszty z l + 1
dzieleń przez dwa liczby n. Stąd liczba wszystkich operacji jest rzędu 8 log2 n Do
tego trzeba dodać działania organizacyjne związane z przezywaniem bazy itd. Złożoność algorytmu drugiego jest więc znacznie mniejsza niż pierwszego. Jedyna komplikacja, która pojawia się w algorytmie 2, polega na zwiększeniu liczby obiektów, na
których operuje algorytm. Jest to często koszt jaki należy ponieść przy zmniejszaniu
liczby operacji.
8
1.4.1. Jeszcze o złożoności. Przeszukiwanie tablic.
Rozpatrzmy problem znajdowania numeru elementu X z tablicy A[1..N]. Schemat Nassi-Schneidermana algorytmu wygląda następująco:
+-------------------------------------+
|
i:=1;
|
|-------------------------------------|
|
X <> A[i]
|
|
|
|
+-----------------------------|
|
|
i:=i+1;
|
|
|
|
+-------------------------------------|
|
Wypisz(i);
|
+-------------------------------------+
Ile razy wykonywana jest instrukcja dopóki-dopóty? Jeśli nic nie wiemy o ciągu
elementów z A to pętla wykonuje się "jakąśłiczbę razy, która zawarta jest między
zerem, a N − 1. Średnia liczba (przy dużej liczbie przebiegów programu) jest równa
(N − 1)/2 = N/2 − 1/2 ≈ N/2. Algorytm, który tu zastosowaliśmy jest liniowy.
Czas jego wykonania jest liniową funkcją N.
Załóżmy teraz, że elementy A są uporządkowane rosnąco. Algorytm przeszukiwania binarnego polega na tym, że proces przeszukiwania rozpoczynamy od porównania X z elementem środkowym tablicy. Jeśli są one jednakowe to proces kończy się. Jeśli X jest mniejszy od elementu środkowego powtarzamy przeszukiwanie
w tablicy A[1..N/2]. Jeśli X jest większy od elementu środkowego przeszukujemy
część górną: A[N/2 + 1..N]. Czynimy to aż znajdziemy numer X. Liczba połowień
jest w przybliżeniu równa log2 N. Algorytm przeszukiwania binarnego jest więc
algorytmem logarytmicznym.
Przedstawmy to w tablicy.
N
N/2
⌈log2 N⌉
10
100
1 000
10 000
100 000
1 000 000
5
50
500
5 000
50 000
500 000
4
7
10
14
17
20
Wielkość ⌈log2 N⌉ oznacza funkcję sufit, która daje wartość argumentu zaokrągloną
do najbliższej większej liczby całkowitej.
Widzimy, że dla małych N różnica czasów jest niewielka, lecz dla dużych rośnie
ona bardzo szybko. Algorytm N/2 nie ma szans przy N rzędu miliona. Złożoność
opisanych algorytmów oznaczamy przez Θ(N) oraz Θ(log N).
Zadanie 2. Grafiki złożoności
2
Narysować grafiki Θ(f(N)) dla algorytmów: stałego Θ(k), logarytmicznego
Θ(log N), liniowego Θ(N), N log N, kwadratowego Θ(N2 ), sześciennego
Θ(N3 ) i eksponencjalnego Θ(2N ) dla N=1. . . 200.
[Spis]
Przykład. Załóżmy, że mamy wybrać algorytm sortowania. Mamy do dyspozycji
algorytm A, którego czas porządkowania wynosi 5N2 µs i algorytm B, którego czas
pracy jest dany formułą: 50N log Nµs. Czynnik 50N przed logarytmem wskazuje,
że algorytm B jest bardziej skomplikowany niż A, który przed N2 ma czynnik 5.
9
Tablica
5N2 µs
50N log Nµs
10
100
1 000
10 000
100 000
1 000 000
0.0005 s
0.05 s
5s
500 s
50 000 s=14 h
5 × 106 s = 58 d
0.002 s
0.03 s
0.5 s
6.6 s
83 s
993 s=17 min
Zadanie 3. Arytmetyka Θ
2
Można udowodnić słuszność następujących reguł arytmetyki Θ:
Θ(N) + c = Θ(N) ,
Θ(cN) = Θ(N) ,
Θ(N) + Θ(M) = Θ(M) + Θ(N) ,
Θ(N) + Θ(M) = Θ(M) , M ≤ N .
W wyrażeniach poniżej wstawić w miejscu znaku ? znak >, < lub =.
1. Θ(5) ? Θ(23)
2. Θ(N + M) ? Θ(N − 15/2)
3. Θ(log N) ? Θ(N)
4. Θ(N2 + N) ? Θ(N3 )
5. Θ(N log N + N3 ) ? Θ(2N )
6. Θ(2N ) ? Θ(5N )
7. Θ(log N) ? Θ(log10 N)
[Spis]
1.4.2. I jeszcze . . . sortowanie przez wstawianie
Literatura: Cormen, Leiserson, Rivest, Wprowadzenie do algorytmów, WNT, Warszawa, 1998, wydanie II.
Rozważmy algorytm porządkowania ciągu liczb zwany sortowaniem przez wstawianie.
Problem.
Dane wejściowe: Ciąg n liczb: A =< a1 , a2 , a3 , . . . an > .
Wynik: Spermutowany ciąg < a1′ , a2′ , a3′ , . . . an′ > otrzymany z A taki, że a1′ ≤
a2′ ≤ a3′ . . . ≤ an′ .
Sortowania dokonamy za pomocą następującego algorytmu.
Sort_wstaw(A)
1 for j <- 2 to length[A]
2
do klucz <- A[j]
3
(* wstaw A[j] w posortowany ciąg A[1, 2, ... , n]
4
i <- j-1
5
while i>0 and A[i]>klucz
6
do A[i+1] <- A[i]
7
i <- i-1
8
A[i+1] <- klucz
*)
Poniższy, konkretny przykład zilustruje działanie programu.
Przykład. Niech A =< 5, 2, 4, 6, 1, 3 >. Działanie algorytmu Sort_wstaw sprowadza się do wykonania następujących kroków.
10
5
2
2
2
2
1
1
2
¯5
4
4
4
2
2
4
4
¯5
5
5
4
3
6
6
6
6
¯6
5
4
1
1
1
1
1
¯6
5
3
3
3
3
3
3
¯6
Pozycje o indeksie i zostały wyróżnione. W każdym następnym kroku algorytm
powoduje przeniesienie wyróżnionej ¯liczby w odpowiednie miejsce w ciągu.
Czas działania algorytmu zależy od liczby elementarnych operacji potrzebnych
do jego wykonania. W celu oszacowania go założymy, że czas wykonania pojedynczego wiersza algorytmu jest zawsze jednakowy i wynosi ci . Przez tj oznaczymy
liczbę sprawdzeń warunku wejścia do pętli while.
Możemy sporządzić następującą tablicę kosztów.
Instrukcja (wiersz)
Koszt
Liczba wykonań
1
2
3
4
5
6
7
8
c1
c2
c3 = 0
c4
c5
c6
c7
c8
n
n−1
n−1
n−1
Pn
tj
Pj=2
n
(t
j − 1)
Pj=2
n
j=2 (tj − 1)
n−1
for j <- 2 to length[A]
do klucz <- A[j]
(* ... *)
i <- j-1
while i>0 and A[i]>klucz
do A[i+1] <- A[i]
i <- i-1
A[i+1] <- klucz
Czas działania całego algorytmu jest sumą czasów cząstkowych.
Θ(n)
= c1 n + c2 (n − 1) + 0(n − 1) + c4 (n − 1) + c5
n
X
tj
j=2
+c6
n
X
(tj − 1) + c7
j=2
n
X
(tj − 1) + c8 (n − 1) .
j=2
Oszacujmy minimalny czas działania algorytmu. Dzieje się to w przypadku posortowanego ciągu A. Dla każdego j = 2, 3, . . . , n w wierszu 5 mamy wtedy A[i] ≤
klucz dla każdego początkowego i równego j − 1. Zatem tj = 1 dla j = 2, 3, . . . , n
i minimalny czas działania jest równy
Θ(n) =
c1 n + c2 (n − 1) + c4 (n − 1) + c5 (n − 1) + c8 (n − 1)
=
(c1 + c2 + c4 + c5 + c8 )n − (c2 + c + c4 + c5 + c8 )
=
an + b ,
gdzie a i b są stałymi. Widzimy, że Θ(n) jest liniową funkcją n, liczby elementów
ciągu.
Najgorsza sytuacja ma miejsce gdy tablica jest posortowana odwrotnie. Musimy
wtedy porównać każdy element A[j] tablicy z elementami podtablicy A[1 . . . j − 1],
a więc tj = j dla j = 2, 3, . . . , n. Ponieważ
n
X
j = n(n + 1)/2 − 1 ,
j=2
n
X
(j − 1) = n(n − 1)/2 ,
j=2
11
więc
Θ(n) =
c1 n + c2 (n − 1) + c4 (n − 1) + c5 [n(n + 1) − 1]
+c6 [n(n − 1)/2] + c7 [n(n − 1)/2 + c8 (n − 1)
=
1/2(c5 + c6 + c7 )n2
+(c1 + c2 + c4 + c5 /2 − c6 /2 + c7 /2 + c8 )n − (c2 + c4 + c5 + c8 )
=
an2 + bn + c .
Tym razem otrzymaliśmy funkcję kwadratową względem n.
W realnych przypadkach czas wykonania algorytmu leży gdzieś pomiędzy czasem optymistycznym i pesymistycznym. Jest on najczęściej zbliżony do czasu pesymistycznego.
Odrzucając w Θ(n) wszystkie człony oprócz wiodącego otrzymamy to co nazywamy złożonością algorytmu. Dla naszego przypadku mamy więc złożoność Θ(n2 ).
1.4.3. . . . sortowanie przez scalanie
W przypadku sortowania przez wstawianie stosowaliśmy metodę przyrostową:
mając posortowaną tablicę A[1 . . . j − 1] wstawialiśmy pojedynczy element A[j] we
właściwe miejsce otrzymując większą tablicę A[1...j].
Rozpatrzymy teraz inną metodę zwaną dziel i zwyciężaj. Algorytmy, które stosują tę metodę mają najczęściej strukturę rekurencyjną. W metodzie tej problem
dzielony jest na mniejsze problemy podobne do poprzedniego, problemy te są rozwiązywane rekurencyjnie, a następnie ich rozwiązania są łączone w rozwiązanie
pełnego problemu.
Opis algorytmu sortowania przez scalanie jest następujący.
— Dzielimy ciąg n elementowy na dwa podciągi o n/2 elementach każdy (DZIEL).
— Sortujemy je rekurencyjnie przez scalanie (ZWYCIĘŻAJ).
— Łączymy posortowane podciągi w jeden posortowany ciąg (POŁĄCZ).
W kroku trzecim potrzebna będzie procedura, która łączy dwa podciągi posortowane A[p . . . q] i A[q + 1 . . . r] w jeden A[p . . . r]. Nazwiemy ją Merge. Jej algorytm
wygląda tak
Merge(A, p, q, r)
1 i <- p;
j <- q+1; (* wskaźniki do el A *)
2 while i<= q or j <= r
3
do
4
if C <= A[j]
5
i <- i+1
6
else przesuń(A, i, j)
7
A[i] <- C
8
i <- i+1
9
j <- j+1
gdzie przesun(A,i,j) przemieszcza elementy części tablicy A[i..j-1] w prawo o 1
miejsce. W powstałą lukę wstawiana jest następnie zapamiętana wcześniej wartość
C (niszczona w procesie przesuwania). Np.
for l:=j downto i+1 do A[l]:=A[l-1]
.
A oto dpowiedni program w Pascalu.
procedure Merge(var A: List; p, q, r: integer);
(*
Sklada dwie uporzadkowane czesci tablicy A
w jedna uporzadkowana calosc;
A[p..q] -lewa; A[q+1..r] - prawa
*)
12
var i, j, l: integer;
C: integer;
begin
i:=p;
(* wskaznik do czesci lewej *)
j:=q+1;
(* wskaznik do czesci prawej *)
while (i <= p) or (j <= r) do begin
C := A[j];
if A[i] <= C then begin
i := i+1;
end
else begin
(* przesun w prawo o 1 poczynajac od i *)
for l:=j downto i+1 do A[l]:=A[l-1];
A[i]:=C;
i:=i+1;
j:=j+1;
end;
end;
end;
Procedura Merge działa w miejscu, tzn korzysta tylko z tablicy A. Dlatego potrzebujemy przesuwania, które zajmuje sporo (!) czasu obliczeń. Efektywnywniejszy czasowo, ale rozbudowany algorytm otrzymamy jeśli wyniki scalania będziemy
umieszczać w posredniej tablicy B.
procedure Merge(var A, B: List; p, q, r: integer);
(*
Sklada dwie uporzadkowane czesci tablicy A
w jedna uporzadkowana calosc B[p..r];
A[p..q] - lewa; A[q+1..r] - prawa
*)
var i, j, k: integer;
begin
i:=p;
(* wskaznik do czesci lewej *)
j:=q+1;
(* wskaznik do czesci prawej *)
k:=1;
(* wskaznik do el. tablicy B *)
while (i <= q) and (j <= r ) do begin
if A[i] < A[j] then begin
B[k]:=A[i];
i := i+1;
end
else begin
B[k] := A[j];
j:=j+1;
end;
k:=k+1;
end;
(* Kopiowanie uporzadkowanej reszty tablicy A *)
if i > q then (* wyczerpano liste z lewej; przepisuj prawa czesc *)
repeat
B[k] := A[j];
j := j+1;
k := k+1;
until k>r
else
13
repeat
B[k] := A[i];
i := i+1;
k := k+1;
until k>q;
end;
Następną procedurą jest Merge_Sort(A, p, r). Procedura ta sortuje elementy w
podtablicy A[p . . . q]. Kiedy p ≥ r podciąg jest posortowany. W przeciwnym razie
znajdujemy q, które dzieli ją na dwie podtablice A[p . . . q] o ⌈n/2⌉ elementach i
drugą A[q + 1 . . . r] o ⌊n/2⌋ elementach.3
Merge_Sort(A, p, r)
1 if p<r
2
then q -> floor(p+r)/2
3
Merge_Sort(A, p, q)
4
Merge_Sort(A, q+1, r)
5
Merge(A, p, q, r)
W celu posortowania ciągu A =< A[1], A[2], . . . , A[n] > należy wywołać procedurę Merge_Sort(A, 1, length(A)) gdzie length(A) oznacza długość A i wynosi n.
Drzewo sortowań (przypadek n = 2m , gdzie m=3) pokazane jest na rysunku.
CIAG KONCOWY
1 2 2 3 4 5 6 6
scalanie
2
2 4 5 6
1 2 3 6
scalanie
scalanie
5
scalanie
5
2
4
1
6
scalanie
4
3
2
scalanie
6
1
3
6
scalanie
2
6
CIAG POCZATKOWY
1.4.4. Złożoność algorytmu sortowania przez scalanie
Algorytm sortowania przez scalanie jest algorytmem rekurencyjnym. Jego czas
działania można więc zapisać jako rekurencyjną zależność zawierającą czas realizacji
podproblemów mniejszych.
Jeśli problem został podzielony na a mniejszych podproblemów o rozmiarach
nn/b każdy to czas jego wykonania jest dany zależnością
Θ(1)
dla n ≤ c
T (n) =
aT (n/b) + D(n) + S(n) dla n > c
Tutaj Θ(1) jest w przybliżeniu stałym czasem wykonania elementarnego podproblemu o rozmiarze n ≤ c, D(n) jest czasem dzielenia problemu, a S(n) jest czsem
scalania podproblemów.
Dla algorytmu Sort (przy założeniu, że n = 2m ) mamy D(n) = Θ(1), S(n) =
Θ(n), a T (n) = Θ(1) dla n = 1 oraz T (n) = Θ(n/2) + Θ(n) dla n > 1. Można
pokazać, że rozwiązaniem tego problemu rekurencji jest
T (n) = Θ(n log2 n) .
Ponieważ algorytm sortowania przez wstawianie ma czas pesymistyczny Θ(n2 ),
wiąc widzimy, że algorytm sortowania przez scalanie jest szybszy gdyż
Θ(n log2 n) < Θ(n2 ) .
3 Wielkość ⌈x⌉ oznacza najmniejszą liczbę całkowitą nie mniejszą niż x (ceiling(x) lub
sufit(x)), a ⌊x⌋ oznacza największą liczbę całkowitą nie większą niż x (floor(x) lub podłoga(x)).
14
Koniec.
Zadanie 4. Złożoność rekurencji
3
Pokazać stosując indukcję matematyczną, że rozwiązaniem równania rekurencyjnego
Θ(1)
dla n = 2
T (n) =
2T (n/2) + n dla n = 2m , m > 1 ,
jest T (n) = n log2 n.
[Odp.][Spis]
Zadanie 5. Złożoność sortowania przez wstawianie
3
Napisz równanie rekurencyjne na czas sortowania przez wstawianie.
[Spis]
Zadanie 6. Porównanie złożoności
1
Jaka jest najmniejsza wartość n, dla której algorytm wykonujący 100n2 operacji
działa szybciej niż algorytm wykonujący 2n operacji na tym samym komputerze?
[Spis]
Problem.
Dla funkcji f(n) i czasu t z poniższej tabeli wyznacz największy rozmiar n problemu, który może być rozwiązany w czasie t, zakładając, że algorytm działa w
czasie f(n)µsekund.
f\t
log2 n
√
n
n
n log2 n
n2
n3
2n
n!
1 sec
?
?
?
?
?
?
?
?
1 min
?
?
?
?
?
?
?
?
1 godz
?
?
?
?
?
?
?
?
1 dzień
?
?
?
?
?
?
?
?
15
1 miesiąc
?
?
?
?
?
?
?
?
1 rok
?
?
?
?
?
?
?
?
1 wiek
?
?
?
?
?
?
?
?