Relacyjne bazy danych
W roku 1970 dr Edgar Ted Codd z firmy IBM zaprezentował
relacyjny model danych. W modelu tym dane miały być
przechowywane w prostych plikach liniowych, które to pliki
nazywane są "relacjami" bądź "tabelami". Jedną z największych
zalet modelu relacyjnego w stosunku do poprzedników jest jego
prostota. Zamiast konieczności poznawania mnóstwa komend
języka DML, model relacyjny wprowadził język SQL w celu
ułatwienia dostępu do danych i ich modyfikacji.
Tabele są dwuwymiarowymi tablicami składającymi się z
wierszy i kolumn. Wiersze nazywane są czasami krotkami (ang.
tuples), natomiast kolumny atrybutami. Rekord jest wierszem
tabeli, a pole jest kolumną w wierszu tabeli. Tabela posiada
zawsze pole lub kilka pól, tworzące dla niej klucz główny (ang.
primary key). W relacyjnych bazach danych tabele są
niezależne, w przeciwieństwie do modeli hierarchicznego i
sieciowego, gdzie występują połączenia wskaźnikowe. Tabele
relacyjne mogą zawierać tylko jeden typ rekordu, natomiast
każdy rekord posiada stałą liczbę wyraźnie nazwanych pól.
Klucz główny jednoznacznie identyfikuje wiersz w tabeli.
Klucz ten może zostać stworzony na podstawie jednego lub
kilku pól.
Klucz obcy (ang. foreign key), którego wartością jest wartość
pewnego klucza głównego, pozwala na łączenie tabel między
sobą.
1
Relacyjne bazy danych wprowadziły następujące
ulepszenia w stosunku do hierarchicznych i sieciowych
baz danych:
-
Prostota.
Podejście bazujące na tabelach z wierszami i kolumnami jest
niezwykle proste i łatwe do zrozumienia. Końcowi użytkownicy
mają prosty model danych. Złożone diagramy, wykorzystywane
w przypadku hierarchicznych i sieciowych baz danych, nie
występują w przypadku relacyjnych baz danych.
-
Niezależność danych.
Niezależność danych pozwala na modyfikowanie struktury
danych bez wpływu na istniejące programy. Jest to możliwe
głównie dlatego, że tabele nie są ze sobą połączone na sztywno.
Do tabel mogą być dodawane kolumny, tabele mogą być
dołączane do bazy danych, a nowe relacje mogą być tworzone
bez konieczności wprowadzania istotnych zmian do tabel.
Relacyjne bazy danych dostarczają dużo wyższy poziom
niezależności danych, niż hierarchiczne i sieciowe bazy danych.
-
Deklaratywny język dostępu do danych.
Dzięki wykorzystaniu języka SQL, użytkownik określa jedynie
warunki odnośnie poszukiwanych danych, system natomiast
zajmuje się pobraniem danych spełniających żądanie. Nawigacja
w bazie danych jest ukryta przed użytkownikiem końcowym, w
odróżnieniu od języka DML w systemie CODASYL, gdzie
użytkownik musi znać wszelkie szczegóły określające ścieżkę
dostępu do danych.
2
Obiektowe bazy danych
Technologia obiektowa rozwija się i rozprzestrzenia w bardzo szybkim tempie. W ostatnich
latach również w technologii baz danych wyraźnie obserwuje się ogólny trend w kierunku
koncepcji obiektowej.
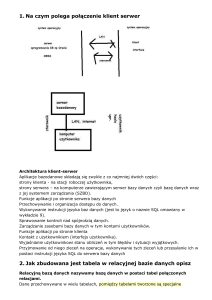
Architektura
Istnieje kilka koncepcji odnośnie architektury obiektowego systemu
zarządzania bazą danych. Najbardziej abstrakcyjną jest architektura
zaproponowana przez komitet ANSI/SPARC. Wyróżnia ona trzy
poziomy:
• poziom pojęciowy systemu, wspólny dla wszystkich jego
użytkowników,
• poziom zewnętrzny, specyficzny dla konkretnego użytkownika,
• poziom fizyczny, który odnosi się do implementacji bazy
danych.
Kolejnym rodzajem jest architektura klient-serwer, gdzie występuje
podział na dwie części: serwer bazy danych, wykonujący przykładowo
wyrażenia SQL wysyłane przez klientów oraz druga część, którą
stanowi jeden lub kilku klientów wysyłających żądania do serwera.
Bardziej zaawansowane są architektury trzywarstwowa oraz
wielowarstwowa. Jak sama nazwa wskazuje, architektura
trzywarstwowa charakteryzuje się podziałem na trzy warstwy: interfejs
użytkownika, logikę przetwarzania oraz bazę danych. Warstwy te są
zaprojektowane i istnieją niezależnie, co ma duże znaczenie dla
utrzymania całego systemu ze względu na możliwość zmian w dowolnej
warstwie bez konieczności interwencji w pozostałych warstwach.
Warstwa środkowa może być złożona z kilku warstw i mamy wówczas
do czynienia z architekturą wielowarstwową.
Poniższy rysunek pokazuje typową architekturę obiektowego systemu
zarządzania bazą danych ujętą z funkcjonalnego punktu widzenia
3
RYSUNEK . PRZYKŁADOWA ARCHITEKTURA OBIEKTOWEGO SYSTEMU
ZARZĄDZANIA BAZĄ DANYCH (OSZBD).
4
Bazy danych -anatomia
Baza danych - zbiór wzajemnie powiązanych
przechowywanych w pamięci zewnętrznej komputera.
informacji
System zarządzania bazą danych (SZBD) - oprogramowanie
umożliwiające korzystanie z informacji znajdujących się w bazie
danych.
Funkcje SZBD:
• opis struktury danych przechowywanych w bazie – jakie dane są
przechowywane, jak są ze sobą powiązane,
• korzystanie z bazy – wyszukiwanie danych, modyfikacja,
dopisywanie, kasowanie,
• tworzenie aplikacji bazodanowych – korzystających z danych
przechowywanych w bazie,
• zapewnienie poprawności danych przechowywanych w bazie –
poprzez definiowanie warunków, które muszą być zawsze spełnione w
bazie danych;
• zapewnienie poufności danych – ochrona danych przed
użytkownikami nie mającymi uprawnień do korzystania z bazy,
• współbieżność dostępu – mechanizmy umożliwiające wielu
użytkownikom korzystanie w tym samym czasie z danych
zgromadzonych w bazie,
• niezawodność – mechanizmy umożliwiające przywrócenie
poprawnego stanu bazy danych po awarii systemu komputerowego.
5
Kartotekowe bazy danych
Kartotekową bazę danych stanowi szereg rekordów umieszczonych w
pliku dyskowym.
Przykład – baza dotycząca towarów
Nazwa
Cena
Symbol
Opak_jedn Gatunek Ilość_opak
Mąka
1,32 TOW-112
1
1
1500
Makaron3,50 TOW-450
0,40
1
250
nitki
Rodzynki
0,98 TOW-443
0,1
2
120
Cukier
1,75 TOW-765
1
2
680
Ryż
2,05 TOW-665
0,5
1
700
•
•
•
•
Każdy rekord składa się z pól;
Pola mogą być różnego typu;
Pojedynczy rekord opisuje jeden obiekt rzeczywisty;
Podstawowe operacje – dopisanie, modyfikacja, usunięcie rekordu;
przeglądanie zawartości bazy
Wyszukiwanie i porządkowanie danych ułatwiają indeksy.
Przykład – indeks umożliwiający wyszukiwanie i porządkowanie
towarów ze względu na nazwę
Nazwa
Cukier
Makaronnitki
Mąka
Rodzynki
Ryż
Pozycja
4
2
1
3
5
6
Relacyjne bazy danych
Relacyjna baza danych - zbiór nieuporządkowanych tabel, którymi
można manipulować używając operacji zwracającej jako wynik całe
tabele.
Przykładowa baza danych utworzona w systemie MS Access.
7
A1. Opis struktury danych. Definiowanie Tabel.
Tabela Uczniowie
•
•
•
•
Każda tabela ma swoją nazwę.
Wiersze tabeli = rekordy = krotki.
Kolumny tabeli = cechy = pola = atrybuty.
W tabeli nie mogą wystąpić dwa identyczne wiersze – unikalność
wiersza zapewnia się poprzez zdefiniowanie klucza podstawowego.
• Klucz podstawowy – jedno lub więcej pól, których wartość
jednoznacznie identyfikuje każdy rekord w tablicy. Zawiera unikalne
wartości (np. numer PESEL lub numer dowodu osobistego, numer
albumu studenta).
8
Tabela Przedmioty
Tabela Oceny
9
A2. Opis struktury danych. Powiązania (relacje) pomiędzy tabelami
W bazie danych definiuje się związki pomiędzy danymi znajdującymi
się w różnych tablicach (związki =relacje).
Definicja relacji polega na wskazaniu pól pochodzących z różnych tabel
i zawierających powiązane ze sobą dane. Zwykle powiązane ze sobą
pola mają identyczne nazwy.
Przy definiowaniu relacji wykorzystuje się:
• w jednej tabeli – klucz podstawowy,
• w drugiej tabeli – klucz obcy.
Klucz podstawowy – pole, którego wartość jednoznacznie identyfikuje
każdy rekord w tabeli.
Klucz obcy – pole, które odwołuje się do klucza podstawowego w innej
tabeli.
Powiązanie Uczniowie – Oceny:
• Uczniowie.NumerUcznia –klucz podstawowy
• Oceny.NumerUcznia – klucz obcy.
Powiązanie Przedmioty – Oceny:
• Przedmioty.KodPrzedmiotu – klucz podstawowy
• Oceny.KodPrzedmiotu – klucz obcy.
10
Powiązanie Uczniowie - Oceny
Tabela Oceny – NumerUcznia jest kluczem obcym. W bieżącym
rekordzie wartość klucza obcego wynosi 4.
Tabela Uczniowie – NumerUcznia jest kluczem podstawowym.
Rekordem bieżącym staje się ten rekord, w którym wartość klucza
podstawowego jest równa wartości klucza obcego w powiązanej tabeli.
Zastosowanie odwołania do rekordu z powiązanej tabeli – zamiast
numeru ucznia wyświetlane jest nazwisko pobrane z powiązanego
rekordu.
11
Typy związków zachodzących pomiędzy tablicami
• 1 – 1 (powiązanie typu jeden do jednego) – każdy rekord w tablicy A
może mieć tylko jeden dopasowany rekord z tablicy B, i tak samo
każdy rekord w tablicy B może mieć tylko jeden dopasowany rekord z
tablicy A.
• 1 – N (powiązanie typu jeden do wielu) – rekord w tablicy A może
mieć wiele dopasowanych do niego rekordów z tablicy B, ale rekord
w tablicy B ma tylko jeden dopasowany rekord w tablicy A.
12
• M – N (powiązanie typu wiele do wielu) – rekord w tablicy A może
mieć wiele dopasowanych do niego rekordów z tablicy B i tak samo
rekord w tablicy B może mieć wiele dopasowanych do niego
rekordów z tablicy A.
13
Inne rozumienie pojęcia „relacyjna baza danych”
Tabele nazywane są relacjami (stąd nazwa relacyjna baza danych).
Pojęcie iloczynu kartezjańskiego zbiorów
A = {Jacek, Wojtek, Krzysiek}
B = {Marta, Krysia}
Iloczyn kartezjański zbiorów A i B jest zbiorem wszystkich par
elementów (a, b), gdzie a należy do zbioru A, zaś b należy do zbioru B.
A × B = {(Jacek, Marta), (Jacek, Krysia), (Wojtek, Marta), (Wojtek,
Krysia), (Krzysiek, Marta), (Krzysiek, Krysia)}
Podzbiór iloczynu kartezjańskiego nazywany jest relacją.
Obiekty:
• opisywane są przez atrybutu (cechy) – w tablicy atrybutom
odpowiadają kolumny,
obiektem jest opis przedmiotu,
cechy charakteryzujące obiekt: KodPrzdmiotu, NawaPrzedmiotu,
Prowadzący
14
• każdy atrybut ma określoną dziedzinę (zbiór dopuszczalnych
wartości),
dziedzina cechy KodPrzedmiotu: zbiór liczb całkowitych dodatnich
dziedzina cechy NazwaPrzedmiotu: Historia, Geografia, Plastyka,
Język Polski, Fizyka, Matematyka
dziedzina cechy Prowadzący: Igrekowski1, Igrekowski2, Igrekowski3,
Igrekowski4, Igrekowski5, Igrekowski6.
• iloczyn kartezjański dziedzin atrybutów
możliwych kombinacji wartości atrybutów,
–
zbiór
wszystkich
zbiór wszystkich możliwych trójek:
[wartość cechy KodPrzedmiotu, wartość cechy NazwaPrzedmiotu,
wartość cechy Prowadzący]
[1, Historia, Igrekowski1]
[1, Historia, Igrekowski2]
[1, Historia, Igrekowski3]
...
• zawartość tabeli jest zwykle podzbiorem zbioru wszystkich
możliwych kombinacji wartości atrybutów – czyli jest podzbiorem
iloczynu kartezjańskiego zbiorów dziedzin kolejnych atrybutów –
czyli jest relacją.
15
• Tabela = relacja
• Wiersz tabeli = krotka – opisuje pojedynczy obiekt świata
rzeczywistego;
• Kolumna tabeli = atrybut – cecha opisująca obiekt.
Stosując terminologię właściwą dla kartotekowych baz danych można
powiedzieć:
• Tablica = plik,
• Wiersz tablicy = rekord;
• Kolumna tablicy = pole rekordu.
B. Korzystanie z bazy
Podstawowe sposoby korzystania z danych to:
• wyszukiwanie danych (definiowanie zapytań kierowanych do bazy;
wynikiem realizacji zapytania są informacje pochodzące z bazy),
• modyfikacja danych (zmiana zawartości bazy danych: aktualizacja,
dopisywanie, usuwanie).
Sposoby realizacji operacji wyszukiwania i modyfikacji danych:
• przy pomocy narzędzi komunikujących się przy pomocy interfejsu
graficznego
• przy pomocy języków operowania danymi.
16
Operowanie na danych przy pomocy interfejsu graficznego
Operowanie przy pomocy języka operowania danymi
Najpopularniejszym językiem operowania danymi jest język SQL
(Structured Query Language - strukturalny język zapytań),
zaprojektowany pod koniec lat siedemdziesiątych w firmie IBM. Jest on
światowym standardem służącym do operowania relacyjnymi bazami
danych, jest on częścią składową większości systemów obsługi
relacyjnych baz danych.
17
B1. Wyszukiwanie danych
Wyróżnia się trzy podstawowe rodzaje zapytań służących do
wyszukiwania danych (są to tzw. kwerendy wybierajace):
• projekcja (wybór tylko niektórych pól /atrybutów, cech, kolumn/),
• selekcja (wybór rekordów /wierszy/ spełniających określony
warunek),
• łączenie (scalania danych pochodzących z różnych tabel).
Projekcja
Z tabeli Uczniowie
chcemy wybrać informacje przechowywanych w polach: Imię, Nazwisko
18
Definicja projekcji:
Wynik projekcji:
Definicja projekcji przy pomocy języka SQL:
SELECT lista_pól FROM nazwa_tablicy
SELECT Uczniowie.Imię,
Uczniowie;
Uczniowie.Nazwisko
FROM
SELECT * FROM Uczniowie;
19
Operacja selekcji
Wynik selekcji:
SELECT
lista_pól
FROM
nazwa_tablicy
warunek ORDER BY sposób_sortowania
WHERE
SELECT Oceny.* FROM Oceny WHERE Oceny.Ocena>3
ORDER BY Oceny.Ocena DESC;
20
Łączenie danych z różnych tablic
Wynik zapytania:
SELECT
Uczniowie.Imię,
Uczniowie.Nazwisko,
Oceny.Ocena FROM Uczniowie, Oceny
WHERE (Oceny.Ocena>3) AND
(Uczniowie.NumerUcznia=Oceny.NumerUcznia)
ORDER BY Oceny.Ocena DESC;
21
B2. Modyfikacja danych
Aktualizacja wartości przechowywanych w tabeli
Kwerenda aktualizująca – narzędzie do modyfikacji danych
Podwyższenie ocen niższych od 3.0 o jeden stopień
Kwerenda aktualizująca w języku SQL:
UPDATE Oceny SET Oceny.Ocena = Oceny.Ocena + 1
WHERE (Oceny.Ocena<3);
22
Kasowanie danych
Narzędziem do usuwania danych są kwerendy usuwające
Usunięcie ocen ucznia, któremu przyporządkowany jest numer równy 1.
Kwerenda usuwająca w języku SQL:
DELETE Oceny.* FROM Oceny
WHERE Oceny.NumerUcznia=1;
C. Tworzenie aplikacji bazodanowych
Formularze
23
Raporty
Programy
24
D. Zapewnienie poprawności danych przechowywanych w bazie
1. Definiowanie warunków poprawności dla danych przechowywanych
w bazie – dotyczą one danych wprowadzanych do pól w tabelach lub
w formularzach.
Reguła poprawności dla pola Ocena w tablicy Oceny
2. Zapewnienie poprawności powiązań danych znajdujących się w
różnych tabelach
Integralność referencyjna (spójność referencyjna) – poprawność
powiązań danych pochodzących z różnych tabel. Warunkiem
zapewnienia integralności referencyjnej jest spełnienie następujących
reguł:
25
Warunki zapewniające integralność referencyjną:
a) W polu klucza obcego w tabeli sprzężonej nie można wprowadzać
wartości nie istniejących w polu klucza podstawowego tabeli
podstawowej.
b) W tabeli podstawowej nie można usunąć rekordu, jeśli istnieją
powiązane z nim rekordy w tabeli sprzężonej.
c) W tabeli podstawowej nie można zmienić wartości klucza
podstawowego, jeśli istnieją powiązane z nim rekordy.
26
E. Zapewnienie poufności danych
Zabezpieczanie danych poprzez hasło
Ochrona tylko w chwili otwierania bazy
Zabezpieczanie na poziomie użytkownika
Dla każdego użytkownika bazy definiuje się zakres jego uprawnień.
27
F. Współbieżność dostępu
Baza danych może być użytkowana:
• przez jednego użytkownika,
• przez wielu użytkowników.
Wielu użytkowników może korzystać w tym samym czasie z tej samej
bazy danych.
Problemem może być próba jednoczesnej modyfikacji tego samego
rekordu przez dwóch użytkowników. Mechanizmem zabezpieczającym
przed powstawaniem konfliktów tego typu jest blokowanie.
Blokowanie
–
użytkownikowi.
udostępnianie
rekordu
wyłącznie
jednemu
28
Rozproszone bazy danych
Dane przechowywane są i przetwarzane w różnych punktach, które są
zwykle znacznie od siebie oddalone i połączone liniami
telekomunikacyjnymi.
• użytkownicy wykorzystują kopie (repliki) bazy danych – ułatwiony
dostęp, krótszy czas dostępu, redukcja kosztów transmisji danych,
zwiększona niezawodność.
• rodzaje replik: całościowe i częściowe (kopia zawierająca pewien
podzbiór bazy danych).
• Zalety replik częściowych: zawierają wyłącznie dane potrzebne w
danym węźle, zajmują mniej miejsca na dysku, ograniczają dostęp do
danych, czas transmisji jest krótszy.
• Synchronizacja replik – przesyłanie pomiędzy replikami informacji o
wprowadzonych zmianach.
G. Niezawodność bazy danych
• mechanizmy do naprawy bazy danych – naprawa indeksów, połączeń.
• transakcje – seria zmian wykonanych na danych. Operacje składające
się na transakcję mogą zostać zatwierdzone lub wycofane.
• archiwizacja danych.
29