1
Baza danych jest modelem pewnej rzeczywistości,
tą rzeczywistość realną nazywamy obszarem
analizy.
Istotne obiekty analizy:
bloki przedmiotowe- moduły
studenci
Istotne obiekty analizy nazywamy klasami lub
encjami. Związki, które zachodzą między klasami
(encjami) są częścią obszaru analizy. Każda klasa
posiada właściwości (atrybuty).
Mówimy, że klasy są zidentyfikowane poprzez
pewne informacje przechowywane na temat
obiektów tej klasy, np.: student identyfikowany jest
poprzez nazwisko, imię, numer albumu.
Baza danych jest zbiorem danych
reprezentujących pewien obszar analizy. Jednostka
danych (lub potocznie dana) jest symbolem lub
zbiorem symboli reprezentujących jakiś fakt, jakąś
rzecz. Aby fakt był użyteczny musi zostać
zinterpretowany. Zinterpretowane dane nazywa się
często informacjami. Informacje mają przypisane
znaczenie, np.: liczba 23 może oznaczać wiek,
numer albumu; bez interpretacji nie wiemy co ona
oznacza. Mówimy, że baza danych jest zbiorem
faktów (pozytywnych) o pewnym obszarze analizy.
Baza danych, w ściśle określonej chwili, jest w
pewnym stanie, czyli jest to zbiór faktów
dotyczących bazy, zbiór faktów prawdziwych w
danej chwili.
Baza zawiera dwa podstawowe elementy:
- zbiór definicji opisujących strukturę – schemat
bazy danych tworzenie schematu – projekt bazy
lub projektowaniem bazy
- łączny – całkowity zbiór danych w bazie danych.
Integralność oznacza, że baza jest dokładnym
odbiciem swojego obszaru analizy.
Proces integralności powinien zapewnić przejście
zmianę bazy danych poprzez stany poprawne.
Integralna baza nie powinna posiadać
powtarzających się faktów lub przejść, czyli nie
powinna posiadać replikacji
Transakcje są to zdarzenia powodujące zmianę
stanu bazy danych.
Integralność jest realizowana poprzez więzy
integralności - reguły określające w jaki sposób
baza ma pozostać dokładnym odbiciem swojego
obszaru analizy.
Więzy dzielimy na:
- więzy statyczne (niezmienniki stanu)- są
używane do sprawdzania czy wykonywana
transakcja nie zmienia stanu bazy w stan
niepoprawny.
- więzy przejść- są to reguły wiążące ze sobą stany
bazy. Więzy przejść są ograniczeniami
nakładanymi na same przejścia.
Podstawowe funkcje bazy danych
Do wykonywania operacji na bazie używamy
dwóch rodzajów funkcji:
- funkcje aktualizujące – dokonują one fizycznie
zmiany w bazie – np. zaliczamy transakcje
zmieniające bazę z jednego stanu w drugi , wiąże
się z nimi ciąg warunków reprezentujących więzy
integralności oraz ciąg akcji określających co
powinno się zdarzyć, jeżeli warunki będą
prawdziwe.
- funkcje zapytań – za ich pomocą wydobywa się
dane z bazy danych - nie modyfikują samej bazy,
głównie sprawdzają czy fakt lub grupa faktów jest
spełniona w danym stanie bazy danych. Funkcje te
zwracają nie określenie czy zachodzi prawda lub
fałsz, ale zwracają pewien zbiór wartości.
Każdy system bazy danych, używa pewnych
formalizmów nazywanych modelem danych,
inaczej są to ściśle określone reguły za pomocą,
których można konstruować system bazy danych.
Baza danych może być używana przez jednego
użytkownika, jednak często baza danych jest
wielodostępna. Ważne jest zachowanie spójności
bazy danych, żeby nie zawiodła w przypadku, gdy
korzysta z niej dwóch użytkowników.
Bazą danych nazywamy zbiór danych o określonej
strukturze zapisany na zewnętrznym nośniku
pamięci komputera mogącym zaspokoić potrzeby
wielu użytkowników korzystających z niego w
sposób selektywny w dogodnym dla siebie czasie.
Baza danych jest to zbiór danych zorganizowanych
przez system zarządzania bazą danych
System zarządzania bazą danych SZBD
SZBD DBMS
DBMS – DATABASE MANAGEMENT
SYSTEM
SZBD – zorganizowany zbiór narzędzi
umożliwiających dostęp i zarządzanie bazą lub
wieloma bazami danych.
Elementarne zadania SZBD
1.Umożliwienie użytkownikowi utworzenia nowej
bazy danych i określenie jej schematu, czyli
logicznej struktury danych za pomocą
specjalizowanego języka definiowania danych.
2.Udostępnianie użytkownikowi możliwości
tworzenia zapytań o dane – query (kwerendzapytania) oraz aktualizowania danych za pomocą
języka zapytań – języka operowania danymi =
język zapytań.
3.Zapewnienie możliwości przechowywania
ogromnej ilości danych przez dłuższy czas
chroniąc je przed przypadkowym, nieprawidłowym
dostępem oraz umożliwianie efektywnego dostępu
do danych z poziomu języka zapytań i operacji na
danych.
4.Sterowanie jednoznacznym dostępem do danych
przez wielu użytkowników z zapewnieniem
bezkolizyjności oraz ochrony danych przed
przypadkowym uszkodzeniem
Funkcje systemu SZBD
1.
Zarządzanie plikami
dodawanie nowych plików do bazy danych
usuwanie plików z bazy danych
modyfikowanie struktury istniejących plików
wstawianie nowych danych do istniejących
plików
modyfikowanie danych w istniejących
plikach
usuwanie danych z istniejących plików
2.
Wyszukiwanie informacji
wydobywanie danych z istniejących plików
do stosowania przez użytkowników
wydobywanie danych z istniejących plików
przez programy użytkowe
3.
Zarządzanie bazą danych
tworzenie i monitorowanie użytkowników
bazy danych
ograniczanie dostępu do plików w bazie
danych
monitorowanie działania samej bazy danych.
Właściwości SZBD
1.Współdzielenie danych, przez niektórych
nazywane współbieżnością dostępu lub korzystanie
z bazy.
2.Integracja danych – jeden logiczny element w
bazie powinien być przechowywany tylko w
jednym miejscu.
3.Integralność danych – zmiany danych winny być
odzwierciedlone w wielu miejscach, gdzie
następuje odwołanie do tych zmiennych lub
„możliwość stwarzania użytkownikowi
definiowania reguł pozwalających zachować
warunki integralności”.
4.Poufność i bezpieczeństwo danych.
5.Abstrakcja i opis danych – określenie,
wydzielenie niektórych właściwości obiektów
przechowywanych w bazie.
Poziom opisu danych:
opis logiczny (z punktu widzenia
użytkownika)
opis fizyczny
6.Niezależność danych – oddzielenie danych od
procesów, które te dane będą używać.
7.Niezawodność – awaria sprzętowa lub
programowanie powinna wpłynąć na integralność
bazy po usunięciu awarii.
Właściwości powyżej wymienione są w danej
bazie osiągnięte tylko częściowo.
Zapytania mogą być sformułowane dwojako:
-poprzez interfejs zapytań bezpośrednich
-poprzez interfejs programów użytkowych
Aktualizacja – dotyczy operacji zmiany danych
dwoma drogami:
-poprzez interfejs zapytań bezpośrednich
-poprzez interfejs programów użytkowych
Modyfikacje (modyfikacja samego schematu
DBMS) dotyczy administratora bazy.
Moduł Zarządzania Pamięcią w prostych
systemach zarządzania może bezpośrednio
odpowiadać systemowi plików z podstawowego
systemu operacyjnego.
Moduł Zarządzania Plików przechowuje dane o
miejscu zapisania pliku na dysku i jest
odpowiedzialny za ich przesyłanie w postaci
blokowej.
Moduł Zarządzania Buforami obsługuje pamięć
operacyjną i jest odpowiedzialny za przydzielanie
odpowiednich obszarów pamięci operacyjnej i
przydzielenie ich blokom.
Procesor Zapytań nazywany jest Modułem
Zarządzania Zapytaniami, przekształca zapytania
lub operacje na bazie formułowane zazwyczaj w
języku „bardzo wysokiego poziomu”
(np. SQL) w ciąg poleceń żądających dostarczenia
odpowiednich danych. Najtrudniej jest
optymalizować zapytania, czyli generować
odpowiedzi w najkrótszym możliwie czasie.
Moduł Zarządzania Transakcjami ma
gwarantować pewność i kompletność
przeprowadzania wszystkich operacji „w jednym
ciągu”. Opisuje się to za pomocą właściwości
poprawności przeprowadzenia transakcji ACID
(Atomicity Consistency Isolation Durability –
Niepodzielność Spójność Izolacja Trwałość).
1. Atomicity – jest wykonywana albo cała
transakcja, albo nic
2. Consistency – po zakończeniu transakcji baza
musi zachowywać spójność – niesprzeczność
3. Isolation – przy jednoczesnym przeprowadzaniu
kilku transakcji ich działania nie mogą na siebie
wpływać
4. Durability – wynik transakcji nie może być
utracony z powodu awarii systemu
Do realizacji tych 4 własności wykorzystuje się:
- blokady - MZT blokuje elementy, których
dotyczy wykonywana transakcja
- logi – MZT dokonuje zapisu na dysku takich
danych jak:
- rozpoczęcie transakcji
- zmiany w bazie przez transakcję
- zakończenie transakcji
- zatwierdzenie transakcji – w chwili gdy
transakcja kończy działanie jest gotowa do
zatwierdzenia (zmiany są kopiowane do logu, log
jest zapisywany na HDD, aktualizacja samych
danych)
Modele danych
- Relacyjny Model Danych
Klasyczny
Hierarchiczny
Sieciowy
Obiektowy Model Danych
RMD– jest tylko jedna struktura danych – relacja.
Relacja to tabela, dla której jest spełniony zbiór 7
zasad.
ZASADY:
1.każda relacja w bazie ma jednoznaczną nazwę
(relacja zbiór)
2.każda kolumna w relacji ma jednoznaczną nazwę
w ramach jednej relacji (to też zbiór)
3.wszystkie wartości w kolumnie muszą być tego
samego typu
4.porządek kolumn w relacji nie jest istotny (lista
nazw kolumn to też zbiór)
5.każdy wiersz relacji musi być różny
6.porządek wierszy nie jest istotny
2
7.każde pole leżące na przecięciu kolumny i
wiersza w relacji powinno zawierać wartość
atomową (zbiór wartości nie jest dozwolony na
jednym polu relacji)
kolumny tabeli w RMD to atrybuty
wiersze tabeli to krotki
liczba kolumn w tabeli to stopień tabeli
liczba wierszy w tabeli to liczebność tabeli
DEF 1. Niech dane będą zbiory D1,D2, ... ,Dn.
Relacją matematyczną R nad tymi zbiorami
nazwiemy dowolny podzbiór iloczynu
kartezjańskiego nad tymi zbiorami
R D1xD2x ... xDn={d1, d2, ... , dn}:diD i=1,2, ...
,n
Ta relacja jest relacją n-członową. Ponieważ nczłonowa relacja jest zbiorem n-elementowych
ciągów, więc istotna jest kolejność D1xD2D2xD1
W RMD chodzi o uniezależnienie się od
uporządkowania zbiorów, więc mamy inną
konwencję notacyjną. Zamiast traktować elementy
n-członowej relacji jako n-elementowe ciągi lub
zamiast traktować funkcję f ze zbioru {1,2, ... , n}
w zbiór D1 D2 ... Dn gdzie f(i)Di traktuje
się jako funkcję nad pewnym n-elementowym
zbiorem symboli zwanych atrybutami – nie musi
być w tym zbiorze żadnych relacji porządkujących.
Niech dany będzie zbiór U={A1, A2, ... , An},
którego elementy nazywać będziemy atrybutami, i
niech AU, przyporządkowany zbiór wartości
DOM nazywamy domeną lub dziedziną A.
DEF 2. Krotką (TUPLE) typu U nazywamy
dowolną funkcję f:U{DOM(A):AU} taką, że
dla dowolnego AU f(A)DOM(A).
Zbiór wszystkich krotek typu U oznaczamy
KROTKA(U)
Jeśli zbiór pustyfunkcja pustanazywamy ją
DEF 3. Relacją typu U nazywamy dowolny
skończony podzbiór KROTKA(U).
Zbiór wszystkich relacji typu U oznaczamy
REL(U).
UPROSZCZENIA:
1)Relacje typu U oznaczamy R(U), S(U) lub krócej
R,S
2)Krotki typu U oznaczamy r(U), n(U)
3)Podzbiory zbiorów atrybutów oznaczamy X,Y,Z
4)Krotkę r typu U niekiedy utożsamiamy z ciągiem
jej wartości
r={(A1,a1), (A2,a2), ... ,(An,an)} i ai=r(A) i=1,2, ...
,n
czyli (a1,a2, ...,an)
5)Dla zbioru atrybutów {A,B} zamiast R({A,B})
piszemy R(A,B)
Niech U={A1,A2, ...,An), wówczas krotkę r(U)
można przedstawić w postaci tabeli:
r
A1 A2 ... An
r ( A1 )r ( A2 )...r ( An )
Relacja R(U) jest skończonym zbiorem krotek typu
U, R=(r1,r2,...,rn), takich, że ri(A)DOM(Ai) gdzie
i=1,2, ..., n.
Wykorzystujemy tabelaryczne przedstawienie
relacji R
Właściwości:
1.Nazwa tabeli będzie nazwą relacji
2.Jeżeli U jest zbiorem n-elementowym to tabela
będzie miała n kolumn, z których każda ma
przyporządkowany jeden z atrybutów ze zbioru U
jako nazwę
3.Uporządkowanie kolumn tabeli jest nieistotne
4.W kolumnie o nazwie AU mogą występować
wartości ze zbioru DOM(A)
5.Żadne z dwóch wierszy w tabeli nie mogą być
identyczne
6.Nieistotne jest uporządkowanie wierszy
Zakładamy, że dziedziny DOM(A),
przyporządkowane atrybutom AU, są zbiorami
wartości prostych. O wartości aDOM(A)
powiemy, że jest wartością prostą, jeżeli nie jest
ona ani zbiorem ani ciągiem elementów należących
do {DOM(A) : AU}.
DEF 4
R(U) jest w pierwszej postaci normalnej jeżeli
dziedziny DOM(A) wszystkich atrybutów AU są
zbiorami wartości prostych.
Operacje na danych (relacjach)
1.
wstawianie danych do relacji
2.
usuwanie danych z relacji
3.
edycja danych
4.
wyszukiwanie danych
Algebra Relacyjna
1.
selekcjaograniczenie
2.
rzut (projekcja)
3.
złączenie
4.
dopełnienie
5.
suma
6.
przecięcie (przekrój)
7.
różnica
8.
iloraz (podzielenie)
1-3 główne, 4-8 modelowane na operatorach teorii
zbiorów
operacje mnogościowe (zbiory) - suma, różnica,
przecięcie, dopełnienie
operacje relacyjne – (def. oparte o rozumienie
relacji jako zbioru krotek) projekcja, selekcja,
złączenie, iloraz.
Operacje mnogościowe
DEF 5
Relację T(U) nazywamy sumą relacji R(U) i S(U),
co oznaczono T=RS, wtedy i tylko wtedy, gdy
T={tKROTKA(U) : tR tS}.
DEF 6
Relację T(U) nazywamy różnicą relacji R(U) i
S(U), co oznaczamy T=R-S, wtedy i tylko wtedy,
gdy T={tKROTKA(U) : tR tS}.
DEF 7
Relację T(U) nazywamy projekcją (przecięciem)
relacji R(U) i S(U), co oznaczamy T=RS, wtedy i
tylko wtedy, gdy T={tKROTKA(U) : tR
tS}.
DEF 8
Relację T(U) nazywamy dopełnieniem relacji
R(U) , co oznaczamy T=-R, wtedy i tylko wtedy,
gdy T=KROTKA(U)-R={tKROTKA(U) : tR }.
dopełnienie jest określone gdy zbiór
KROTKA(U)
Przykład
RS=-(-R-S)
R-S=R(-S)=-R(-RS)
Operacje Relacyjne
Ograniczenie krotki typu U do zbioru XU
DEF 9
Niech dana będzie krotka r typu U i niech XU.
Krotkę typu X nazywamy ograniczeniem krotki r
do zbioru X, co oznaczamy t=r[X] wtedy i tylko
wtedy, gdy dla każdego AX, r(A)= t(A), czyli
gdy krotki r i t są identyczne na zbiorze X, na
zbiorze U-X mogą być różne.
Złączenie krotek
DEF 10
Niech dla dowolnych zbiorów otwartych X,YU
dane będą krotki r typu X i s typu Y. Krotkę t typu
Z, gdzie Z=XY nazywamy złączeniem krotek r
i s, co oznaczamy t=r s, wtedy i tylko wtedy,
gdy t[X]=r i t[Y]=s, czyli wtedy, gdy ograniczenie
krotki t do zbioru X jest tożsame z r i ograniczenie
krotki t do Y jest tożsame z s.
Między operacjami ograniczenia i złączenia
zachodzi następująca zależność:
t(XY)=r(X) s(Y)t[X]=rt[Y]=s .
Projekcja
DEF 11
Niech dana będzie relacja R typu U oraz zbiór
XU. Relację T typu X nazywamy projekcją
relacji R na zbiór X, co oznaczamy T=R[X]
wtedy i tylko wtedy, gdy
T={tKROTKA(X) :( r R ) t=r[X]}
alternatywnie
Własność 1
Niech dana będzie relacja R typu U, niech XU.
Wówczas
R[X]={tKROTKA(X) ( s Krotka(U X ) )
t sR}
Selekcja
Niech U – zbiór atrybutów
A,A`- dowolne atrybuty ze zbioru U
v – dowolna wartość ze zbioru {DOM(A) :
AU} {,,,,,}
symbol negacji, -symbol koniunkcji, symbol alternatywy
1.Elementarnym warunkiem selekcji nazywamy
dowolne wyrażenie postaci A lub AA`
2.Warunek selekcji definiujemy w sposób
rekurencyjny:
a)każdy elementarny warunek selekcji jest
warunkiem selekcji
b)jeżeli E i E` są warunkami selekcji, to również
(E), (EE`) oraz (EE`) są warunkami selekcji.
DEF 12
Relację T(U) nazywamy selekcją relacji R(U)
względem warunku selekcji E, co oznaczamy
T=R/E/, wtedy i tylko wtedy gdy T={tR:
E(t)=true}.
Złączenie
DEF 13
Niech dane będą relacje R typu X i S typu Y.
Relację T typu XY nazywamy złączeniem
relacji, co oznaczamy T=R S, wtedy i tylko
wtedy, gdy
T={tKROTKA(XY):t[X]Rt[Y]S}
Własność 2 (alternatywnie)
Niech R będzie relacją typu X, a S relacją typu Y.
Wówczas
R S={tKROTKA (XY):( r R )
( s S ) t=r s}
Dla złączenia zachodzą zależności
R S=S R
(R S) T=R (S T)
jeżeli X U, to R[X] R=R
jeżeli XY=U, to RR[X] R[Y]
Podzielenie (wersja teoretyczna)
DEF 14
Niech dana będzie relacja R(U) i zbiór atrybutów
XU. Relacja T(U-X) nazywamy podzieleniem
(ilorazem) relacji R przez zbiór X, co oznaczamy
T=R/X, wtedy i tylko wtedy, gdy
T={tKROTKA(U-X): ( s KROTKA( X ) )
t sR}cc
W praktyce wyznaczanie krotki typu X i U-X jest
trudne dlatego przyjmuje się, że zbiory krotek tych
typów są projekcjami.
Algorytm podzielenia
1.Utworzenie pustej relacji T typu U-X
2. Czy przeanalizowano wszystkie krotki typu U-X
3.Weź kolejną krotkę typu U-X
4. Czy dla każdej konstrukcji typu X złączenie
t sR
5. Włącz t do relacji T
6. Relacją wynikową jest T
Podzielenie (wersja praktyczna)
DEF 15
Niech dana będzie relacja R(U) i niech dla
pewnego XU dana będzie relacja S typu X.
Relację T(U-X) nazywamy podzieleniem
(ilorazem) relacji R(U) przez relację S, co
oznaczamy T=R:S, wtedy i tylko wtedy, gdy
T={tR[U-X]: ( s S ) t sR}
Lemat alternatywny:
R:S={tR[U-X]: SR [t,X]}
gdzie R[t,X]={sR[X]: t sR}
Algorytm:
1. Utwórz pustą relację T[U-X].
2. Wyznacz projekcje R[U-X].
3
3. Czy przeanalizowano wszystkie krotki z R[U-X]
?
4. Weź kolejną krotkę tR[U-X].
5. Wyznacz R[t,X].
6. Czy SR[t,X]?
7. Dołącz t do relacji T.
8. Relacją wynikową jest T.
KLUCZ
Każda relacja musi posiadać tzw. klucz główny,
aby uniknąć powtarzania się wierszy w relacji. Jest
to jedna lub więcej kolumn w tabeli, która
jednoznacznie identyfikuje wiersz. Może być wiele
kluczy kandydujących w relacji, ale z nich
wybiera się jeden klucz główny. Każdy klucz
kandydujący (również główny) musi być
jednoznaczny – musi posiadać wartość (nie może
posiadać wartości „null”). Null jest trzecią
wartością logiczną wg CODD’a. Klucze obce to
kolumna lub grupa kolumn czerpiących wartość z
tej samej dziedziny co klucz główny powiązany z
nią w bazie danych.
SELEKCJA
Jest to pozioma maszynka do cięcia, która
wydobywa wartość pasującą do klucza i wysyła ją
na wyjście.
RESTRICT <nazwa tabeli>
[WHERE<warunek>]<tabela wynikowa>
np. RESTRICT MODUŁY WHERE
SEMESTR=1 R1
PROJEKCJA (RZUT)
Bierze jedną relację jako argument i produkuje
jedna relację wynikową – pionowa maszynka do
cięcia, daje jedna lub wiele kolumn na wyjściu.
POJECT <nazwa tabeli> [<LISTA
KOLUMN]<tabela wynikowa>
np. PROJECT MODUŁY [NazwaMod]R1
ZŁĄCZENIA
Oparte są na relacyjnym operatorze iloczynu
kartezjańskiego.
PRODUCT <tabela1>WITH<tabela2><tabela
wynikowa>
W praktyce są stosowane 3 rodzaje złączeń:
-RÓWNOZŁĄCZENIA
Iloczyn kartezjański po którym wykonywana jest
selekcja.
EQUIJOIN <tabela1>WITH<tabela2><tabela
wynikowa>
np. EQUIJOIN WYKŁADOWCY WITH
MODUŁY R1
Nie usuwa powtarzających się kolumn...
(2xNrPrac)
-ZŁĄCZENIA NATURALNE
iloczyn kartezjański+selekcja+rzut
JOIN <tabela1>WITH<tabela2><tabela
wynikowa>
np. JOIN WYKŁADOWCY WITH
MODUŁYR1
-ZŁĄCZENIA ZEWNĘTRZNE
Są 3 typy – lewo-, prawo- i obustronne
SUMA
Musimy mieć dwie zgodne tabele (taka sama
struktura, takie same kolumny określone na tych
samych dziedzinach).
<tabela1>UNION<tabela2><tabela wynikowa>
np. WYKŁADOWCY UNION
ADMINISTRATORZY R1
PRZECIĘCIE
Uwzględnia tylko wspólne wiersze obu tabel.
<tabela1>INTERSECTION<tabela2><tabela
wynikowa>
np. WYKŁADOWCY INTERSECTION
ADMINISTRATORZY R1
RÓŻNICA
<tabela1>DIFERENCE<tabela2><tabela
wynikowa>
np. WYKŁADOWCY DIFERENCE
ADMINISTRATORZY R1
np. ADMINISTRATORZY DIFERENCE
WYKŁADOWCY R1
PROCEDURALNE JĘZYKI ZAPYTAŃ
Zapytanie o to, jakie moduły prowadzi Bryszewski
możemy sformułować następująco:
np.
RESTRICT WYKŁADOWCY WHERE
NazwiskoPrac=”Bryszewski” R1
JOIN R1 WITH MODUŁY ON NrPrac R2
PROJECT R2 (NazwaMod) R3
lub
JOIN WYKŁADOWCY WITH MODUŁY ON
NrPrac R1
SELECT R1 WHERE
NazwiskoPrac=”Bryszewski” R2
PROJECT R2 (NazwaMod) R3
lub
PROJECT (JOIN MODUŁY WITH
(RESTRICT WYKŁADOWCY
WHERE NazwiskoPrac=”Bryszewski”)
ON NrPrac)
(NazwaMod)
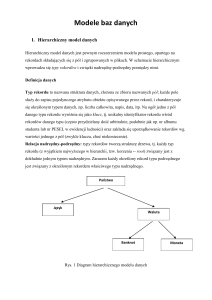
KLASYCZNE MODELE DANYCH
Model podstawowy to tzw.” model prosty” . W
tym modelu obiekty są reprezentowane za pomocą
struktury rekordów.
- implementacje związków w modelu relacyjnym
to poprzez klucze obce, tutaj powiązania typu
nadrzędny, podrzędny.
-W modelu hierarchicznym danymi jest
wykonywane poprzez wbudowanie funkcji dostępu
do bazy w wybranym języku programowania ( w
języku gospodarza). Hierarchiczne języki zapytań
są opisywane jako proceduralne języki zapytań.
W modelu hierarchicznym występuje wiele
wewnętrznych więzów integralności:
1.nie mogą istnieć żadne wystąpienia rekordów
poza jednym wyjątkiem – rekordem
korzeniem(najwyższym korzeniem w hierarchii).
2.nie mogą istnieć wystąpienia bez powiązania z
odpowiednim wystąpieniem rekordu podrzędnego.
3.nie można wstawić rekordu podrzędnego dopóki
nie zostanie powiązany z nadrzędnym.
Rekord jest rozumiany jako podstawowa
4.usunięcie rekordu nadrzędnego powoduje
jednostka informacji przy zapisie informacji do
automatyczne usunięcie wszystkich powiązanych z
pliku (pojęcie bezpośrednio wzięte z modelu
prostego). Rekord ma w danej strukturze stałą
długość. Rekord to odpowiednik krotki lub
wiersza.
Głównymi operacjami w tym modelu są operacje
na rekordach:
nim rekordów podrzędnych
5.jeżeli podrzędny typ rekordu ma związane dwa
lub więcej nadrzędnych typów rekordów, to rekord
podrzędny musi być powielony dla każdego
rekordu podrzędnego.
a)
zapis rekordu
Model sieciowy
W modelu sieciowym tak jak w modelu
b)
odczyt rekordu
hierarchicznym są dwa typy danych: rekordy i
Każdy rekord jest podzielony na pola, posiadające
powiązania.
określoną długość, nazwę i typ w ramach
Różnice pomiędzy modelem sieciowym
hierarchicznym:
1.pola mogą być używane do przechowywania
zdefiniowanej struktury rekordu. Bezpośrednim
a
rozszerzeniem modelu prostego jest model
wielu wartości lub do reprezentowania złożonych
hierarchiczny, a klasyczny sieciowy jest
wartości, które się powtarzają
traktowany jako rozszerzenie modelu klasycznego.
2.w odróżnieniu od modelu hierarchicznego, gdzie
Model hierarchiczny:
jeden rekord może mieć najwyżej jeden rekord
- nie posiada jednolitej teoretycznej podstawy
nadrzędny w modelu sieciowym jeden rekord może
- opracowany w oparciu o analizę istniejących
implementacji
- są używane dwie struktury danych:
1) REKORD
2) POWIĄZANIA
Poszczególne rekordy to zbiór pól o określonych
atrybutach i przypisanych typach, np. (integer,
string[])
Powiązanie- związek określony jako jeden do
wielu między dwoma typami rekordów; w tym
modelu ma charakter nadrzędny, podrzędny.
Inaczej jest to model złożony z wielu typów
rekordu, powiązanych za pomocą związków
podrzędnych, nadrzędnych.
Różnice między modelem hierarchicznym i
relacyjnym:
- model hierarchiczny(typy rekordów) ma inne
struktury danych niż model relacyjny(relacje,
związki)
mieć kilka rekordów nadrzędnych.
3.w modelu sieciowym występują nowe jednostki
danych.
Organizacja CODASYL wprowadziła następujące
rodzaje danych:
1) dana elementarna DATA ITEM
2) wektor
VECTOR
3) grupa powtórzeniowa REPEATING GROUP
Te trzy jednostki nie mogą istnieć samodzielnie,
mogą być składowymi rekordu.
4) rekord RECORD
5) kolekcja SET
Skończony zbiór rekordów tego typu możemy
nazwać plikiem typu P,R,S.
Przy włączeniu rekordu do pliku jest on w praktyce
rozszerzany o jeszcze jedno pole:
Pole klucza – umożliwi to jednoznaczną
identyfikację rekordu.
4
- last()(r) = sL L > 0
END L = 0
- last()(si) = sL 1 i L
- next()(r) = s1 L > 0
END L = 0
- next()(si) =si+1 i < L
END i = L
- prior()(r) = END
- prior()(si) =si-1 i > 1
END i = 1
W przypadku wektorów oraz grup
powtórzeniowych konieczna jest znajomość
aktualnej wartości tzw. Licznika powtórzeń.
Wyróżniki rekordu i grupy powtórzeniowej:
1)grupa powtórzeniowa nie może istnieć
KOLEKCJA
Podstawowe zadanie, to odzwierciedlenie
powiązań 1 do n między poszczególnymi typami
rekordów.
Zał.
- jakaś tam nazwa
R,S1,S2,...,Sm – pewne typy rekordów
takie, że:
- Si Sj dla i j
- Dla pewnego i<1,m> może zachodzić R=Si
- Dla każdego i<1,m> między r i si istnieje
powiązanie 1 i M
Wówczas , to nazwa typu kolekcji, a zapis (
R,S1,S2,...,Sm) to typ kolekcji.
R to typ właściciela (ower) – typ właściciela
kolekcji .
Każdy z rekordów Si i<1,m> nazywamy typem
podwładnego (member) lub członka kolekcji .
Graficznie jest to hiperdrzewo złożone z
wierzchołków.
samodzielnie w bazie, wchodzą w skład rekordu.
2)Powiązania między grupami powtórzeniowymi
mogą mieć tylko charakter zależności
hierarchicznych.
4)Jedna grupa powtórzeniowa może być
podporządkowana innej wchodząc w jej skład.
5)Między rekordami trzeba ustalić zależności
zarówno hierarchiczne jak i sieciowe.
Rekord tego typu może być podrzędny w stosunku
do rekordu kilku plików .
W modelu sieciowym takie powiązania realizuje
się przez założenie dodatkowej struktury na typy
rekordów, poprzez kolekcję.
Zbiór wszystkich wystąpień będziemy oznaczać
KOLEKCJA() = {(r1), (r2), ... , (rN)}
jeśli F(R) = {r1, r2, ... , rN}.
Wyróżnia się:
- kolekcje jednostkowe
- rekurencyjne
KOLEKCJE JEDNOSTKOWE
Mówimy o niej wtedy, gdy typ kolekcji ma postać
(SYSTEM, R), czyli typem właściciela kolekcji
jest wyróżniony typ rekordów SYSTEM, a
jedynym typem podwładnego jest dowolny typ
rekordu SYSTEM.
R
- Podstawową jednostką dostępu do bazy są
Typ rekordu SYSTEM charakteryzuje się tym, że
ma tylko jedno wystąpienie i jest ono rekordem
pustym.
rekordy. Dostęp do grupy powtórzeniowej jest
możliwy tylko wówczas gdy udostępniony jest
rekord zawierający daną powtórzeniową .
- W obrębie rekordu musi być określona wartość
S
powtórzeniowej wchodzącej w skład rekordu.
Powiązania
sieciowym.
Założenia:
między
rekordami
w
modelu
Mamy dwa typy rekordów : R i S
X, Y – pliki odpowiednich typów R i S
Będziemy mówić, że istnieje między rekordami
typów R i S powiązanie, jeśli określone są
przekształcenia:
f(x) :X->Y
w zależności od własności przekształceń wyróżnia
się trzy rodzaje powiązań:
- 1:1 powiązanie jedno-jednoznaczne
istnieje to powiązanie jeśli f(x), f(y)są funkcjami
R
S
R
S
np. związek małżeński
- 1:M jedno-wieloznaczne powiązanie (między
rekordami R, S istnieje powiązanie 1:M, jeżeli
jedno z przekształceń f(x), f(y) jest funkcją ).
R
R
S
R
S
S
R
S
- N:M wielo- wieloznaczne ( między rekord R,S
zachodzi M:N jeżeli ani f(x), ani f(y) nie jest
funkcją).
R
S
R
S
Niech dany będzie typ kolekcji ( R,S1,S2,...,Sm)
oraz niech rF(R) będzie wystąpieniem typu
właściciela. Wówczas wystąpieniem kolekcji typu
z rekordem właściciela r będziemy nazywać ciąg
(r)=(r,s1,s2,...,sL) gdzie s1,s2,...,sL L 0 są różne i
pochodzą ze zbioru F(S1) lub F(S2) lub ... lub
F(Sm). Każdy rekord należący do tego wystąpienia
kolekcji jest rekordem typu R (wystąpienie typu
właściciela) lub rekordem jednego z typów
podwładnych.
f(y) :Y->X
R
S
Gdzie R,S1,S2,...,Sm są wierzchołkami hiperdrzewa,
1
2
przy
czym R jest początkiem
hiperkrawędzia, a m
zbiór {S1,S2,...,Sm} jest końcem tej hiperkrawędzi.
Zasadnicze cechy kolekcji:
1.Do wystąpienia kolekcji typu należy jeden
rekord właściciela oraz ciąg rekordów
podwładnych. Wszystkie rekordy podwładnych
tworzą jeden ciąg.
2.Wystąpienie kolekcji może być traktowane jako
łańcuch, którego kotwicą (head) jest rekord
właściciela, przy czym możliwe jest przechodzenie
między elementami tego łańcucha na różne
sposoby (do pierwszego, następnego,
poprzedniego, ostatniego rekordu) wśród rekordów
podwładnych, jak również do rekordu właściciela.
licznika powtórzeń dla każdej grupy
S
KOLEKCJE REKURENCYJNE
Wtedy, gdy typ właściciela jest typem
podwładnego w tej kolekcji (jednocześnie)
ZALEŻNOŚĆ_SŁUŻBOWA(PRACOWNIK,
PRACOWNIK) – każdy pracownik jest powiązany
ze zbiorem pracowników będących jego
podwładnymi.
Ponieważ istnieje powiązanie 1:M pomiędzy
typem właściciela i każdym z typów podwładnych
kolekcji , to jeden rekord każdego typu
podwładnego może należeć co najwyżej do
jednego wystąpienia kolekcji . Do tego typu
wystąpienia może należeć wiele rekordów jednego
typu podwładnego, ale może też nie należeć żaden
– czyli w zbiorze wystąpień kolekcji każde
wystąpienie jest jednoznacznie zidentyfikowane
przez właściciela lub typ podwładny.
P
P
P
P
P
P
1
2
3
4
5
6
Niejednorodności przy przejściu z P2 do P3 lub P2
do P4. Stosujemy więc specjalne tablice adresowe:
Jeśli ( R,S1,S2,...,Sm) jest typem kolekcji
(rekurencyjnej lub nie), to dla każdych dwóch
rekordów r, r’ typu R,
r r’, wystąpienia tej kolekcji spełniają warunek
( (r) – {r})( (r’) – {r’}) = 0
SZCZEGÓLNE PRZYPADKI TYPÓW
KOLEKCJI
1)
Jeden typ kolekcji może być typem
właściciela wielu typów kolekcji:
R
V
S
2)
.
.
T
U .
Typ
. rekordu będący
. typem właściciela
.
jednego typu kolekcji mogą być typem
.
. typu kolekcji:.
podwładnym
innego
Niech dane będzie pewne wystąpienie (r,s1,s2,...,sL)
L 0 kolekcji . Wówczas na rekordach
należących do tego wystąpienia zdefiniowane są
następujące funkcje:
-owner()(r) = r
-owner()(si) = r 1 i L
-first()(r) = s1 L > 0
END L = 0
- first()(si) = sL 1 i L
S
R
V
R
S
U
.
.
.
W
.
5
3)
Typ rekordu będący typem właściciela
jednego typu kolekcji może być jednocześnie
typem podwładnego tego samego typu
kolekcji (kolekcja rekurencyjna):
R
Diagram schematu bazy danych będziemy
nazywać czwórką uporządkowaną inaczej
hipergraf etykietowany.
DSCH=(H, A, , )
gdzie:
H=(X, K, w, p) – hipergraf
A-alfabet etykietujący A=(R, K)
i dwie funkcje
:XR funkcja jedno-jednoznaczna przypisująca
wierzchołkom typy rekordów
:XR funkcja jedno-jednoznaczna przypisująca
hiperkrawędziom nazwy kolekcji.
W sieciowej bazie danych będą występowały dane
elementarne, rekordy, kolekcja i baza danych.
.
S
T
Typ, który nazwiemy rekordem – będzie się
składał tylko z danych elementarnych, a więc nie
.
4) Dwa typy kolekcji mogą mieć wspólne typy
ma wektora i nie ma grupy powtórzeniowej.
.
rekordów podwładnych:
Wektor i grupę powtórzeniową będziemy
realizować jako rekordy.
R
S
Następne uproszczenie:
typ kolekcji może mieć tylko jeden typ podwładny
(R, S)
każdą kolekcję (R, S1, S2, ...,Sn) będziemy
traktować jako zbiór kolekcji
1(R, S1)
2(R, S2)
.
.
T
U
V
3(R, S3)
.
.
..............
.
.
n(R, Sn)
5) Jeden typ rekordu może być typem
(nie będzie to efektywne, ale jest możliwe)
właściciela dwóch różnych typów kolekcji,
co osiągniemy?
które mają wspólny typ rekordów
Ponieważ typy kolekcji mogą mieć zdefiniowany
podwładnych:
tylko jeden typ podwładny
powiązania pomiędzy typami rekordów wyrazimy
w postaci grafu jako szczególny przypadek
hipergrafu.
R
G=(X, K, w, p)
gdzie
X- skończony zbiór wierzchołków grafu
K- skończony zbiór krawędzi grafu
w: KX – funkcja przypisująca krawędzi ?
p : KX - funkcja przypisująca krawędzi jej
.
.
S
T
U
koniec.
.
.
BAZA DANYCH – jednostka danych określonego
.
.
Założenia
typu wraz z wystąpieniem nazywane stanem bazy
programy użytkowe pisane w odpowiednich
danych
językach proceduralnych będą współpracować z
sieciową baza danych za pomocą
BD – baza danych
trzyelementowego języka
R1, R2, ... , RN – typy rekordów
1 – język podschematów – pozwala on opisywać
1, 2, ... , M – typy kolekcji
podzbiór schematu dla konkretnego programu
użytkowego logiczny (zewnętrzny)obraz bazy
Zapis BD(R1, R2, ... , RN, 1, 2, ... , M) lub (R1,
danych.
R2, ... , RN, 1, 2, ... , M) będziemy nazywać
Ten język podschematów umożliwia
typem bazy danych.
współdziałanie programu użytkowego z
STAN(BD)={ F(R1), F(R2), ... , F(RN),
podzbiorem danych w bazie. W tym języku jest
KOLEKCJA(1), KOLEKCJA(2), ... ,
definiowany tzw. obszar roboczy użytkownika,
KOLEKCJA(M)}
czyli jest to wydzielona strefa pamięci, w której
Gdzie:
system
- F(Ri) – oznacza zbiór wystąpień typu rekordu Ri
zarządzania baza danych umieszcza wszystkie
LiN
dane będące odpowiedzią na polecenie
- KOLEKCJA(j) – to zbiór wystąpień kolekcji
użytkownika i gdzie również są kierowane
typu j 1 j M
wszystkie dane przeznaczone dla systemu
zarządzania bazą danych. Dla każdego elementu
Bazę można przedstawić jako hipergraf H=(X, K,
danych w podschemacie przydzielona jest nazwa
w, p) gdzie:
łącznika tego obszaru, inaczej jest to tzw. pozycja
- X –skończony zbiór wierzchołków hipergrafu
łącznikowa obszaru roboczego użytkownika co
- K skończony zbiór hiperkrawędzi
pozwala na odwołania programów do tego obszaru.
- w – funkcja przypisująca hiperkrawędzi jej
2 – Język manipulowania danymi – jest on
początek w: KX
wykorzystywany w czasie wykonywania programu
- p - funkcja przypisująca hiperkrawędzi jej koniec
użytkowego do sterowania odwołaniami do bazy.
p: Kp(x), którym jest podzbiór X
3 – trzeci element jest nazywany językiem opisu
Proces etykietowania
pamiętania danych, albo językiem schematu
W procesie etykietowania wierzchołkom i
pamiętania – określa on w jaki sposób dane
hiperkrawędziom są przypisywane odpowiednio
opisane w schemacie mają być organizowane w
typy rekordów i nazw kolekcji tworzące tzw.
pamięci niezależnie od systemu operacyjnego i
alfabet etykietujący.
fizycznych rodzajów pamięci. Schemat pamiętania
Alfabet etykietujący – para zbiorów A=(R, K)
wpływa na efektywność działania programów.
R- skończony zbiór typów rekordów,
Oddzielenie schematu pamiętania od schematu
K- skończony zbiór nazw kolekcji.
logicznego izoluje programy użytkowe od zmian
wykonywanych w bazie z punktu widzenia
efektywności
1.Przebiega z wykorzystaniem komend języka
manipulowania danymi. Proces kieruje do systemu
zarządzania bazą danych jedno polecenie
dotyczące danych w bazie danych.
2.System zarządzania bazą danych jest
odpowiedzialny za analizę polecenia i dokonuje
ewentualnego uzupełnienia argumentów polecenia
o dane ze schematu bazy danych, schematu
pamiętania i podschematu, do którego odwołuje się
proces wydający polecenie.
3.Na podstawie polecenia i ewentualnych
uzupełnień system zarządzania bazą kieruje do
systemu operacyjnego żądanie wykonania
fizycznych operacji wejścia-wyjścia wymaganych
do realizacji tego polecenia.
4.Odzwierciedla współdziałanie systemu
operacyjnego z urządzeniami pamięci
przechowującymi stan bazy danych.
5.Fizyczna transmisja danych między stanem bazy
danych i buforami systemowymi.
6.System zarządzania bazą danych przekazuje
dane między buforami systemowymi a obszarem
roboczym użytkownika jednocześnie
przekształcając dane zgodnie z opisami w
schemacie i podschemacie.
7.Na podstawie wyniku realizacji polecenia system
zarządzania bazą danych przekazuje procesowi
informacje o stanie realizacji polecenia np.:
wystąpienie błędu.
8.Przetwarzanie danych w obszarze roboczym
użytkownika zgodnie z instrukcjami języka
bazowego.
9.Odzwierciedla zarządzanie przez system
zarządzania bazą danych buforami systemowymi.
Bufory są wykorzystywane wspólnie przez
wszystkie procesy za pośrednictwem systemu
zarządzania bazą.
Podsumowując
Model sieciowy według organizacji CODASYL
Opis struktury i zawartość bazy danych nazywamy
schematem.
Język schematu np.: DLL
Język podschematu i język manipulowania danymi
są traktowane jako rozszerzenia proceduralnych
języków programowania. Wówczas składnia i inne
charakterystyczne elementy są związane z tym
językiem np.: C; chyba że jest wykorzystywany
samodzielny język zapytań np.: do interakcyjnego
korzystania z bazy.
Schemat pamiętania jest to opis sposobu w jaki
dane są zorganizowane w środowisku pamięci –
abstrahując od systemu operacyjnego i samych
fizycznych urządzeń pamięci.
DDL – typowy wzorcowy język schematu. Wywarł
on istotny wpływ na tworzenie zarządzania bazą
danych. W założeniach liczono na dużą
przenoszalność programów. Służy on do
definiowania schematu bazy danych, która może
być użytkowana wspólnie przez różne programy.
Jest niezależny od innych języków, z których
korzysta system zarządzania bazą danych.
Dana elementarna – najmniejsza jednostka
danych, w stanie bazy reprezentuje ją jej wartość.
Dana zagregowana – zestaw danych
elementarnych wewnątrz rekordu.
W sieciowej odmianie klasycznej mam y dwa
rodzaje tych danych zagregowanych:
- wektory - jednowymiarowy ciąg danych
elementarnych mający identyczne charakterystyki.
- grupy powtórzeniowe – zestaw danych, który
może wielokrotnie pojawić się wewnątrz rekordu.
Może się składać z danych elementarnych,
wektorów, z samej grupy (grup) powtórzeniowej (ych).
Rekord – zestaw złożony z zera, jednej lub kilku
danych elementarnych lub zagregowanych.
6
W DDL definiujemy typ rekordu. W bazie może
dowolna liczba rekordów tego samego typu.
Klucz bazy danych – jednoznaczna (unikalna)
wartość identyfikująca rekord w bazie danych. Ta
wartość jest dostępna dla procesu, gdy rekord jest
wybierany lub zapamiętywany.
Kolekcja – wystąpienie określonego zestawu
rekordów. W DDL definiuje się typ kolekcji. Baza
danych może zawierać dowolną liczbę wystąpień
jednego typu kolekcji. Jeden typ rekordu jest
właścicielem, natomiast jeden lub więcej typów
rekordów są podwładnymi kolekcji. Wystąpienie
kolekcji powinno zawierać jedno wystąpienie
właściciela i może zawierać dowolną liczbę
wystąpień każdego typu podwładnego.
Obszar – zestaw rekordów, w których nie musi
być określona zależność, właściciel - podwładni.
Obszar może zawierać rekordy jednej lub większej
liczby typów. Natomiast rekordy jednego typu
mogą znajdować się w różnych obszarach.
Schemat – składa się ze zdań języka, np. DDL i
jest pełnym opisem bazy danych. Zawiera nazwy i
opisy wszystkich obszarów, typów kolekcji, typów
rekordów i odpowiednich danych elementarnych i
zagregowanych istniejących w bazie.
Baza danych – składa się ze zbioru wszystkich
rekordów, kolekcji i obszarów, które zostały
zdefiniowane w schemacie i są utrzymywane
zgodnie z ta definicją.
Program – zestaw instrukcji pewnego języka
programowania.
Proces – wykonywanie pewnego programu wraz z
przydzielonym środowiskiem.
Język manipulowania danymi – język za
pomocą którego organizuje się przekazywanie
danych między procesem a bazą danych.
Obszar roboczy użytkownika – strefa pamięci, w
której umieszczone są i z której pobierane są dane.
Do obszaru systemu zarządzania bazą kieruje dane
będące odpowiedzią na zapytania. W tym obszarze
są umieszczane wszelki dane do pobrania przez
system zarządzania. Każdej danej elementarnej
włączonej do podschematu przydzielana jest
komórka obszaru roboczego użytkownika i
pozwala to na odwołania w programie zgodnie z
nazwą określoną w podschemacie.
Schemat pamiętania – wykorzystywany przy
opisie środowiska pamiętania dla bazy danych i
odwzorowanie go później fizycznie w pamięci.
Ważniejsze funkcje systemu zarządzania bazą
danych SZBD:
1.przekształcenia między schematem a
podschematem
2.przekształcenia między schematem a schematem
pamiętania
3.funkcje związane z utrzymaniem całego systemu.
Podschemat i schemat powinny być od siebie
niezależne natomiast istnieją pomiędzy nimi
współzależności:
Na podstawie jednego schematu można utworzyć
dowolną liczbę podschematów.
Deklaracja jednego podschematu nie ma wpływu
na deklarację innego.
Programy użytkowe odwołują się do podschematu,
ale jest np. możliwe, że podschemat jest
identyczny ze schematem.
Do jednego podschematu mogą się odwoływać
różne programy.
Program może wykorzystywać tylko te obszary,
rekordy i kolekcje, które zostały opisane w
podschemacie, do którego ten program się
odwołuje.
Program powinien się odwoływać do podschematu
opisanego zgodnie z wymaganiami języka, w
którym został program napisany.
Dlaczego rozdziela się podschemat i schemat?
Rozdzielenie schematu i podschematu pozwala
oddzielić opis całej bazy od części „widzianej”
przez inne oddzielne programy.
Uzasadnienie rozdzielenia schematu od
podschematu:
- poszczególni programiści będą mieli do czynienia
nie z całą bazą, a tylko z fragmentami, które
dotyczą opracowywanych programów.
- dane z bazy mogą się odnosić do wielu
zastosowań jak również mogą być
wykorzystywane współbieżnie (ułatwia to pisanie i
testowanie programów).
- proces jest ograniczony do tej części bazy, która
jest określona w podschemacie, wówczas pozostała
część bazy jest izolowana od tego procesu.
- rozdzielenie schematu i podschematu pozwala na
osiągnięcie pewnego stopnia niezależności w
schemacie bazy danych. Wówczas mogą być
dokonywane pewne zmiany. Sama baza może być
przestrajana bez konieczności zmian w programie.
Program będzie zależał tylko od schematu. Jest to
możliwe dlatego, że podschemat różni się od
schematu pod pewnymi względami, chociaż jest na
nim oparty.
- w celu zdefiniowania samej bazy danych można
utworzyć albo wykorzystać specjalny język i
opisywać tylko tę część bazy, która jest istotna dla
konkretnego programu.
Najważniejsze różnice między schematem a
podschematem:
a) Na poziomie danych elementarnych
Może być opuszczony opis pewnych danych
elementarnych.
Charakterystyki danych elementarnych
podschematu mogą się różnić od charakterystyk
danych elementarnych ze schematu.
Różne może być uporządkowanie danych
elementarnych w schemacie i podschemacie.
b) Na poziomie danych zagregowanych
(wektory i grupy powtórzeniowe)
Może być opuszczony opis pewnych danych
zagregowanych, może być zmienione
uporządkowanie.
Wektory mogą być przekształcone w tablice
wielowymiarowe.
Dane elementarne lub dane zagregowane mogą być
zgrupowane i opatrzone jedną wspólną nazwą.
Za pomocą języka opisu danych podschematu
można opisywać odwzorowania pewnych struktur
pomocniczych.
c) Na poziomie rekordów
Może być opuszczony opis pewnych typów
rekordów, można wprowadzić opis nowych typów
rekordów utworzonych z danych występujących w
innych typach rekordów.
d) Na poziomie kolekcji
Można opuścić opis pewnych typów kolekcji,
mogą być określone inne kryteria wyboru kolekcji,
można opuścić opisy pewnych typów rekordów
podwładnych mu kolekcji.
e) Na poziomie obszarów
Mogą być opuszczone opisy pewnych obszarów i
włączonych do nich rekordów, wtedy, gdy inne
wystąpienia rekordów tego samego typu mogą być
włączone do tych obszarów.
Dlaczego rozdzielono schemat od schematu
pamiętania?
Rozdzielenie to pozwala na oddzielenie logicznego
opisu bazy danych od opisu sposobu jej
pamiętania.
Ma to kilka zalet:
Administrator bazy danych może tak
zaprojektować strukturę schematu złożoną z
rekordów logicznych i kolekcji tak, że będzie ona
adekwatna do obecnych zastosowań, ale i również
tych perspektywistycznych (przyszłościowych).
Oddzielenie opisu od opisu logicznego bazy ma
wpływ na efektywność bazy, bowiem metody
pamiętania i odwzorowania schematu pamiętania
są określone w samym schemacie pamiętania.
Strojenie systemu może być zrealizowane przez
zmianę schematu pamiętania. Unikamy w ten
sposób zmiany schematów, podschematów i
programów użytkowych. Sam schemat
pamiętania opisuje obraz danych za pomocą pojęć
niezależnych od konkretnych urządzeń. Dzięki
temu baza jest niezależna i administrator może
wybrać konkretne nośniki i urządzenia o
charakterystykach i potrzebach zgodnych z
bieżącymi wymaganiami, to wszystko bez zmiany
schematu pamiętania.
Co powinien udostępniać system zarządzania?
- System zarządzania powinien udostępnić języki
umożliwiające tworzenie programów
pomocniczych wspomagających codzienne
utrzymanie bazy danych (programy składowania,
redagowania wydruków, ładowania, analizowania
danych składowych).
- System zarządzania powinien dawać mechanizmy
tworzenia programów odtwarzania bazy danych z
możliwością rejestrowania wszelkich działań w
bazie jak również organizację punktów
kontrolnych, w których następuje sprawdzenie
integralności bazy.
- System zarządzania powinien umożliwiać
modyfikacje schematu lub podschematu
uwzględniając konsekwencje zmian zawartości
bazy (Jeżeliby nie udostępniał takich możliwości
zmian, wówczas zmiany w schemacie mogłyby
następować poprzez opracowanie nowego
schematu).
- System powinien określać urządzenia i nośniki
dla danych, ale tylko na etapie sterowania buforami
i zajmować się organizacją przepełnień.
Administrator bazy danych i jego funkcje:
Ponieważ dane w bazie są wykorzystywane przez
wiele programów stąd konieczność centralizacji
opracowywania schematu, a czasem również
podschematu. Konieczność połączenia programów
użytkowych to należy do administratora.
Funkcja administratora polega na utworzeniu i
obsłudze bazy oraz jej schematu tak, aby programy
użytkowe mogły efektywnie zaspokajać swoje
potrzeby.
Od administratora ze strony organizacyjnej
wymagamy:
- utworzenie schematu opisującego bazę i
wprowadzenie do systemu zarządzania bazą.
- utworzenie schematu pamiętania i wprowadzenie
do systemu zarządzania bazą danych.
- załadowanie samej bazy danych.
- określenie zasad kontroli dostępu do bazy w
szczególności zamki kontroli dostępu w
szczególności dostęp pojedynczych użytkowników
poprzez określenie zamków kontroli dostępu i
przydzielenie kluczy dostępu.
- określenie urządzeń i nośników danych dla bazy.
-Monitorowanie wykorzystania i wydajności
Zbierania danych statystycznych dotyczących
wykorzystania różnych części czy różnych
elementów bazy.
Prowadzenie protokołów zmian w bazie, dla jej
odtworzenia w przypadku błędu systemu lub
użytkownika.
-Reorganizacja i restrukturyzacja bazy w celu
zwiększenia wydajności
administrator musi dokonać zmiany schematu i
skompilować zmiany w celu uzyskania nowej
wersji schematu (to samo z podschematem)
Konieczność zmian jeśli dojdą nowe elementy,
zapotrzebowania.
Schemat pamiętania zmiana schematu, aby
otrzymać nowy schemat pamiętania.
Zmiana samej bazy, aby była zgodna ze
schematem i schematem pamiętania
Usunięcie zbędnych rekordów, które stały się
zbędne lub niedostępne i uwzględnienie zwolnienia
fragmentów pamięci.
Rozmieszczenie danych na różnych nośnikach i
urządzeniach uwzględniając czasy dostępu,
zużycie fizyczne nośników itd. Ewentualny
wydruk wybranych fragmentów bazy.
- Odtwarzanie bazy danych po błędach lub
awariach systemu,
7
administrator musi zrealizować składowanie
części bazy w pamięci pomocniczej
(archiwizowanie części bazy).
- Odtwarzanie części bazy z uwzględnieniem
protokołów zmian.
Podstawowe procedury struktury bazy
– obecność pewnych specyficznych operacji dla
konkretnej bazy danych, przykładowo sprawdzenie
poprawności kluczy dostępu.
- obliczanie wartości danych elementarnych jako
funkcji wartości innych danych elementarnych
- realizacja algorytmów wyszukiwania
- algorytmy pakowania lub rozpakowywania
wartości danych elementarnych
- realizacja obliczeń za pomocą środków
systemowych
Procedury te muszą mieć dostęp do
- identyfikatora procesu, z którego zostało
przekazanie sterowanie do procedury bazy danych.
- typu funkcji języka manipulowania danymi, z
której sterowanie zostało przekazane do procedury
bazy danych
-typu zadania lub frazy, z którego nastąpiło
przekazanie sterowania
-W specyficznych sytuacjach do całej informacji
dostępnej procesowi, z którego przekazano
sterowanie do procedury bazy danych, czyli do
obszaru roboczego użytkownika danego procesu,
do wskaźników stanu również do rejestrów i
wszystkich danych w bazie.
Procedury bazy powinny mieć możliwość
przekazywania informacji do tego procesu, z
którego przekazano im sterowanie.
Ochrona danych
Sam schemat BD powinien przewidywać środki
ochrony:
1. ochrona przed nieupoważnionym
dostępem do danych (kontrola dostępu).
Realizuje się na różne sposoby, najczęściej
realizowany jako mechanizm wzajemnie
uzupełniających się zamków określanych w
schemacie oraz kluczy, które powinny być podane
przez proces, który chce otrzymać prawo dostępu
do zamkniętych danych. W zależności od środków,
którymi dysponuje podschemat i zależnie od
charakteru procesu klucze mogą być przekazywane
do podschematu przez sam proces lub interakcyjnie
przez użytkownika procesu.
Klucz dostępu jest wartością, której typ i zakres
określa implementator. Klucz może być wartością
stałą, zmienną lub wynikiem obliczenia procedury.
Zamek dostępu jest albo wartością albo procedurą.
Gdy zamek jest wartością (stałą lub zmienną) to
dla uzyskania dostępu do danych wymagana jest
zgodność klucza. Gdy jest procedurą to
wykorzystuje klucz, aby decydować, czy dane
należy otworzyć.
Działanie procedury zależy od implementatora a
także przy tworzeniu schematu powinien mieć
również wpływ administrator bazy.
Zadania (ochrona).
- Przeprowadzenie obliczeń z wykorzystaniem
klucza i na tej podstawie sprawdzanie
poprawności klucza.
- Rozwiązanie interakcyjne – dialog z osobą
pracującą przy terminalu i otrzymanie odpowiedzi
na szereg pytań, i na tej podstawie udostępnienie
danych po zidentyfikowaniu.
- Zapisywanie do procesu nowej wartości klucza
(zmiana klucza po każdym udostępnieniu
danych).
- Gdy nastąpiło naruszenie ochrony danych, to
wówczas system powinien rejestrować taki
przypadek, konieczne jest wysłanie sygnału
alarmowego do administratora bądź operatora
bazy(jeżeli została taka osoba powołana).
- Przewiduje się również przy powtórnym
naruszeniu danych natychmiastowe przerwanie
procesu.
- (Rzadko) Stosuje się chwilowe wstrzymanie
procesu w celu uzyskania potwierdzenia prawa
dostępu.
- Odłączenie terminala użytkownika i żądanie
powtórnego logowania przed udostępnieniem
prawa dostępu.
Procedura bazy danych musi mieć możliwość
identyfikacji procesu (ingerowanie w system).
2.ochrona przed pojawieniem się sprzecznych
lub nieprawdziwych danych (kontrola
integralności).
DDL umożliwia pewną specyfikację powiązań w
strukturach BD.
- Należy przewidzieć środki kontroli poprawności
danych (w szczególności danych elementarnych).
- Gdy sam proces próbuje modyfikować rekord
lub kolekcję, SZBD powinien sam przeprowadzać
kontrolę procedur i odpowiednich wywołań.
Za każdym razem gdy do bazy wprowadzana jest
dana lub zostaje zmieniana mówimy o
wprowadzaniu danych elementarnych.
Rozproszone bazy danych.
Rozproszony system BD to system, w którym
występuje
rozłożenie
danych
przez
ich
fragmetaryzację (podział) lub repliakcję do
różnych konfiguracji sprzętowych i programowych
rozmieszczonych fizycznie w różnych miejscach.
Fragment danych stanowi podzbiór danych.
Replikacja stanowi kopię całości lub części
danych, przechowywanych w innej części BD.
O rozproszeniu możemy również mówić w
odniesieniu do funkcji, a rozproszenie funkcji
dotyczy całej strategii klient – serwer i baz danych
tego typu.
Fragmentaryzację i replikację stosuje się przez
zastosowanie
operatorów
lub
rachunku
relacyjnego.
Zasadniczym celem rozproszonej BD jest to, aby
dla
użytkownika
wyglądała
jak
jedna
scentralizowana BD. Możemy mówić o trzech
strategiach przezroczystości BD:
1. przezroczystość geograficzna - użytkownik
nie musi wiedzieć, gdzie są przechowywane dane
2. przezroczystość fragmentaryzacji użytkownik nie musi wiedzieć, w jaki sposób
dane zostały podzielone
3.przezroczystość replikacji - użytkownik nie
musi wiedzieć, w jaki sposób dane są powielane.
Zalety i wady rozproszenia
+ dostosowanie do struktury organizacyjnej
organizacji przedsiębiorstwa (firmy)
+ większa kontrola nad danymi, dlatego, że można
je przechowywać w jednym miejscu, w którym
mogą być modyfikowane przez odpowiednio
upoważnione osoby
+ utrzymanie replikacji, co zwiększa niezawodność
systemu (dotyczy banków – dwie bliźniacze bazy)
+ zwiększenie efektywności przez poprawne
rozproszenie danych, większość zapytań będzie do
lokalnej (mniejszej) bazy, niż do dużej
(scentralizowanej)
- RBD są bardziej skomplikowane od
scentralizowanych BD
- trudność w efektywnym zarządzaniu bazą
Wszystkie te elementy wynikają z komunikacji
sieciowej.
System zarządzania rozproszoną bazą danych musi
być bardziej skomplikowany niż w przypadku bazy
scentralizowanej.
- Katalog systemowy rozproszonej bazy danych
jest bardziej złożony i musi obejmować więcej
informacji, np. informacje o położeniu fragmentów
bazy, jak i replikacji.
- Kolejny problem wynika ze zwielokrotnienia
problemu ze współbieżnością i aktualizacją
szeregu różnych węzłów.
Dla efektywności można stworzyć optymalizator
zapytań, który powinien używać informacji
topologicznych o sieci, decydując jak najlepiej
wykonać dane zapytania.
Aby zapewnić większą odporność na awarie, to
system zarządzania rozproszoną bazą danych nie
powinien być ulokowany w jednym miejscu
(zarówno oprogramowanie, jak i konkretne dane w
różnych miejscach).
Wyróżnia
się
cztery
podstawowe
typy
rozproszonych baz danych:
1. system klient-serwer
Termin system klient-serwer narodził się wraz z
pojawieniem się lokalnych sieci. Baza danych na
ogół była przechowywana na serwerze, natomiast
interfejs użytkownika i narzędzia tworzenia
aplikacji znajdowały się na komputerach klientów.
Tak jak do dziś w niektórych sieciach.
2. jednorodna rozproszona baza
W jednorodnej rozproszonej bazie dane są
rozłożone między dwa lub więcej systemów.
Każdy jest oparty na tym samym rodzaju systemu
zarządzania bazą danych (Oracle). Również na
ogół ten typ działa na tego samego rodzaju sprzęcie
i również pracuje pod nadzorem takiego samego
systemu operacyjnego.
3. niejednorodna rozproszona baza
W niejednorodnych rozproszonych bazach danych
konfiguracje sprzętowe i oprogramowania są
różne.
Obecnie
podstawowym
sposobem
uzyskiwania niejednorodnego systemu jest łącze
gateway. Jest to interfejs z jednego systemu
zarządzania BD do drugiego, w praktyce bywa
dostarczane
przez
jednego
konkretnego
producenta.
4. federacyjny system baz danych
Federacyjny system składa się z pewnej liczby
względnie autonomicznych baz, w których
niekiedy zachodzi konieczność zebrania części
danych lub całości aby wykonać wspólną funkcję.
Wykorzystuje się tu systemy otwarte z
wykorzystaniem odległych systemów. W praktyce
jest on słabo rozwinięty, trwają prace.
System klient-serwer to specjalna architektura
oprogramowania, w której dwa systemy
współdziałają ze sobą w rolach nadrzędniepodrzędnych.
Proces
klienta
rozpoczyna
współdziałanie przez wysłanie zapotrzebowania.
Proces serwera realizuje to zapotrzebowanie i
odpowiada na złożone zapotrzebowanie.
Teoretycznie klient i serwer mogą znajdować się
na tym samym komputerze, w praktyce raczej na
oddzielnych komputerach.
Dla konkretnych aplikacji wyróżnia się cztery
podstawowe części:
1.zarządzanie danymi – jest to cała gama funkcji,
które zarządzają danymi dla aplikacji, w tym
zarządzają transakcjami i współbieżnością oraz
przechowywaniem danych i zabezpieczeniami.
2.zarządzanie regułami – gama funkcji,
zapewniających zachodzenie wewnętrznych i
innych dodatkowych warunków spójności danych.
3. logika aplikacji – zaliczamy te funkcje, które
przekształcają dane i zgłaszają zapotrzebowanie na
usługi dla serwerów i innego oprogramowania
znajdującego się na komputerach klientów.
4.zarządzanie i logika prezentacji – funkcje,
które przyjmują dane i zapotrzebowania od
użytkownika
oraz
przedstawiają
dane
użytkownikowi. Oprogramowanie do prezentacji
przekształca dane wyjściowe w postać wymaganą
przez serwer i odwrotnie z serwera w postać
dogodną dla użytkownika.
W
systemach
klient-serwer
dochodzi
oprogramowanie
łączące
–
jest
ono
przezroczystym łącznikiem, który łączy aplikację
klienta z danymi serwera. Dane z serwera są
danymi lokalnymi dla aplikacji na komputerze
klienta.
Oprogramowanie
łączące
używa
oprogramowania sieciowego w celu wymiany
komunikatów między klientem a serwerem.
Przy projektowaniu efektywnych systemów klientserwer należy:
8
1.umieścić jak najwięcej logiki szczególnie
związanej z prezentacją na komputerach klienta,
przyspiesza to współpracę z użytkownikiem,
zmniejsza obciążenie serwera.
2.umieścić
sprawdzanie
niektórych
reguł
zwłaszcza
tych
dotyczących
poprawności
wprowadzanych danych na komputerze klienta.
3.dążyć do zminimalizowania ruchu w sieci
poprzez ograniczenie liczby i rozmiaru zgłoszeń na
usługi serwera.
4.umieszczać sprawdzanie istotnych dla całej
organizacji (firmy) reguł na serwerze.