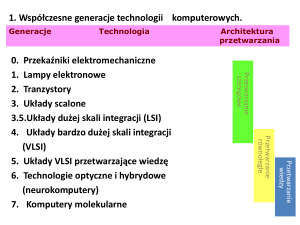
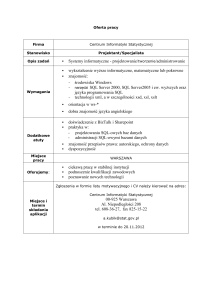
Rozdział monografii: 'Bazy Danych: Modele, Technologie, Narzędzia', Kozielski S., Małysiak B., Kasprowski P., Mrozek D. (red.), WKŁ 2005
Rozdział 9
Rozmyta agregacja danych w pytaniach SQL
w
w
w
Streszczenie. W rozdziale przedstawiono analizę występowania wartości
rozmytych we frazie HAVING, wyznaczanie wartości funkcji agregujących
dla danych nieprecyzyjnych. Zaprezentowano możliwość zastosowania w pytaniach sformułowanych w sposób nieprecyzyjny rozmytych kwantyfikatorów (pełniących rolę lingwistycznych funkcji agregujących) oraz obliczanie
stopnia zgodności tak sformułowanych warunków rozmytych. Każdy z wyodrębnionych przypadków został zilustrowany konkretnym przykładem.
1 Wprowadzenie
da
.b
Pytania, które użytkownik kieruje do bazy danych, są przez niego w pierwotnej postaci
formułowane w języku naturalnym. Można się więc spodziewać w takich pytaniach określeń nieprecyzyjnych lub nie mających swoich odpowiedników w języku SQL (stanowiącym obecnie standardowy język zapytań w bazach danych [3], [11].
Rozszerzenie języka SQL przez wprowadzenie elementów teorii zbiorów rozmytych,
umożliwi użytkownikowi konstruowanie zapytań zawierających niedokładne lub nieprecyzyjnie podane warunki. Warunki pytania, formułowane przez użytkownika, przekładają się
zwykle na warunki filtrujące i te właśnie powinny zostać poddane szczegółowej analizie.
Biorąc pod uwagę miejsca występowania warunków filtrujących w instrukcji SELECT
języka SQL, warunki te mogą być podzielone na [10], [11]:
− występujące we frazie WHERE (operujące na poszczególnych wierszach),
− występujące we frazie HAVING (operujące na wyodrębnionych we frazie GROUP
BY grupach wierszy).
Poza wymienionymi powyżej frazami, wartości nieprecyzyjne mogą występować również w klauzulach SELECT, GROUP BY, ORDER BY instrukcji SELECT.
Analiza występowania wartości nieprecyzyjnych (rozmytych) w warunkach filtrujących
we frazie WHERE oraz wyznaczanie stopnia zgodności tak skonstruowanego warunku
zostały przedstawione w artykułach [4], [5], [6], [7], [8].
W tym rozdziale natomiast zostanie przedstawiona analiza występowania wartości rozmytych we frazie HAVING, tworzenie rozmytych funkcji agregujących, rozmytych kwantyfikatorów lingwistycznych oraz wyznaczanie stopnia zgodności tak sformułowanych warunków.
Prezentowane w dalszej części rozdziału pytania, konstruowane w języku SQL, odnoszą
się do przykładowej bazy danych ZAKŁADY. W skład bazy danych ZAKŁADY wchodzą
między innymi następujące tabele:
pl
s.
Dariusz Mrozek, Bożena Małysiak: Politechnika Śląska, Instytut Informatyki,
ul. Akademicka 16, 44-100 Gliwice, Polska
email:{mrozek, malysiak}@polsl.pl
(c) Copyright by Politechnika Śląska, Instytut Informatyki, Gliwice 2005
Rozdział monografii: 'Bazy Danych: Modele, Technologie, Narzędzia', Kozielski S., Małysiak B., Kasprowski P., Mrozek D. (red.), WKŁ 2005
D. Mrozek, B. Małysiak
Instytuty (nr_inst, nazwa),
Zaklady (nr_zakl, nazwa, liczba_prac, liczba_pokoi, nr_inst),
Pracownicy (nr_prac, imie, nazwisko, wiek, plec, staz_pracy, nr_zakl),
Zapotrzebowanie (nr_zakl, rok, papier, toner, plytki_CD),
Zuzycie (nr_zakl, rok, papier, toner, plytki_CD),
w
Nazwy kolumn wchodzących w skład kluczy głównych w tabelach zostały podkreślone,
natomiast nazwy kolumn zawierających wartości rozmyte pogrubione.
Przechowywane w tabeli zapotrzebowanie dane dotyczą szacowanych (planowanych)
potrzeb na dany rok. W przedstawionych, w kolejnych podrozdziałach, przykładach rozpatrywane warunki rozmyte będą dla wyróżnienia pogrubione.
Schemat bazy danych ZAKŁADY przedstawiony jest na diagramie (rys. 1).
instytuty
w
nr_inst : Integer
nazwa : String
1
w
zapotrzebowanie
papier : ftrapezium
toner : ftrapezium
plytki_CD : ftrapezium
nr_zakl : Integer
rok : Date
+należy
0..*
+z amawia
0..*
1
zaklady
nazwa : String
liczba_prac : Integer
liczba_pokoi : Integer
nr_zakl : Integer
nr_inst : Integer
+zatrudnia
1
0.. *
da
.b
pracownicy
imie : String
nazwisko : String
plec : String
wiek : Integer
nr_zakl : Integer
staz_pracy : Integer
nr_prac : Integer
1
+zuż ywa
0..*
zuzycie
papier : Int eger
t oner : Integer
plyt ki_CD : Integer
nr_zakl : Int eger
rok : Date
Rys. 1. Schemat bazy danych ZAKŁADY
pl
s.
2 Funkcje agregujące na danych rozmytych
W języku SQL możliwy jest podział wierszy w tabeli na grupy i obliczenie wartości funkcji
agregujących w ramach poszczególnych grup. Do wyodrębnienia grup wierszy służy klauzula GROUP BY, po której wypisuje się nazwy kolumn, których jednakowe wartości wyznaczają kolejne grupy wierszy. Tak jak na pojedyncze wiersze w tabeli można nałożyć
warunki we frazie WHERE, tak i na wyodrębnione grupy można również nakładać warunki.
W tym celu stosuje się klauzulę HAVING, w której wyszukiwane dane mogą zostać przetworzone przy użyciu dostępnych funkcji agregujących [12].
Obliczenie wartości funkcji agregujących, np.: SUM, AVERAGE, MIN, MAX operujących na danych rozmytych, wymaga znajomości arytmetyki liczb rozmytych, czyli operacji, takich jak dodawanie, wyznaczanie wartości najmniejszej czy największej spośród liczb
rozmytych [2], [9], [13]. W rozdziale założono, że liczby rozmyte są typu L-R [2], [9], [13].
Funkcja agregująca COUNT zawsze zwraca liczbę analizowanych wartości, więc obliczona
wartość jest zawsze liczbą ostrą (dokładną).
78
(c) Copyright by Politechnika Śląska, Instytut Informatyki, Gliwice 2005
Rozdział monografii: 'Bazy Danych: Modele, Technologie, Narzędzia', Kozielski S., Małysiak B., Kasprowski P., Mrozek D. (red.), WKŁ 2005
Rozmyta agregacja danych w pytaniach SQL
Przykładowe pytanie kierowane do bazy danych ZAKŁADY (której strukturę przedstawiono we wprowadzeniu) może brzmieć następująco:
„Wyznacz wartość średniego zapotrzebowania na tonery w roku 2002.”
Postać tego pytania zapisana w języku SQL jest następująca:
SELECT AVG(toner)
FROM zapotrzebowanie
WHERE rok = ‘2002’;
w
Zaimplementowane funkcje agregujące działające na rozmytych danych mają takie same
nazwy jak klasyczne funkcje agregujące, różnią się natomiast typem argumentu i na tej
podstawie jest uruchamiana odpowiednia autorska funkcja agregująca operująca na rozmytych danych lub klasyczna funkcja agregująca operująca na dokładnych danych.
w
3 Nakładanie warunków na funkcje agregujące w pytaniach
rozmytych
w
da
.b
Wartości rozmyte mogą występować również w zapisie warunków filtrujących we frazie
HAVING, gdzie warunki te są nakładane na funkcje agregujące i ten przypadek został
szczególnie dokładnie przeanalizowany.
W tego typu pytaniach rozmytych można wyróżnić kilka rodzajów agregacji danych [4]:
− agregacja wartości ostrych, a nakładany warunek jest rozmyty,
− agregacja wartości rozmytych, a nakładany warunek jest ostry,
− agregacja wartości rozmytych i nakładany warunek jest rozmyty,
− rozmyte kwantyfikatory operujące na grupie wierszy.
Nowym problemem jest agregacja wykonywana dla kolumn zawierających rozmyte dane. Proces wyznaczania stopnia zgodności z kryteriami warunku przebiega tak samo, jak
w przypadku warunku we frazie WHERE [4], [5], [6], [14], tzn. po pierwsze dla każdego
warunku rozmytego jest wyznaczany jego stopień zgodności. Następnie w przypadku warunków złożonych, w zależności od łączących je operatorów, należy zastosować odpowiednią s-normę lub t-normę [2], [9], [13] i obliczyć całkowity stopień zgodności.
W kolejnych podrozdziałach zostaną rozpatrzone wymienione powyżej przypadki agregacji danych w warunkach rozmytych.
pl
s.
3.1 Agregacja wartości ostrych − nakładany warunek rozmyty
Wszystkie prowadzone dotychczas rozważania dotyczące wyznaczania stopni zgodności
między wartością dokładną a wartością rozmytą, dotyczące frazy WHERE, we frazie
HAVING są podobne [4], [5], [6].
Przykładowe pytanie kierowane do bazy danych ZAKŁADY może brzmieć następująco:
„Wyszukaj te zakłady, w których jest zatrudnionych około 10 kobiet, przy czym stopień
zgodności z tym warunkiem powinien być większy od 0,65.”
Pytanie to zapisane w języku SQL w formie operatorowej [5], [6] może mieć następującą postać:
SELECT nr_zakl
FROM pracownicy
WHERE plec = ’K’
GROUP BY nr_zakl
HAVING (count(nr_prac) jest okolo 10) > 0.65;
79
(c) Copyright by Politechnika Śląska, Instytut Informatyki, Gliwice 2005
Rozdział monografii: 'Bazy Danych: Modele, Technologie, Narzędzia', Kozielski S., Małysiak B., Kasprowski P., Mrozek D. (red.), WKŁ 2005
D. Mrozek, B. Małysiak
Proces wyboru grup do wyniku jest wykonywany w typowy sposób. Dla bieżącej grupy
wierszy jest wyznaczany stopień zgodności wartości funkcji agregującej count(nr_prac)
z wartością rozmytą okolo 10. W odpowiedzi pojawią się te grupy, dla których warunek
wyszczególniony we frazie HAVING jest spełniony ze stopniem zgodności przekraczającym 0,65.
w
3.2 Agregacja wartości rozmytych
w
w
Zadanie wyszukiwania w przypadkach, w których jest niezbędne wykonanie agregacji na
wartościach rozmytych, jest realizowane w ten sam sposób, jak w pytaniu omawianym
w poprzednim punkcie z tą różnicą, że w pytaniach tych jest niezbędne wyznaczenie wartości funkcji agregujących: SUM, AVERAGE, MIN, MAX operujących na wartościach rozmytych.
Przykładowe pytanie kierowane do bazy danych ZAKŁADY może brzmieć następująco:
„Wyszukaj te instytuty, których sumaryczne roczne zapotrzebowanie na papier wynosiło
około 1000 ryz. W odpowiedzi powinny znaleźć się wiersze o stopniu zgodności co najmniej
0,7.”
Pytanie to zapisane w języku SQL w formie operatorowej [5], [6] może mieć następującą postać:
da
.b
SELECT i.nr_inst, rok, sum(papier)
FROM zapotrzebowanie z JOIN zaklady zk ON z.nr_zakl=zk.nr_zakl
JOIN instytuty i ON zk.nr_inst = i.nr_inst
GROUP BY i.nr_inst, rok
HAVING (sum(papier)jest okolo 1000) >= 0.7;
W przedstawionym przykładzie zastosowano funkcję agregującą SUM, której argumentem są wartości typu rozmytego. Proces wyboru grup do wyniku wykonywany jest w typowy sposób (omówiony w poprzednim punkcie), w odpowiedzi pojawią się te grupy, dla
których warunek wyszczególniony we frazie HAVING jest spełniony ze stopniem zgodności większym bądź równym 0,7.
3.3 Rozmyty warunek filtrujący we frazie WHERE i agregacja we frazie HAVING
pl
s.
W przypadku, gdy warunki filtrujące są nakładane na kolumny zarówno we frazie WHERE,
jak i we frazie HAVING, zadanie wyszukiwania jest realizowane w ten sam sposób jak
w poprzednich przykładach, z tą różnicą, że w tego typu pytaniach, po wybraniu wierszy
spełniających warunki filtrujące we frazie WHERE, wyodrębniane są grupy wierszy, na
które nakładane są warunki wyspecyfikowane we frazie HAVING.
W tego typu pytaniach dwa razy są wyznaczane stopnie zgodności, najpierw dla poszczególnych wierszy, później dla grup zawierających już tylko te wiersze, które zostały
wyodrębnione w pierwszym procesie wyboru wierszy.
Rozpatrzmy następujące pytanie, kierowane do bazy danych ZAKŁADY:
„Wyszukaj nazwy tych zakładów, które w roku 2003 złożyły zapotrzebowanie na około
100 płytek CD oraz ich maksymalne zużycie płytek CD wynosiło około 120. W odpowiedzi
powinny się znaleźć wiersze, które spełniają podane kryteria ze stopniem zgodności nie
mniejszym niż 0,8.”
Pytanie to zapisane w języku SQL w formie operatorowej [5], [6] może mieć następującą postać:
80
(c) Copyright by Politechnika Śląska, Instytut Informatyki, Gliwice 2005
Rozdział monografii: 'Bazy Danych: Modele, Technologie, Narzędzia', Kozielski S., Małysiak B., Kasprowski P., Mrozek D. (red.), WKŁ 2005
Rozmyta agregacja danych w pytaniach SQL
SELECT z.nr_zakl, nazwa
FROM zaklady z JOIN zapotrzebowanie zp
ON z.nr_zakl = zp.nr_zakl
JOIN zuzycie zu ON zp.nr_zakl = zu.nr.zakl
WHERE zp.rok =’2003’ AND (zp.plytki_CD jest okolo 100) >= 0.8
GROUP BY z.nr_zakl, nazwa
HAVING (max(zu.plytki_CD) jest okolo 120) >= 0.8;
w
W procesie interpretacji powyższego pytania należy zwrócić uwagę na następujące etapy:
− najpierw na etapie filtracji (wykonanie frazy WHERE) są wybierane wiersze spełniające warunek dokładny (dotyczący roku 2003) i dla tych wierszy jest wyznaczany
stopień zgodności dla warunku rozmytego: (zp.plytki_CD jest okolo 100),
− następnie wiersze, dla których stopień zgodności nie jest mniejszy niż 0,8 podlegają
grupowaniu,
− kolejno dla grup we frazie HAVING wyznaczona jest wartość maksymalna i po raz
drugi jest obliczany stopień zgodności, tym razem dotyczący tej wartości,
− z grup, dla których ten stopień zgodności spełnia warunek (nie mniejszy niż 0,8), jest
tworzony wynik.
w
w
4 Rozmyte kwantyfikatory (rozmyte lingwistyczne funkcje agregujące)
da
.b
W języku naturalnym często używa się sformułowań: prawie wszystkie, prawie żaden,
około połowa itd., dopuszczających niepewność. Wszystkie te stwierdzenia odnoszą się do
pewnej analizowanej grupy obiektów.
Określenia te mogą pełnić rolę rozmytych kwantyfikatorów, co umożliwia formułowanie
zapytań typu: „Wyszukaj dane o zakładach, w których prawie wszyscy pracownicy to mężczyźni.” lub „Wyszukaj zakłady, w których około połowa pracowników ma mniej niż 35
lat.”
Należy zauważyć, że bezwzględne wartości (liczby pracowników) spełniające kryteria
pytania są w każdym przypadku inne. Można jednak w prosty sposób unormować takie
wyniki wyznaczając iloraz:
Card (G ( warunek ))
Card (G )
pl
s.
o=
(1)
gdzie:
G − oznacza grupę wierszy G o liczności card(G) (np. pracowników zakładu i),
G((warunek)) − oznacza wiersze grupy G spełniające warunek (np. pracownicy zakładu
i młodsi od 35 lat).
Powyższy iloraz (wzór 1) oznacza więc odsetek wierszy w grupie spełniających warunki
pytania. Można zauważyć, że zachodzi 0 ≤ o ≤ 1.
Należy zwrócić uwagę, że określenia: prawie wszyscy, około połowa, prawie żaden
można potraktować jako tzw. wartości lingwistyczne, tzn. wartości rozmyte [1], [2], [9],
[13]. Powstaje wtedy problem zdefiniowania funkcji przynależności [2], [9], [13] dla takich
wartości. Jeśli argumentem funkcji przynależności byłyby liczby bezwzględne (np. liczba
mężczyzn, czy liczba pracowników młodszych niż 35 lat), to funkcja ta miałaby zastosowanie w jednym konkretnym pytaniu, zaś ogólnie byłaby bezużyteczna.
Zauważono jednak, że zdefiniowanie takiej funkcji na przedziale [0, 1] (lub inaczej
w procentach) pozwala skojarzyć (porównać) taką funkcję przynależności z funkcją odse81
(c) Copyright by Politechnika Śląska, Instytut Informatyki, Gliwice 2005
Rozdział monografii: 'Bazy Danych: Modele, Technologie, Narzędzia', Kozielski S., Małysiak B., Kasprowski P., Mrozek D. (red.), WKŁ 2005
D. Mrozek, B. Małysiak
tek. Można wtedy wyznaczyć stopień „spełnienia” danego kwantyfikatora (np. prawie
wszyscy) [1], [2], [13], czyli inaczej – stopień zgodności warunku z kryteriami pytania.
Przyjęto na przykład funkcję przynależności dla wartości lingwistycznej prawie wszyscy
jak na rys. 2.
µ
w
1
w
0
0.9
0.95
1
X
Rys. 2. Funkcja przynależności dla wartości lingwistycznej prawie wszyscy
w
da
.b
Rozważono ponownie pytanie:
„Wyszukaj te zakłady, w których prawie wszyscy pracownicy to mężczyźni.
W odpowiedzi powinny znaleźć się wiersze o stopniu zgodności co najmniej 0,7.”
Postać tego pytania zapisana w języku SQL może być wyrażona następująco:
SELECT nr_zakl, prawie_wszystkie(plec = ‘M’)
FROM pracownicy
GROUP BY nr_zakl
HAVING prawie_wszystkie(plec = ‘M’) >= 0.7;
Założono, że dla zakładu numer 1 wartość funkcji odsetek wyniosła 0,925. Wtedy
z wykresu funkcji przynależności odczytać można (rys. 3), że wartość stopnia zgodności
wynosi w tym przypadku 0,5. Tak więc zakład numer 1 nie spełnia warunku na stopień
zgodności i nie zostanie włączony do zbioru wynikowego.
pl
s.
Na koniec można zauważyć, że wartość lingwistyczna prawie wszyscy, którą na początku tego rozdziału określono jako kwantyfikator rozmyty, zajmuje w zapisie pytania w języku SQL miejsce funkcji agregującej. Stąd też wartości tego typu (również okolo_polowa,
prawie_zaden) można określać jako lingwistyczne funkcje agregujące.
µ
1
0.5
0
0.9 0.925
1
X
Rys. 3. Stopień zgodności (0,5) obliczonego odsetka (0,925) z wartością lingwistyczną
prawie_wszystkie
82
(c) Copyright by Politechnika Śląska, Instytut Informatyki, Gliwice 2005
Rozdział monografii: 'Bazy Danych: Modele, Technologie, Narzędzia', Kozielski S., Małysiak B., Kasprowski P., Mrozek D. (red.), WKŁ 2005
Rozmyta agregacja danych w pytaniach SQL
3 Podsumowanie
w
W rozdziale przedstawiono proces wykonywania zapytań rozmytych, w których zastosowano agregację danych. Agregowane dane w zależności od pytania przyjmowały zarówno
ostre (dokładne), jak i rozmyte wartości. Podobnie kryterium pytania było formułowane
zarówno w formie ostrej (dokładnej), jak i rozmytej. Każdy z przypadków został poparty
przykładowym pytaniem SQL.
Zaprezentowane zostało również autorskie rozwiązanie, pozwalające na zastosowanie
w pytaniach SQL kwantyfikatorów rozmytych typu: prawie wszyscy, około połowa, prawie
żaden. Ze względu na ich miejsce występowania w rozmytym pytaniu SQL, określono je
mianem lingwistycznych funkcji agregujących.
Wymiernym rezultatem przedstawionych rozwiązań jest możliwość agregowania danych
podanych w sposób nieprecyzyjny, wyznaczania wartości rozmytych warunków występujących we frazie HAVING oraz uzyskiwania odpowiedzi na pytania, w których pojawiają się
kwantyfikatory rozmyte.
w
w
Literatura
2.
3.
4.
5.
6.
7.
9.
10.
11.
12.
13.
14.
pl
s.
8.
Czogała E., Łęski J.: Fuzzy and neuro-fuzzy intelligent systems. Heiderbrg: New York: PhisicalVerlag, 2000.
Łachwa A.: Rozmyty świat zbiorów, liczb, relacji, faktów, reguł i decyzji. Akademicka Oficyna
Wydawnicza Exit, Warszawa 2001.
Elmasri R., Navathe S. B.: Fundamentals of Database Sytems. Addison-Wesley Publishing
Company, World Student Series. 2000.
Małysiak B.: Wartości rozmyte w pytaniach SQL do baz danych. Studia Informatica, Vol. 24, nr
2A (53). Szczyrk 2003.
Małysiak B: Interpretacja rozmytych warunków filtrujących w zapytaniach SQL. Studia Informatica, Vol.25, nr 2(58). Gliwice 2004.
Małysiak B.: Uzupełnianie zapytań SQL o stopień zgodności kryterium wyboru. Studia Informatica, Vol.25, nr 2(58). Gliwice 2004.
Małysiak B.: Mechanizmy wnioskowania przybliżonego w bazach danych. Studia Informatica,
Vol. 23, nr 4(51). Gliwice 2002.
Małysiak B.: Aproksymacyjne zapytania do baz danych. Studia Informatica, Vol. 23, nr 4 (51).
Gliwice 2002.
Piegat A.: Modelowanie i sterowanie rozmyte. Akademicka Oficyna Wydawnicza Exit, Warszawa 1999.
Ullman J. D.: Database and knowledge-base systems. Computer Science Press, 1988.
Ullman J. D., Widom Z.: Podstawowy wykład z systemów baz danych. WNT, Warszawa 2000.
SQL Język Relacyjnych Baz Danych. Wellesley Software. WNT, Warszawa 1995.
Yager R, Filev D.: Podstawy modelowania i sterowania rozmytego. WNT, Warszawa 1995.
Yu C.T., Meng W.: Principles of Database Query Processing for Advanced Applications. Morgan Kaufmann Publishers, Inc., 1998.
da
.b
1.
83
(c) Copyright by Politechnika Śląska, Instytut Informatyki, Gliwice 2005
Rozdział monografii: 'Bazy Danych: Modele, Technologie, Narzędzia', Kozielski S., Małysiak B., Kasprowski P., Mrozek D. (red.), WKŁ 2005
w
da
.b
w
w
pl
s.
(c) Copyright by Politechnika Śląska, Instytut Informatyki, Gliwice 2005