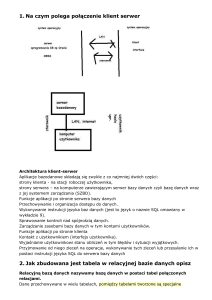
RELACYJNE BAZY DANYCH, SCHEMAT
RELACJI, SELEKCJA, PROJEKCJA
CEL NAUCZANIA:
Wykonywać obliczenia i opracowania graficzne z
wykorzystaniem programów komputerowych
Osiągnięcia:
Rozróżnić selekcję od projekcji. Wymienić typy
pól.
Ogólne zagadnienia relacyjnych baz danych
• Relacyjna baza danych oparta jest zwykle o
kilka tablic danych, które powiązane są ze
sobą przez pole o wspólnej nazwie.
Przykładem może być baza hurtowni,
zawierająca dane o klientach, towarach i
wystawionych fakturach.
Wszystkie te tabele pozwalają na
wprowadzanie danych, przechowywanie w
pamięci masowej, sortowanie, wyszukiwanie,
wydruk.
Relacyjne bazy danych
• Bazy relacyjne - prawie najpopularniejsze bazy danych.
W relacyjnych bazach danych wykorzystano teorię
algebry relacji.
Tabele składają się z rekordów, zaś rekordy z pól
ale różnica w stosunku do baz kartotekowych polega na tym,
że baza może zawierać kilka tabel (lub plików)
które to różnią się strukturą rekordów.
Pomiędzy rekordami jest określona pewna
relacja porządkująca.
Możliwe jest łączenie rekordów z różnych tabel,
jeśli rekordy takie mają przynajmniej jedno pole wspólne.
Relacja
• Relacja - podstawowowa forma organizacji danych w bazie
- zbiór rekordów (krotek)
Relacja - skończony zbiór krotek (rekordów)
r(A1,...,An) = {<a1,..,an>: a1 (- dom(A1), .. an (- dom(An)}
gdzie: r(A1,..,An) jest relacją
określoną na schemacie relacji R(A1,...,An)
A1, A1, …An – atrybuty (pola relacji)
Przykładową relacją jest
{<Kowalski, Jan, 35, 1200>, <Nowak, Piotr, 36,
2000>, <Zielińska, Anna, 25, 1400>}
Krotki relacji nie są uporządkowane,
można zmieniać ich kolejność.
Relacyjna bazą danych
• Relacyjną bazą danych nazywamy bazę danych w postaci
tabel połączonych relacjami.
Dane przechowywane w wielu tabelach, pomiędzy tabelami
tworzone są specjalne powiązania zwane relacjami.
• Relacje powiązania tworzone są pomiędzy odpowiednimi
polami rekordów różnych tabel.
Relacje tworzy się pomiędzy tabelami baz danych za pomocą
klucza podstawowego jednej tabeli i odpowiedniego
klucza obcego drugiej tabeli.
• Relacja - powiązanie miedzy tabelami Bazy Danych
za pomocą klucza podstawowego jednej tabeli
i klucza obcego drugiej tabeli
Baza danych: DANE i SCHEMAT
• Dane opisują cechy obiektu.
• Schemat jest opisem struktury przechowywanych danych oraz
powiązań wzajemnych między nimi.
• Przykładowe struktura informacji dot. grup studenckich:
1) Studenci
Tabela STUDENT (Nazwisko, NrIndeksu, Rok, Kierunek)
- schemat
Dane: Nowak, 18175, I, informatyka
Kowalik, 33573, II, telekomunikacja
2) Prowadzone wykłady
Tabela: WYKŁAD (Nazwa, Nr, Godziny, Prowadzący)
Dane: Języki programowania, CS201, 8, Misiak
Bazy danych, C8100, 8, Pilecki
3) Grupy studenckie
Tabela: GRUPA (NrGrupy, NrWykładu, Semestr, Rok)
Dane: 85, CS201, letni, 96
92, CS445, zimowy, 96
4) Oceny z zaliczeń modułów dydaktycznych
Tabela: OCENY (NrIndeksu, NrGrupy, NrWykładu, Ocena)
Dane: 18175, 92, CS100, 4
19551, 101, CS445, 5
Model relacyjny
• Bazy relacyjne
Prawie najpopularniejsza grupa baz danych.
Model wykorzystywany najczęściej przy projektowaniu baz danych.
Dane przechowywane w wielu tabelach, pomiędzy tabelami
tworzone są specjalne powiązania zwane relacjami.
• Przykład: Tabele: Pracownik, Zespół, Etat
Tabele i rekordy
• Dane przechowywane są w formie
strukturalnej.
• Każda informacja zapisywana jest w
podstawowym elemencie jakim jest rekord.
Rekordy są podzielone na pola.
• Każde pole ma swoją nazwę, wielkość oraz
definicję typu danych, jakie będą umieszczone.
• Główne typy pól: znakowe, numeryczne,
datownikowe, logiczne, notatnikowe.
Tabela, rekord, pole
• Tabelą w bazie danych nazywamy zbiór
rekordów opisujących obiekty
np. pracownicy zawierających informacje o
tych obiektach w sposób ujednolicony.
• Rekord – pojedynczy wiersz w tabeli.
• Pole - najmniejszą część rekordu, która
przechowuje jedną daną.
Tabela
• Tabela to zbiór powiązanych ze sobą danych.
Jest to układ poziomych wierszy
zwanych rekordami
i pionowych kolumn zwanych polami rekordu.
• Tabela jest identyfikowana przez nazwę.
• Przecięcie kolumny i wiersza tworzy pole.
Nazwa kolumny jest jednocześnie nazwą pola.
Baza danych
• Baza danych składa się z tabel,
tabele składają się z rekordów,
rekordy składają się z pól.
• Pola mogą przechowywać elementarne dane,
które są niepodzielne,
czyli zakładamy, że mniejszych jednostek
danych nie ma.
Typ danej (ang. data type)
•
•
•
•
•
•
•
•
•
•
•
znakowy (ang. character) – dana może przybierać tylko wartości znaków pisarskich
liczbowy (ang. number) – dana może przechowywać tylko liczby
logiczny (ang. logical) – dana może przybierać tylko dwie wartości: prawda, fałsz
(tak, nie)
data (ang. date) – dana może przyjmować postać daty i czasu
np. rok.miesiąc.dzień; godz:min:sek
alfanumeryczny (ang. alphanumeric) – dana może przybierać wartości znaków ASCII
oraz cyfry
numeryczny (ang. numeric) – wartościami danej mogą być tylko cyfry
i znaki: + (plus), - (minus).
walutowy (ang. currency) – dana może przyjmować wartości liczbowe
razem z symbolem waluty
notatnikowy (ang. memo) – dana może być oddzielnym zbiorem tekstowym
służącym do przechowywania dowolnych opisów.
binarny (ang. binary) – dana może być np. plikiem dźwiękowym lub filmowym.
graficzny (ang. graphic) – dana przechowuje grafikę np. rysunki.
obiektowy (ang. OLE) – dana przechowuje obiekty do których dostęp dokonuje się
za pomocą techniki OLE (ang. object linking and embeding), czyli obiektów
tworzonych przez inne aplikacje
Klucz relacji
• Klucz relacji - taki zbiór identyfikujący relacji, którego
żaden podzbiór nie jest zbiorem identyfikującym
relacji .
• Wyróżnia się klucze proste i złożone.
• Klucz jest kluczem prostym, jeśli zbiór identyfikujący
relacji jest zbiorem jednoelementowym,
w przeciwnym razie klucz jest złożony.
• W ogólności, w relacji można wyróżnić wiele kluczy,
które nazywamy kluczami potencjalnymi.
• Wybrany klucz spośród kluczy potencjalnych
nazywamy kluczem głównym.
Klucz podstawowy – primary key
• Aby w bazie możliwe było szybkie wyszukiwanie
i łączenie danych z tabel,
każdy rekord tabeli powinien zawierać pole
za pomocą którego byłby jednoznacznie
identyfikowany w bazie.
Pole tego typu nazywamy kluczem podstawowym.
• Rekord może być też identyfikowany na podstawie
kombinacji kilku pól
- klucz podstawowy wielopolowy
Klucz podstawowy - główny, klucz obcy
• Klucz podstawowy (ang. primary key) zwany też
kluczem głównym to jedno lub więcej pól,
których wartość jednoznacznie identyfikuje każdy
rekord w tabeli.
Taka cecha klucza nazywana jest unikatowością.
• Klucz podstawowy służy do powiązania rekordów w
jednej tabeli z rekordami z innej tabeli.
• Klucz podstawowy jest nazywany kluczem obcym,
jeśli odwołuje się do innej tabeli.
Na przykład, w bazie pracowników kluczem
podstawowym może być numer ewidencyjny
pracownika.
Klucz podstawowy jednopolowy, klucz obcy, klucz złożony
• Jeśli istnieje pole zawierające dane unikatowe, jak na przykład numer
katalogowy czy numer identyfikacyjny, można je zadeklarować jako klucz
podstawowy - single primary key
Jeśli jednak w polu tym powtarzają się wartości, klucz podstawowy nie
zostanie ustawiony. Aby znaleźć rekordy zawierające te same dane, należy
usunąć rekordy o powtarzających się wartościach bądź zdefiniować
wielopolowy klucz. podstawowy.
• Klucz podstawowy wielopolowy zwany też kluczem złożonym
(ang.composed key)
W sytuacji, gdy żadne z pól nie gwarantuje unikatowości wartości w nim
zawartych, należy rozważyć możliwość utworzenia klucza podstawowego
złożonego z kilku pól.
• Klucz obcy to nazwa pola, które w jednej tabeli jest kluczem
podstawowym a w drugiej jest polem łączącym te tabele.
Np. NRUcznia jest kluczem podstawowym w tabeli Uczniowie a w tabeli
Oceny jest kluczem obcym
Relacja - relation, typy relacji
• Po podzieleniu danych na tabele i zdefiniowaniu pól kluczy
podstawowych trzeba wprowadzić do systemu bazy danych
informacje na temat sposobu poprawnego łączenia
powiązanych danych w logiczną całość.
W tym celu definiuje się relacje między tabelami.
• Relacja - powiązanie miedzy parą tabel za pomocą klucza
podstawowego jednej tabeli i odpowiadającego mu klucza
obcego drugiej tabeli.
• Typy relacji:
– Relacja jeden – do - jednego
– Relacja jeden –do - wielu
– Relacja wiele – do - wielu
Relacja jeden – do - jednego
• W relacji jeden – do - jednego każdy rekord w tabeli A może
mieć tylko jeden dopasowany rekord z tabeli B,
i tak samo każdy rekord w tabeli B może mieć tylko jeden
dopasowany rekord z tabeli A.
• Ten typ relacji spotyka się rzadko, ponieważ większość
informacji powiązanych w ten sposób byłoby zawartych
w jednej tabeli.
• Relacji jeden – do - jednego można używać do podziału tabeli
z wieloma polami, do odizolowania części tabeli ze względów
bezpieczeństwa,
albo do przechowania informacji odnoszącej się tylko do
podzbioru tabeli głównej.
Relacja jeden – do - wielu
• Relacja jeden – do - wielu jest najbardziej
powszechnym typem relacji.
W relacji jeden – do - wielu
rekord w tabeli A może mieć wiele
dopasowanych do niego rekordów z tabeli B,
ale rekord w tabeli B ma tylko jeden
dopasowany rekord w tabeli A.
Relacja wiele – do - wielu
• W relacji wiele – do - wielu, rekord w tabeli A może mieć
wiele dopasowanych do niego rekordów z tabeli B
i tak samo rekord w tabeli B może mieć wiele dopasowanych
do niego rekordów z tabeli A.
• Jest to możliwe tylko przez zdefiniowanie trzeciej tabeli
(nazywanej tabelą łącza), której klucz podstawowy składa się
z dwóch pól z kluczy obcych z tabel A i B.
• Relacja wiele – do - wielu jest w istocie dwiema relacjami
jeden – do - wielu z trzecią tabelą.
Na przykład, tabele "Zamówienia" i "Produkty" są powiązane
relacją wiele – do - wielu zdefiniowaną przez utworzenie
dwóch relacji jeden – do - wielu z tabelą "Opisy zamówień".
Algebra relacji
• Relacyjny model BD został opracowany w oparciu o dziedzinę
matematyki zwanej algebrą relacyjną.
Twórcą modelu był amerykański matematyk E. F. Codd.
Dane są przechowywane w strukturach zwanych tabelami.
Tabele są podstawowymi obiektami BD.
Przechowują one dane wykorzystywane przez inne obiekty jak
np. zapytania, formularze czy raporty.
Tabela (table) - zbiór powiązanych ze sobą danych w BD,
przedstawiony w postaci poziomych wierszy zwanych
rekordami (krotki) i pionowych kolumn zwanych polami
rekordu.
Każde pole posiada unikatową nazwę w obrębie tabeli oraz
określony typ danych, np.
Nr, Imie, Nazwisko, Data_urodz, NrTelefon
Model baz danych relacyjnych charakteryzuje się
3 podstawowymi składowymi:
– relacyjnymi strukturami danych
– dostępnością operatorów algebry relacyjnej (do tworzenia,
poszukiwania i modyfikowania danych)
– ograniczeniami integralnościowymi
• Podstawową strukturą danych modelu relacyjnego jest
relacja - podzbiór iloczynu kartezjańskiego wybranych dziedzin
(tj. zbiorów dopuszczalnych danych),
przedstawiona w postaci 2-wymiarowej tablicy.
• Relacja - skończony zbiór krotek - typles,
posiadających taką samą strukturę danych i różne wartości,
przedstawionych w postaci wierszy tablicy.
• Każda krotka zawiera wartość co najmniej jednego atrybutu
o określonej dziedzinie,
przedstawionego w postaci kolumny tablicy.
Własności relacji:
•
•
•
•
•
wszystkie krotki są różne
atrybuty różne
kolejność krotek nie ma znaczenia
kolejność atrybutów nie ma znaczenia
wartości atrybutów są atomowe.
Język deklaratywny: DDL, DML
• Do operowania na danych relacyjnej bazy używa się
zwykle języka deklaratywnego (nieproceduralnego),
który składa się z 2 komponentów:
• języka definicji danych (DDL) - tworzenie,
modyfikacja i usuwanie relacji, struktur na bazie
relacji
• języka manipulowania danymi (DML) wyszukiwanie informacji, na podstawie warunków
selekcji, wstawianie nowych krotek do relacji,
modyfikowanie i usuwanie
Perspektywa view
• Strukturą pochodną do relacji jest
perspektywa - view - okno przez które
odczytujemy lub modyfikujemy dane w relacji
lub zbiorze relacji.
• Perspektywy stosujemy w celu:
– ograniczenia dostępu do relacji bazy danych
– uproszczenia zapytania
– zapewnienia niezależności danych w stosunku do
aplikacji i zapytań ad hoc.
Operacje na relacjach
• Operatory relacyjne:
– selekcji - wybór krotek spełniających
określone warunki - podzbiór poziomy
– projekcji - określenie relacji do wybranych
atrybutów - podzbiór pionowy
– połączenia - łączenie krotek wielu relacji
– klasyczne operatory teorii mnogości:
suma mnogościowa,
iloczyn kartezjański itp.
Operacja projekcji - podzbiór pionowy
• Operacją projekcji relacji r(A1,...,An)
na zbiorze atrybutów X=(Ai,..,Aj),
co zapisujemy Px r(A1,...,An),
nazywamy przekształcenie relacji r(A1,...,An)
w relację wynikową postaci:
Px r(A1,...,An) = {t[X] : t(- r(A1,...,An)}
• Operacja projekcji umożliwia utworzenie
"pionowego” podzbioru relacji
przez wybór określonych atrybutów (pól).
Przykład projekcji
Operacja selekcji
• Operacja selekcji - wybór krotek spełniających
określone warunki - podzbiór poziomy
• Operacją selekcji relacji r(A1,...,An)
względem kryterium selekcji E,
co zapisujemy sEr(A1,...,An),
nazywamy przekształcenie relacji r(A1,...,An)
w relację wynikową postaci
sEr(A1,...,An) = {t : t(- r(A1,...,An) i E(t) = prawda}
• Operacja selekcji umożliwia utworzenie "poziomego"
podzbioru relacji przez wybór krotek (rekordów)
spełniających określony warunek.
Przykład selekcji
"Z
relacji KIEROWNICY_DZIALOW
wybierz informacje o kierownikach tych działów,
których identyfikatory Id_Dzialu są mniejsze lub równe 3
i zarobki są większe lub równe 2000".
Operacja połączenia, iloczyn kartezjański
• Operacja połączenia polega na scaleniu odpowiednich
krotek (rekordów) 2 różnych relacji,
pod warunkiem spełnienia warunku logicznego q
nałożonego na atrybuty połączeniowe.
• Warunkiem połączenia - równość atrybutów w obu relacjach
Np. może być operacja połączenia PRACOWNICY - WYDZIALY,
gdzie : Id_Wydzialu = Id_Wydzialu
• Iloczyn kartezjański
Umożliwia konkatenację krotek 2 relacji lub więcej,
w taki sposób, że każda krotka pierwszej relacji jest łączona
z każdą krotka drugiej relacji
Projektowanie bazy danych - etapy
Dobry projekt jest podstawą utworzenia bazy danych.
Etapy projektowania bazy danych:
1. Określenie celu, któremu ma służyć BD - na tej podstawie jakie
zagadnienia będą w bazie - tabele i jakie informacje - pola
2. Określenie tabel - najtrudniejsze w procesie projektowania BD
Podstawowe zasady projektowania:
– ta sama informacja nie może być wprowadzana wielokrotnie do
jednej lub kilku tabel
– każda tabela powinna mieć informacje tylko na jeden temat
3. Określenie pól w tabelach
4. Przypisanie polom jednoznacznych wartości
5. Określenie relacji między tabelami
6. Wprowadzenie danych i utworzenie i innych obiektów bazy danych
Projektowanie bazy danych
• Punktem wyjścia projektowania są relacje wymagane przez
użytkowników a właściwie informacje zebrane przez projektanta
o wymaganych atrybutach bazy danych,
celem jest natomiast zdefiniowanie schematów relacji, które mają
być przechowywane w bazie danych.
• Trzeba tak zaprojektować rozdział zbioru atrybutów na schematy
relacji, aby uzyskać pewne pożądane właściwości bazy danych.
Niewłaściwe zaprojektowanie schematów relacji może być
przyczyną dublowania się danych, ich niespójności i anomalii
podczas ich aktualizowania.
• W ramach projektowania schematów baz danych,
najistotniejszą czynnością jest normalizacja relacji,
czyli doprowadzenie relacji do odpowiedniej postaci normalnej.
Normalizacja. Pierwsza postać normalna
• Pierwsza postać normalna jest immanentną cechą relacji,
gdyż wymagania tej postaci są zawarte w definicji relacji.
Postać normalizacji polega w tym przypadku na
doprowadzeniu określonego zbioru danych do postaci relacji.
• Mając bazę danych złożoną z relacji w pierwszej postaci
normalnej, jest się narażonym na wszystkie niekorzystne
zjawiska wymienione wyżej,
dlatego należy doprowadzić relacje do kolejnych postaci
normalnych.
• Proces normalizacji polega na odpowiednim podziale relacji
na mniejsze, w wyższej postaci normalnej.
Pierwsza postać normalna relacji
• Relacja jest w pierwszej postaci normalnej, jeżeli każda wartość atrybutu w
każdej krotce tej relacji jest wartością elementarną, czyli nierozkładalną.
Z definicji pierwszej postaci normalnej relacji wynika,
że każdemu elementowi relacji znajdującemu się na przecięciu dowolnej krotki i
dowolnego atrybutu odpowiada pojedyncza wartość, a nie zbiór wartości.
Druga i trzecia postać normalna
• Druga postać normalna:
Dana relacja jest w drugiej postaci normalnej, jeśli każdy
atrybut tej relacji nie wchodzący w skład żadnego klucza
potencjalnego jest w pełni funkcjonalnie zależny od wszystkich
kluczy potencjalnych.
W celu uzyskania drugiej postaci normalnej należy podzielić relację na
zbiór takich relacji, których wszystkie atrybuty będą w pełni funkcjonalnie
zależne od kluczy.
• Trzecia postać normalna relacji
Dana relacja jest w trzeciej postaci normalnej,
jeśli jest ona w drugiej postaci normalnej i każdy jej atrybut
nie wchodzący w skład żadnego klucza potencjalnego nie jest
przechodnio funkcjonalnie zależny od żadnego klucza
potencjalnego tej relacji.
Aby uzyskać trzecią postać normalną relacji, której atrybuty pozostają w
przechodniej zależności funkcjonalnej, należy podzielić ją na 2 relacje.
Podział danych na tabele i klucze w relacyjnych
bazach danych – normalizacja baz danych
• W modelu relacyjnym dane wewnątrz bazy są
dzielone między tabele.
Podział nazywamy normalizacją baz danych.
W najprostszym przypadku baza danych może
sie składać tylko z jednej tabeli.
Przy złożonych danych mogą wystąpić
niepożądane zjawiska utrudniające lub
uniemożliwiające poprawne funkcjonowanie
bazy.
Przykład normalizacji
• Baza danych z jedną tabelą:
Uczen_Wypozyczenia (Imie_Ucznia, Nazwisko_Ucznia, Klasa
ImieAutora, NazwAutora, Tytuł, Wydawnictwo DataWypozycz,
DataOddania)
• W takiej prostej bazie danych z jedną tabelą można zauważyć
zjawisko redundendancji, czyli wielokrotnego powtarzania sie
pewnych danych w bazie.
• Np. jeśli ten sam uczeń wypożyczy kilka książek, to w każdym
rekordzie pojawią się te same dane ucznia.
Gdy np. popełnimy błąd w nazwisku to musimy poprawić
osobno w każdym rekordzie dot. tego ucznia.
Gdy uczeń odda wszystkie książki to usuwając rekordy tracimy
dane o uczniu. Później trzeba od nowa wprowadzić.
Baza danych po normalizacji
• Baza danych z wieloma tabelami.
Model tej samej Bazy Danych, ale dane zostały
podzielone na 3 tabele:
– Uczniowie (IDUcznia, IMUcznia, NazwUcznia,
Klasa)
– Ksiazki (IDKsiazki, ImAutor, NazwAutor, Tytiul,
Wydawn)
– Wypozyczenia (IDwypoz, IDUcznia, IDKsiazki,
DataWypoz, DataZwrotu)
Systemy relacyjnych baz danych
• Do najczęściej spotykanych profesjonalnych
systemów relacyjnych baz danych należą:
– ORACLE Universal Server
– DB2 Universal Database firmy IBM
– Informix Dynamic Server IBM
– PostgreSQL
– SQL Anywhere Studio (Sybase)
– Microsoft SQL Server
W komputerach osobistych popularne systemy to:
Access (Microsoft), FoxPro, Paradox i dBase (dBase Inc.)
oraz MySQL (firmy MySQL AB)