Python w skrócie
Wstęp
Podczas nauki programowania w języku Python zrobiłem notatki w zeszycie. Notatki te jednak były
bardzo lakoniczne i napisane mało wyraźnie. Dzisiaj, po dłuższej przerwie, próbuję sobie
przypomnieć podstawowe zasady programowania w tym języku. Tym razem, opierając się głównie
na zapisach w moim zeszycie, spróbuję sobie zrobić notatki na komputerze. Chciałbym też dodać
komentarze lub nawet przykłady do bardziej użytecznych poleceń.
Czy wystarczy mi zapału? Czy znajdę na to czas? To się zobaczy...
(Sosnowiec, 7.02.2010r.)
I. Podstawowe wiadomości
Interpreter można uruchomić poleceniem „python”. Ewentualnie „python -c <komenda>” aby
uruchomić od razu jakąś komendę, lub „python -m <moduł> <komenda>” jeżeli komenda znajduje
się w jakimś module języka. Przerwać działanie interpretetera można stosując „Ctrl-z” pod
Windows lub „Ctrl-d” pod Unix (w tym ostatnim zadziała też „Ctrl-z” wypisując komunikat
„Stopped”). Kombinacja „Ctrl-c” nie zatrzymuje interpretera, podaje tylko nazwę wyjątku
„KeyboardInterrupt”. Jeżeli uruchomiono interpreter z komendą (opcja „-c” lub „-m”) wyłączy się
on samoczynnie po zakończeniu działania tej komendy. Eleganckim sposobem wyjścia z
interpretera jest użycie polecenia „exit”, które niestety jest dostępne dopiero po załadowaniu
modułu „sys” - można więc użyć: „import sys” a następnie „sys.exit()”.
Skrypty napisane w Pythonie można uruchamiać bezpośrednio z powłoki systemu, wpisując
„python <skrypt>”. W powłokach Unix'owych można podać tylko „./<skrypt>” o ile na początku
skryptu zamieścimy informację o interpreterze: „#! /usr/bin/env python”. W powłokach graficznych
można uruchamiać skrypty klikając je dwukrotnie (w Windows powinny mieć one rozszerzenie
„.py”, w innych systemach też nie zaszkodzi; ewentualnie w Windows można utworzyć skrypty
powłoki „.bat” uruchamiające skrypty pythona).
Skrypty Pythona (tak jak skrypty powłoki oraz inne programy) można uruchamiać z argumentami
podanymi w wierszu poleceń. Dostęp do tych argumentów skrypt uzyskuje przy pomocy tablicy
(listy) „argv” modułu „sys”. I tak zerowy element (sys.argv[0]) to nazwa skryptu, element z
numerem jeden (sys.argv[1]) to pierwszy argument, itd...
Przed omówieniem podstawowych struktur danych jeszcze jedna sprawa (niestety mało przyjemna i
potrafiąca nieźle namieszać) – standardy kodowania znaków narodowych (np. polskich). Ciągi
znaków ujęte w apostrofy traktowane są domyślnie jako należące do standardowego zestawu
znaków, więc wpisanie 'gęś' spowoduje błąd, chyba, że poinformujemy interpreter, jakiego zestawu
znaków używamy (zazwyczaj zależy od systemu operacyjnego i stosowanego edytora tekstu). W
tym celu na początku skryptu (poniżej linijki wskazującej na interpreter) dodajemy kolejną linijkę
„# coding:iso8859-2” jeżeli nasz system i edytor tekstu posługuję się zestawem polskich znaków
zgodnych ze standardem ISO (np. starsze dystrybucje Linux'a). Dla skryptów pisanych w
„Notatniku” pod Windows można użyć „# coding:cp1250”, a w nowoczesnych Linux'ach „#
coding:utf8”. Wybranie standardu „UTF-8” (Unicode) jest zdecydowanie najwygodniejsze (o ile
nasz system operacyjny, lub przynajmniej edytor tekstu, taki system kodowania obsługuje – pod
Windows można pisać skrypty w Word'zie lub OpenOffice i zapisywać jako tekst ASCII z
kodowaniem Unicode UTF-8), gdyż obsługuje on wszystkie znaki narodowe i jest domyślnie
wymagany przez biblioteki pozwalające tworzyć programy „okienkowe” (zarówno pod Linux'a jak
1-1
i pod Windows), np. bibliotekę „Tkinter”.
Jeżeli jednak musimy używać różnych zestawów znaków, Python oferuje nam odpowiednie
konstrukcje. I tak u'gęś' oznacza napis w Unicode. Aby go przekonwertować np. na ISO, użyjemy
„u'gęś'.encode('iso8859-2')”, konwersję odwrotną zapewni „unicode('tekst w ISO','iso8859-2')”.
Dla porządku należy wspomnieć o konstrukcji r'jakiś tekst', która oznacza tekst „surowy”, mogący
zwierać znaki specjalne.
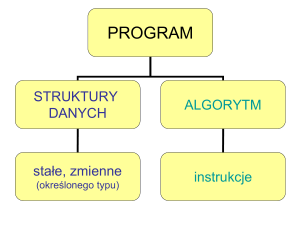
Skoro jesteśmy już przy napisach, to od tego można zacząć omówienie podstawowych struktur
danych. Łańcuch tekstowy może być traktowany jako lista znaków i podstawowe operacje na
listach (podstawowe struktury w Pythonie) odnoszą się również do napisów:
napis[2:5] – daje wycinek napisu od pozycji „2” do „4” (pozycje numerujemy od zera, czyli w tym
przypadku dostaniemy trzecią, czwartą i piątą literę, np. 'Witajcie'[2:5] daje 'taj')
napis[5] - daje jeden znak, z pozycji „5” (czyli szósty) – ten sam efekt da napis[5:6]
napis[2:] - daje tekst od pozycji „2” do końca ('Witajcie'[2:] daje 'tajcie')
napis[:5] – daje tekst obcięty od „5” pozycji, czyli pozycje „0” do „4” ('Witajcie'[:5] daje 'Witaj')
napis[-1] – daje ostatni znak, [-2] – drugi od końca, itd...
napis[-5:-2] – daje piąty, czwarty i trzeci znak od końca ('Witajcie'[-5:-2] daje 'ajc')
Dodanie trzeciej liczby w kwadratowym nawiasie (po drugim dwukropku) pozwala ustawić krok
(dodatni lub ujemny), co który znak ma być wzięty pod uwagę, np.:
napis[::-1] – odwraca ciąg znaków
napis[::2] – daje pierwszy, trzeci, itd... znak ('Witajcie'[::2] daje 'Wtji')
Uwaga: Nie można nadać wartości pojedynczemu znakowi lub części ciągu znaków. Wpisanie
„napis[3]='x'” nie spowoduje podmiany znaku w tekście (spowoduje za to wystąpienie błędu), ale
stosując odpowiednie cięcia można sobie z tym poradzić:
napis=napis[:3]+'x'+napis[4:] zamieni odpowiedni element ciągu (np. 'Witajcie' na 'Witxjcie')
len(napis) – podaje ilość znaków w napisie
Jak już wspomniano, podstawowym typem danych w Pythonie jest lista. Listę tworzymy ujmując
jej elementy oddzielone przecinkami w nawiasy kwadratowe. Lista może się składać z elementów
różnego typu (liczb, liter, ciągów znaków, innych list) dowolnie ze sobą wymieszanych i dzięki
temu listy zastępują większość struktur danych występujących w innych językach programowania
(np. rekordy w Pascal'u). Prawidłowa jest np. taka lista:
[12,'jajka',3.14,[7,'noga']]
W przeciwieństwie do opisanych powyżej ciągów tekstowych, możliwe jest nadawanie nowych
wartości poszczególnym elementom lub fragmentom listy, np. lista[3:5]=[u'coś','tam']
len(lista) – podaje ilość elementów listy
lista.append(element) – dodaje element na koniec listy
Przy okazji powyższych rozważań wyniknęły jeszcze zastosowania dwóch operatorów „+” i „=”.
Operator „+” posłużył nam do łączenia ciągów znaków (może też łączyć listy, np. „['karo','kier']+
['pik','trefl']” utworzy pełną listę nazw kolorów w brydżu) ale ma też swoje klasyczne zastosowanie
w operacjach arytmetycznych. Natomiast znak „=” służy do nadawania wartości (ale nie do
porównywania) zmiennym, listom, itp. Interesującą cechą Pythona jest możliwość jednoczesnego
nadawania wartości kilku zmiennym (w jednym zapisie), np.:
a,b=7,5 oznacza „a=7; b=5”
1-2
a,b=b,a+b nie oznacza „a=b; b=a+b”, a raczej „c=a; a=b; b=c+b” bez potrzeby użycia dodatkowej
tymczasowej zmiennej „c”, co znakomicie uprościło sprawę
a=b=7 oznacza „a=7; b=7”
II. Warunki, pętle, iteracje
Czas przejść do sterowania wykonaniem skryptu. Instrukcje sterujące zazwyczaj kończą się
dwukropkiem, po którym następuje instrukcja do wykonania (w tej samej linijce) lub cały blok
instrukcji (kilka linijek programu). Blok instrukcji wyróżniamy poprzez odsunięcie go o jedną lub
kilka spacji od lewej krawędzi ekranu. W Pythonie nie ma instrukcji kończącej blok (jak „end;” w
Pascalu lub „End If”, „Wend” czy „Next I” w Basicu, znaki „}” w PHP lub C), kolejna linijka
instrukcji, jeżeli nie należy już do bloku, powinna mieć odpowiednio zmniejszony odstęp od lewej
krawędzi. Dlatego lepiej jest korzystać z edytora tekstu, który sam dba o te odstępy, a do tego
jeszcze zwiększa czytelność programu kolorując odpowiednio składnię - świetnie nadaje się do tego
instalowany wraz z Pythonem „Idle”, Linux'owy „kwrite” koloruje składnię i numeruje linie ale
sam nie wstawia wcięć (podobnie „vim”); najgorszym możliwym edytorem dla programisty
(jakiegokolwiek języka) jest „Notatnik” z Windows.
if x<0: <instrukcje> - wykonuje instrukcje, jeżeli x<0
elif x==0: <instrukcje> - wykonuje instrukcje, jeżeli warunek wcześniej podany (przy „if”) nie był
spełniony a x=0 (do porównań w Pythonie używa się podwójnego znaku równości)
else: <instrukcje> - wykonuje instrukcje, jeżeli żaden wcześniejszy warunek (przy „if” lub „elif”)
nie został spełniony
while x<0: <instrukcje> - powtarza instrukcje tak długo, jak długo warunek x<0 jest spełniony
for x in lista: <instrukcje> - powtarza instrukcje dla każdego elementu listy. Jeżeli nie chcemy aby
instrukcje przypadkowo modyfikowały zawartość listy, możemy użyć kopii podając po naziw listy
zakres w nawiasach kwadratowych - „lista[:]” oznacza kopię całej listy
for x in range(od, do, co_ile) – pozwala na rozpowszechniony w innych językach programowania
sposób iteracji po kolejnych liczbach całkowitych. Podanie tylko jednego argumentu dla „range”
spowoduje iteracje dla „n” kolejnych liczb naturalnych począwszy od zera. Np.:
„for x in range(7)” jest tożsame z „for x in [0,1,2,3,4,5,6]”
„for x in range(3,10,2)” odpowiada natomiast „for x in [3,5,7,9]”
W pętlach utworzonych przy pomocy instrukcji „for” lub „while” można (choć to mało eleganckie)
stosować instrukcje modyfikujące ich działanie:
break – przerywa działanie pętli
continue – przechodzi do następnego przebiegu pętli
else – wykonuje po zakończeniu pętli, o ile nie została przerwana przez „break” (uwaga: jest to
„else” po „for” lub „while” a nie po „if”)
pass – to pusta instrukcja, która „nie robi nic”, może być użyta jako jedyna w pętli „while”
czekającej bezczynnie, aż jej warunek przestanie być spełniony (w tym miejscu należy
przypomnieć, że nieprzemyślane pętle „while” powodują zawieszenie programu)
Jeżeli w instrukcjach z „if” (lub innych konstrukcjach z warunkiem) wstawimy skomplikowane
wyrażenie określające warunek, np.: „a<=b==c>d”, to poszczególne warunki rozpatrywane są „po
kolei”.
1-3
III. Definiowanie funkcji
def nazwa(argumenty): <instrukcje> - rozpoczyna definicję nowej funkcji. Poszczególne instrukcje
wpisuje się w bloku (podobnie jak w przypadku instrukcji warunkowych i iteracyjnych).
Nazwa funkcji może być wykorzystywana w skryptach jak każda zmienna, np. można utworzyć
funkcje tworzącą inną funkcję lub listę zawierającą funkcje.
Na początku funkcji można podać ujęty w potrójne apostrofy komentarz, który będzie dostępny
później poprzez metodę __doc__ funkcji (nazwa.__doc__).
Zmienne podane jako argumenty nie są przez funkcję modyfikowane (przekazanie następuje przez
wartość), chyba, że chcemy wymusić przekazanie przez zmienną, wtedy używamy dyrektywy
„global zmienna” (dyrektywy używamy we wnętrzu funkcji, podając istniejącą poza funkcją nazwę
zmiennej – nie wpisujemy tej nazwy w nawiasie w definicji funkcji!).
Argumenty przekazane do funkcji (w nawiasach) mogą mieć wartości domyślne – podaje się je w
nagłówku funkcji po znaku równości, np. „def funkcja(x=7):”. Wtedy pominięcie argumentu
spowoduje, że przyjmie on wartość domyślną. Argumenty bez wartości domyślnej muszą być przed
tymi z wartością domyślną. Wywołując funkcję można pominąć argumenty z wartością domyślną,
ale te znajdujące się na końcu – nie można np. w normalny sposób pominąć pierwszego a podać
drugi (np. „funkcja(,3)”). Ale jest na to sposób – jeżeli znamy nazwę argumentu, który chcemy
podać, możemy to zrobić tak: „funkcja(x=3)” - jeżeli w wywołaniu funkcji podajemy argumenty z
użyciem ich nazw, kolejność jest obojętna.
Wywołując funkcję możemy przekazać jej argumenty w postaci listy, ale wywołanie
„funkcja(lista)” spowoduje, że lista zostanie potraktowana jako pierwszy argument (pozostałe
dostaną wartości domyślne o ile były zdefiniowane). Aby „rozpakować” listę argumentów funkcji,
należy jej nazwę poprzedzić gwiazdką „funkcja(*lista)” - wtedy do pierwszego argumentu zostanie
przypisany pierwszy element z listy, do drugiego drugi, itd. Można też przekazać listę argumentów
nazwanych w postaci słownika (patrz następny rozdział), poprzedzając go dwiema gwiazdkami
„funkcja(**slownik)”.
Instrukcja return z podaną zmienną lub wartością powoduje zwrócenie przez funkcję tej zmiennej
lub wartości. Instrukcję tą można pominąć – wtedy funkcja zwraca „None” (funkcja taka
odpowiada procedurom z innych języków - „procedure” z Pascal'a i „Sub” z Basic'a). Ale każdą
funkcję (nawet jeżeli zwraca wartość) można wywołać jak procedurę (wtedy wartość jest
ignorowana). Wartość przekazywana przez funkcję może być dowolnego typu zmienną, listą, lub
nawet inną funkcją.
Ciekawą instrukcją w Pythonie jest lambda, tworząca funkcje pomocnicze. Jej konstrukcja
wygląda tak:
nazwa = lambda x : <wyrażenie lub funkcja>
Zmienna (lub zmienne) przed dwukropkiem to argumenty funkcji, wyrażenie za dwukropkiem
powinno dawać wartość zwracaną przez funkcję. Konstrukcji tej nie należy używać, gdy można
zdefiniować funkcję w normalny sposób. Ale czasami jest potrzeba np. automatycznego
generowania funkcji dla tworzonych nowych obiektów (gdy działanie funkcji zależeć ma od
kontekstu obiektu, dla którego została utworzona). Stosuje się je w funkcjach tworzących inne
funkcje, np. w konstruktorach obiektów.
IV. Struktury danych
Podstawowe informacje na temat ciągów znakowych i list zostały podane w rozdziale I. W
szczególności omówiono tworzenie kopii lub wycinków list. Aby zakończyć ten temat, podam
1-4
jeszcze kilka metod ciągów, które mogą być stosowane bezpośrednio (bez potrzeby importowania
modułu „string” - patrz rozdział V i X):
.capitalize() - zamienia pierwszą literę ciągu na dużą a pozostałe na małe
.lower() - zamienia wszystkie litery na małe; .upper() - na duże
.find(co) – szuka podciągu znaków i podaje jego pozycję (można podać dodatkowe parametry –
skąd i dokąd ma szukać), jeżeli nic nie znalazł – zwraca -1; występuje też w wersji .rfind
szukającej od prawej strony (co ma znaczenie tylko przy większej ilości wystąpień danego
podciągu, bo pozycję i tak podaje od lewej); są też odpowiedniki .index i .rindex, które działają
podobnie, ale zwracają „ValueError” (a nie -1) w przypadku nie znalezienia podciągu.
.count(co) – z podobnymi parametrami jak „find” lub „index” podaje liczbę wszystkich
znalezionych podciągów
.split(separator,ile_razy) – tnie ciąg w miejscach wystąpienia podciągu (separatora) wskazaną
liczbę razy, a w wyniku zwraca listę „kawałków” (bez separatora); można pominąć liczbę razy –
potnie wszędzie, gdzie znajdzie separator; można pominąć nawet separator – wytnie spacje; .rsplit
działa podobnie, ale liczy od prawej (bo kolejność na liście wyników i tak jest „od lewej”)
.strip(znaki) – odcina początkowe i końcowe literki (nawet więcej niż „po jednej”), o ile znajdą się
w ciągu „znaki”; jeżeli nie podamy jakie znaki ma odciąć – odetnie spacje; .rstrip i .lstrip odcinają
tylko z jednej strony
.center(szerokosc) uzupełnia ciąg znakami tak, aby zajął odpowiedni szerokość – dodaje mniej
więcej równo spacji z obu stron („centruje”), w przeciwieństwie do .ljust i .rjust, które dodatją
tylko po jednej (tak aby tekst znalazł się po stronie zgodnej z nazwą funkcji); jak podamy za małą
szerokość, to po prostu nie doda spacji
.zfill(szerokosc) – działa jak „rjust” uzupełniając początek zerami (ma to sens dla liczb)
.replace(co, na_co,ile_razy) – podmienia określony podciąg innym wskazaną liczbę razy (jeśli
liczby nie podamy – podmieni wszystkie wystąpienia podciągu)
To tyle na temat ciągów (np., może prawie – polecam jeszcze zajrzeć do modułu „string”). Teraz
przejdę do metod, które posiadają listy.
append(x) – dodaje element x na końcu listy
extend(lista2) – dodaje elementy listy „lista2” na końcu aktualnej listy
remove(x) – usuwa pierwszy znaleziony x z listy
index(x) – podaje pozycję pierwszego x na liście
count(x) – zlicza wszystkie wystąpienia x na liście
insert(i,x) – dodaje element x przed i-tym elementem listy (licząc od zera!)
pop(i) – usuwa i-ty element listy, podając przy okazji jego wartość; bez argumentu „pop()” usuwa
ostatni element listy
Metody „append” i „pop” pozwalają tworzyć kolejki („FIFO” i „LIFO”): w obu dodajemy nowe
elementy przy pomocy „append” a zdejmujemy je w FIFO przy pomocy „pop(0)” a w LIFO przy
pomocy „pop()”.
sort() - porządkuje zawartość listy
W posortowanej liście są najpierw liczby (po kolei), następnie listy, a na końcu ciągi znaków
(alfabetycznie). Kolejność list jest ustalana poprzez porównywanie ich pierwszych elementów
1-5
(następnie, jeżeli trzeba – drugich, itd... do skutku).
reverse() - odwraca kolejność listy
Istnieją konstrukcje pozwalające na wykonywanie pewnych czynności na wszystkich elementach
listy:
lista2=filter(funkcja,lista) – tworzy listę zawierającą tylko te elementy listy pierwotnej, dla których
funkcja przyjmuje wartość TRUE (funkcja musi pobierać jeden argument i zwracać wartość
logiczną)
lista2=map(funkcja,lista) – tworzy listę wyników wywołań funkcji dla poszczególnych elementów
listy pierwotnej (funkcja musi pobierać jeden argument i zwracać wartość dowolnego typu)
x=reduce(funkcja, lista, start) – bez podanego parametru „start” wywołuje funkcję dla pierwszych 2
elementów listy, następnie uzyskanej wartości i trzeciego elementu, itd... aż zredukuje listę do
jednej wartości. Jeżeli podamy „start”, przyjmie go jako pierwszy argument przy pierwszym
wywołaniu funkcji (drugim argumentem będzie pierwszy element listy). Funkcja użyta musi
pobierać 2 argumenty i zwracać wartość dowolnego typu.
lista2=[funkcja(argument) for element in lista] – generuje listę wykonując funkcję iteracyjnie dla
każdego elementu listy pierwotnej (czyli działa podobnie jak „map” tylko wolniej). Zamiast funkcji
można użyć dowolnych wyrażeń. Można uzupełnić zapis o umieszczaną na końcu klauzulę „if .....”
(aby wykonać działania tylko dla elementów spełniających pewne warunki) lub połączyć więcej
iteracji („[wyrażenie for element1 in lista1 for element2 in lista2 for element 3 in range(a,b) if ...]”).
Aby usunąć część listy wystarczy nadać tej części wartość pustej listy: „lista[2:4]=[]” lub użyć
polecenia „del lista[2:4]” (UWAGA: samo „del lista” usunie całą listę)
To tyle na temat list. Kolejną strukturą, która może się przydać jest zbiór. Zbiór przypomina listę, w
której elementy nie powtarzają się. Kolejność elementów w zbiorze nie ma dla nas znaczenia,
chcemy tylko móc sprawdzać jego zawartość oraz wykonywać podstawowe operacje na zbiorach:
zbior=set(lista) – tworzy zbiór na podstawie listy
element in zbior – ma wartość TRUE gdy element należy do zbioru (w tym miejscu warto
wspomnieć o operatorach logicznych pozwalających konstruować wyrażenia: | - lub, & - i, ^ albo)
+ - - to operatory, które m.in. pozwalają tworzyć sumę i różnicę zbiorów
W przeciwieństwie do zbiorów, których używa się tylko w rzadkich przypadkach, bardzo
pożyteczną strukturą danych są słowniki, które przypominają listy, w których każdy element
(wartość) został przyporządkowany określonemu kluczowi. W słownikach rzadko interesuje nas
kolejność elementów (bywa, że ma ona znaczenie), gdyż dostęp do nich uzyskujemy poprzez klucz.
Podstawowa konstrukcja słonika ma postać:
slownik = { klucz1:wartosc1, klucz2:wartosc2, ...}
Przykładowe metody słowników:
keys() - podaje listę kluczy
values() - podaje listę wartości
items() - podaje listę par: (klucz,wartość)
has_key(klucz) – informuje, czy klucz jest w słowniku (podobnie „klucz in slownik”)
1-6
get(klucz,domyslna) – podaje wartość odpowiadającą podanemu kluczowi (jeżeli klucz nie
występuje, zwraca wartość domyślną, o ile była podana), drugi argument można pominąć (wtedy
dla nie istniejących kluczy przyjmuje wartość None).
setdefault(klucz,domyslna) – działa podobnie jak „get”, ale przy podaniu nie występującego klucza
dodaje go automatycznie do słownika wraz z wartością domyślną
pop(klucz,domyslna) – działa podobnie jak „get”, ale usuwa wykorzystane klucze ze słownika.
Jeżeli klucza nie było – podaje wartość domyślną (jeżeli nie była podana – wywołuje „KeyError”)
W pętlach można stosować specjalne instrukcje (iteratory):
for klucz,wartosc in slownik.iteritems(): - wykonuje instrukcje dla każdej pary „klucz,wartosc”
for indeks,wartosc in enumerate(slownik): - wykonuje instrukcje dla par „indeks,wartosc”, gdzie
„indeks” to kolejny numer elementu w słowniku (a nie klucz)
for wartosc1,wartosc2 in zip(lista1,lista2): - pobiera po 1 wartości z każdej listy lub słownika
for i in sorted(lista): - wykonuje instrukcje dla posortowanych elementów listy
for i in reversed(lista): - wykonuje instrukcje dla elementów listy od końca do początku
V. Moduły
Znaczna część funkcji Pythona znajduje się w tematycznie posegregowanych modułach dostępnych
dopiero po ich załadowaniu. Podobnie pisząc własny program, złożony z wielu rozbudowanych
skryptów, możemy tworzone na jego potrzeby funkcje umieszczać w osobnych modułach, aby
zachować przejrzystość kodu.
Do ładowania modułów służy polecenie import. Można go użyć do załadowania całego modułu
„import modul” lub tylko określonej funkcji „from modul import funkcja”. W tym drugim
przypadku funkcja jest dostępna tak, jakby była zdefiniowana w bieżącym skrypcie – uruchamiamy
ją po prostu przez podanie samej nazwy (można tak zaimportować wszystkie funkcje: „from modul
import *”). Jeżeli natomiast importujemy cały moduł, to wywołujemy jego funkcje jako metody
obiektu modułu, czyli „modul.funkcja()”.
Uwaga: Funkcje, których nazwa zaczyna się od podkreślenia „_” nie są importowane (są
traktowane jako prywatne funkcje modułu).
Już załadowany moduł można załadować ponownie (jeżeli uległ zmianie – podczas testów lub w
programie samomodyfikującym się) stosując „reload(modul)”.
dir(modul) – zwraca listę nazw zdefiniowanych w module (pod warunkiem, że moduł jest
załadowany); argument można pominąć i wtedy dostajemy listę wszystkich nazw aktualnie
zdefiniowanych w skrypcie i załadowanych modułach. Jeżeli chcemy uzyskać opis modułu (o ile
jego autor go napisał w potrójnych apostrofach – patrz rozdział III), możemy odczytać zawartość
„modul.__doc__”.
Moduły można organizować w pakiety. W tym celu należy umieszczać je w podkatalogu o nazwie
pakietu i ładować „import pakiet.modul”. W takim podkatalogu trzeba dodać moduł „__init__.py”,
którymoże zawierać jakiś kod wspólny dla pakietu (np. inicjujący). Instrukcja ładowania całego
pakietu „from pakiet import *” działa poprawnie tylko w Unix'ie (chyba, że w module inicjującym
podano listę modułów o nazwie „__all__” - to ma załatwić sprawę dla Windows i Mac'a)
1-7
VI. Podstawowe operacje I/O
Przed omówieniem operacji wejścia i wyjścia warto omówić konwersję zmiennych na ciągi
znaków, dzięki czemu można przedstawiać wartości zmiennych w formie czytelnej dla ludzi oraz
zapisywać je do plików tekstowych.
str(zmienna) – zamienia zmienną w jej (czytelną dla ludzi) reprezentację tekstową (w odróżnieniu
od repr zamieniającej zmienną w reprezentację tekstową czytelną dla maszyn).
Niektóre instrukcje używają ciągów znaków formatujących zmienne przy zamianie ich na tekst.
Ciągi takie zaczynają się znakiem „%” i tak „%d” oznacza liczbę a „%3d” liczbę wyrównaną do
prawej w kolumnie 3-znakowej, „%5.3f” oznacza liczbę zmiennoprzecinkową z dokładnością do 3
miejsc po przecinku w kolumnie 5-znakowej, „%-10s” oznacza zmienną tekstową wyrównaną od
lewej (znak minus) w kolumnie 10-znakowej (użycie „s” wymusza zmianę nietekstowych
zmiennych funkcją „str()”). Użycie „%(klucz)s” pozwala na podanie słownika zawierającego
nazwane zmienne.
Ciągi formatujące można wykorzystać w instrukcji print, np.:
print „Trzeba kupić %d kilogramów %s w pobliskim sklepie” % ilosc, nazwa
Istnieją również metody ciągów znakowych formatujące zmienne: .rjust(szerokosc),
.ljust(szerokosc), .center(szerokosc), .zfill(szerokosc)
Instrukcja „print” służy do wyprowadzenia danych w formie tekstu (na standardowe wyjście),
natomiast do pobrania danych od użytkownika (ze standardowego wejścia służy instrukcja „input”.
Instrukcji tej można podać argument, będący tekstem zachęty (można też pominąć go). Instrukcja
zwraca wartość zmiennej podanej przez użytkownika. Ale tu jest problem – użytkownik musi
wpisać zmienną tak, jak gdyby wpisywał ją w tekście programu po znaku równości (czyli jeżeli
pisze coś innego niż pojedynczą liczbę, obowiązują go cudzysłowy, nawiasy, itd...). Podobnie
wyglądająca funkcja „raw_input” traktuje dane wprowadzone przez użytkownika jako tekst (do
ewentualnej dalszej analizy). W przypadku najprostszym można używać „input” gdy pytamy o
liczbę a „raw_input” gdy pytamy o ciąg znaków:
wiek=input('Ile masz lat?')
imie=raw_input('Jak masz na imię?')
Tyle na temat zwykłego komunikowania się z użytkownikiem poprzez wiersz poleceń. Teraz czas
zabrać się za odczyt i zapis plików na dysku! Do tego celu używamy zmiennej plikowej zwracanej
przez poniższą instrukcję:
open(nazwa_pliku,tryb) – otwiera plik o podanej nazwie, w podanym trybie (o tym za chwilę) i
zwraca zmienną, którą wykorzystamy do przeprowadzania wszystkich potrzebnych operacji na tym
pliku. Tryb otwarcia zależy od tego, czy plik traktujemy jako tekstowy czy binarny, oraz czy
chcemy w nim coś zapisywać, czy tylko czytać (a może jedno i drugie?). Tryby przedstawia
poniższa tabela:
Plik tekstowy
Tylko do odczytu
(nie modyfikuje pliku)
Tylko do zapisu
(zastępuje plik jeśli
istnieje)
Do odczytu i zapisu
(pozwala na edycję
istniejącego pliku)
r
w
r+
Plik binarny
rb
wb
r+b
Ciekawą opcją jest stosowanie „rU” w plikach tekstowych – pozwala na rozpoznanie sposobu
kończenia linii tekstu (inny dla Windows i Unix).
1-8
Uzyskana przy pomocy tej instrukcji zmienna posiada następujące metody:
.read(ile_bajtow) – odczytuje z pliku wskazaną ilość bajtów (lub znaków). Liczbę można pominąć
– wtedy zwraca całą zawartość pliku!
.readline – odczytuje z pliku linijkę tekstu (aż do znaku „\n”, włącznie z tym znakiem). Warto
zrócić uwagę, że pusta linijka daje „\n” natomiast uzyskanie pustego ciągu „” oznacza, że
osiągnięto koniec pliku!
.readlines – odczytuje cały plik tekstowy zwracając listę linii (zakończonych znakami „\n”).
for linia in plik: - wykonuje określone polecenia na kolejnych linijkach tekstu (bez potrzeby
wczytywania ich naraz do listy)
.write(zmienna) – zapisuje zmienną (lub tekst) do pliku (jeżeli chcemy zakończyć znakiem końca
linii to musimy go tam dodać)
.tell – zwraca aktualną pozycję w pliku (od początku)
.seek(pozycja, tryb) – przestawia aktualną pozycję w pliku (w zależności od trybu: 0 – od początku,
1 – względem aktualnej pozycji, 2 – względem końca pliku)
.truncate – obcina plik na aktualnej pozycji
.close – zamyka plik
.isatty – informuje, czy plik jest konsolą (urządzeniem znakowym systemu Unix)
Duże i skomplikowane zmienne można zapisywać w plikach przy użyciu modułu pickle
(oczywiście po zaimportowaniu go):
pickle.dump(zmienna,plik) – zapisuje zmienną do pliku
pickle.load(plik) – zwraca odczytaną z pliku zmienną
Istnieją też metody do odczytu i zapisu tekstów (ich nazwy kończą się literą „s”). Szybszą wersją
tego modułu jest cPickle napisany w „C”.
VII. Obsługa błędów
Błędy potrafią pojawić się w trakcie działania nawet wielokrotnie sprawdzonego i (jak dotąd)
poprawnie działającego programu. Przyczyną mogą być bezsensowne dane wprowadzone przez
użytkownika, brak dostępu do określonych zasobów lub sytuacja, której nie przewidzieliśmy.
Normalnym działaniem interpretera jest przerwanie wykonywania programu. Ale czasem jesteśmy
w stanie przewidzieć, w którym fragmencie programu wystąpi błąd, i chcemy aby program poradził
sobie z błędem nie przerywając działania. Czasami też chcemy zdefiniować własne typy błędów
aby później w innym miejscu je obsłużyć.
Konstrukcja try...except pozwala na przechwycenie i obsługę błędu. Fragment programu zagrożony
wystąpieniem błędów umieszczamy w bloku po instrukcji „try:” a następnie umieszczamy blok (lub
kilka bloków) „except:” z instrukcjami obsługującymi ten błąd. Po instrukcji „except” można podać
typ błędu (lub listę błędów), który(e) ma obsługiwać blok. Można umieścić kilka bloków „except”
odpowiadających za różne typy błędów. Na końcu możemy umieścić blok „except” bez
wymienionych typów błędów (może być to też jedyny blok), zawierający instrukcje wykonywane w
przypadku wszystkich pozostałych (nie przechwyconych wcześniej) błędów.
Przechwycenie błędu przez blok „except” powoduje automatyczne anulowanie tego błędu. Jeżeli
jednak chcemy w pewnych przypadkach zrezygnować z jego obsługi – wystarczy go ponownie
wywołać używając w obrębie bloku „except” polecenia „raise” bez parametrów.
1-9
Po wszystkich blokach „except:” możemy dodać blok „else:” wykonywany w przypadku
bezbłędnej realizacji poleceń w bloku „try:”. Ostatnim z możliwych do zdefiniowania bloków jest
„finally:”, zawierający instrukcje do wykonania niezależnie od tego czy błąd wystąpił, czy nie. I tu
nasuwa się pytanie „Po co? Przecież można te instrukcje wpisać po wszystkich blokach „except”” otóż nie – instrukcje w bloku „finally:” wykonane zostaną zawsze, nawet w przypadku wystąpienia
błędu, którego nasz program nie umie obsłużyć (instrukcje w tym bloku wykonają się wtedy przed
przerwaniem działania programu). Mogą to więc być instrukcje robiące kopię zapasową
kluczowych danych, itp.
Czasami chcemy w jakimś miejscu wymusić w pewnych okolicznościach wystąpienie błędu aby go
później odpowiednio obsłużyć. W tym celu używamy:
raise Exception(argumenty)
Zamiast „Exception” możemy podać konkretny typ błędu (jeden z dostępnych w języku lub
zdefiniowany własnoręcznie – o czym za chwilę). Obsługując taki błąd możemy zatytułować blok
„except Exception, dane” i wtedy w „dane” dostaniemy argumenty przekazane przy wywołaniu
błędu.
Ostatnim tematem tego rozdziału będzie definiowanie własnych typów błędów. W tym celu
potrzebna będzie umiejętność definiowania klas (opisana w następnym rozdziale). Nie wdając się w
szczegóły definicja błędu może wyglądać mniej więcej tak:
class MojBlad(Exception):
def __init__(self,value):
self.value=value
def __str__(self):
return repr(self.value):
Definicja ta tworzy klasę błędu (potomną klasy „Exception”) z dwiema podstawowymi metodami:
konstruktorem „__init__” zapamiętującym wartość podaną przy wywołaniu błędu oraz metodą
„__str__” pozwalającą na odczytanie tej wartości. Taki błąd wywołujemy np. tak:
raise MojBlad('Coś poszło nie tak!')
i tym sposobem informacja „Coś poszło nie tak!” jest zakodowana w naszym błędzie i dostępna do
odczytania w klauzuli „except”.
VIII. Klasy
Python definiuje podstawowe typy obiektów jak listy, słowniki, błędy, itp. Dodatkowe typy zawarte
są w uzupełniających go modułach i bibliotekach (jak np. biblioteki do obsługi okienek w trybie
graficznym). Ale czasami dla wygody chcemy zdefiniować jakiś własny typ zmiennej albo
zmodyfikować nieco typy już istniejące (w praktyce: utworzyć nowy typ w oparciu o istniejący –
np. nowy typ błędu, jak opisano w poprzednim rozdziale). Do tego przyda nam się instrukcja
„class”, po której podajemy nazwę nowej klasy i w nawiasie nazwę klasy, z której nasza klasa ma
dziedziczyć.
Dobrym zwyczajem jest umieszczenie opisu klasy w pierwszej linijce jej definicji w potrójnym
cudzysłowie, aby można go było później odczytać przy pomocy „__doc__” (patrz początek
rozdziału III o definiowaniu funkcji).
Każda klasa musi posiadać konstruktor, czyli metodę „__init__” z przynajmniej jednym
parametrem „self” - czyli zmienną, poprzez którą metody klasy będą mogły się odwoływać do
siebie. Konstruktor może posiadać więcej argumentów, wtedy ich podanie będzie wymagane (lub
opcjonalne) przy tworzeniu zmiennej danej klasy.
Parametr „self” musi być pierwszym argumentem każdej definiowanej w danej klasie metody.
1-10
Oczywiście wywołując te metody argument ten pomijamy – wynika to ze sposobu wywołania
metod: „zmienna.Metoda(argumenty)” - po prostu zmienna i tak jest przekazywana metodzie jako
pierwszy argument (dzięki czemu metoda „wie” w jakim kontekście działa). Przyjęło się nazywać
metody z dużych liter a nazwy zmiennych pomocniczych zaczynać od podkreśleń. Wewnątrz klasy
metody wywołuje się przez zmienną „self”.
Wszystkie odziedziczone metody można nadpisywać. Jeżeli nie nadpiszemy jakiejś metody, to jej
wywołanie automatycznie odnosi się do metody klasy nadrzędnej. Jeżeli natomiast pomimo
nadpisania zechcemy wywołać metodę klasy nadrzędnej – wystarczy zamiast zmiennej „self” podać
nazwę klasy (jak w nagłówku). W Pythonie każda klasa może dziedziczyć z kilku klas nadrzędnych
– w przypadku pokrywania się metod decyduje kolejność klas podanych w nawiasie, w nagłówku
definicji.
Zmienne w obrębie klasy nie muszą być definiowane, chyba że chcemy się do nich odwoływać w
metodach (wtedy ich początkową wartość dobrze jest ustawić w metodzie „__init__”). W
przeciwnym wypadku możemy dowolnie powoływać do istnienia zmienne. Jeżeli wygodnie jest
nam używać obiektu bez metod (zawierającego tylko zmienne), to można go utworzyć jako klasę
bez dziedziczenia i bez konstruktora („class MojaKlasa: pass”) i używać go jak „record” w Pascal'u
(można się ewentualnie zastanowić, czy w pewnych sytuacjach roli rekordu nie spełni lepiej
słownik).
Aby sprawdzić przynależność obiektu lub klasy można posłużyć się następującymi funkcjami:
isinstance(zmienna,klasa) – sprawdza, czy zmienna jest obiektem danej klasy
issubclass(klasa1,klasa2) – sprawdza, czy klasa1 wywodzi się z klasy2
IX. Generatory
Generatorem jest funkcja zwracająca kolejne wyniki z listy podczas jej kolejnych wywołań.
Funkcja taka zawiera zazwyczaj pętlę generującą wyniki, w której to pętli są one na bieżąco
oddawane instrukcją „yield” (zamiast „result” oddający całą listę wyników po zakończeniu pętli).
Generatorem może też być wyrażenie typu „obliczenia for zmienne in lista_lub_funkcja”.
X. Przegląd bibliotek standardowych
Na zakończenie pierwszej części opracowania wymienię kilka częściej używanych modułów
Pythona z przykładami dostarczanych przez nie funkcji. Niektóre z nich dokładniej omówię w
drugiej części. Informacje poniższe można tylko traktować jako informację, gdzie można znaleźć
potrzebne nam funkcje.
os – podstawowe funkcje odnoszące się do systemu operacyjnego:
.system(komenda) – wykonuje podaną komendę, wypisując rezultat na standardowe wyjście
(co akurat jest mało przydatne), a zwraca kod zakończenia (0 – wykonano bez błędów)
.getcwd() - zwraca aktualną ścieżkę dostępu
.chdir(sciezka) – zmienia aktualną ścieżkę dostępu na wskazaną.
shutil – bardziej zaawansowane polecenia systemu operacyjnego, np.:
.copyfile(plik1,plik2) – kopiuje plik
.move(plik,plik_lub_folder) – w zależności od parametrów zmienia nazwę pliku lub przenosi
go w inne miejsce.
glob.glob(maska) – tworzy listę plików (wraz ze ścieżkami) pasujących do maski (z użyciem * i ?).
1-11
sys – kolejny moduł z funkcjami systemowymi, tym razem nie skupiający się na poleceniach
powłoki a pozwalający programom uzyskać dostęp do ich środowiska. Funkcji ma wiele, a
przykładowe to:
.argv() - lista argumentów wywołania programu; zerowy element to nazwa programu wraz ze
ścieżką dostępu
.stdin .stdout .stderr – dostęp do standardowego wejścia i wyjść programu
.exit() – wyjście z programu (stosuje się też jako „elegancki” sposób wyjścia z interpretera)
.platform - identyfikacja systemu operacyjnego.
re – wyszukiwanie i edycja wyrażeń regularnych (pomocne w programach wykonujących analizę
tekstów lub tworzenie dokumentów na podstawie szablonów.
math – funkcje matematyczne (nazwy nie wymagają wyjaśnienia), np.:
.sin .cos .pi .log
random – funkcje generujące wartości losowe:
.random() - podaje liczbę zmiennoprzecinkową z zakresu od 0 do 1
.randrange(liczba) – podaje liczbę losową z podanego zakresu (można podać początek i
koniec zakresu a nawet wartość „kroku”)
.choice(lista) – podaje losowo wybrany element listy
.sample(lista, ilosc) – podaje losową próbkę elementów listy o podanej liczebności; jeżeli
chcemy listę losowych liczb, możemy użyć „xrange(zakres)” jako listy wejściowej
Uwaga: Elementy w próbce nie powtarzają się (chyba, że powtórzyły się na liście
wejściowej). Oznacza to, że jeżeli ilość losowań równa jest wielkości listy – dostajemy po
prostu listę „potasowaną”, a próba zwiększenia liczby losowań spowoduje „ValueError”!
urllib2 – moduł pozwalający pobierać pliki z sieci
.urloopen(url,dane) – pobiera plik ze wskazanego adresu (http); argument „dane” można
pominąć, lub przekazać w nim informacje dla serwera (np. wysłać formularz dla skryptu php
lub asp). Funkcja zwraca otwarty obiekt pliku (który trzeba przeczytać i zamknąć).
Dodatkowe funkcje i struktury danych definiowane w module pozwalają np. przesłać hasło
dla serwera, itp.
smtlib – moduł pozwalający wysłać e-mail
.SMTP(serwer) – otwiera połączenie do serwera, zwracając jego obiekt (trzeba je potem
zamknąć metodą obiektu „quit()”). Do „rozmowy” z serwerem służą metody obiektu:
putcmd(komenda, parametry) i getreply(). Informację na temat akceptowanych komend
można uzyskać od serwera odczytując tekst zwracany przez metodę help().
datetime – moduł umożliwiający obliczenia związane z datą i czasem – wymaga dokładniejszego
omówienia (w 2 części), natomiast na razie kilka informacji „na zachętę” o datach:
.date(rok,miesiac,dzien) – zwraca obiekt daty (na obiektach można dokonywać potem
obliczenia, jak dodawanie i odejmowanie – różnice czasu symbolizuje
.timedelta(liczba_dni)). Obiekty te użyte z instrukcją print przyjmują format czytelny dla
człowieka (który można dowolnie dobrać przy pomocy metody „strftime”)! Obiektt
„timedelta” można dodatkowo mnożyć i dzielić.
.date.today() - zwraca datę dzisiejszą
gzip bz2 zipfile tarfile – moduły do kompresji i dekompresji plików
.open(plik,tryb,stopien_kompresji) – zastępuje standardowe polecenie „open” (patrz. rodz.
VI) otwierające plik i zwracające jego obiekt, przy czym odnosi się do plików
skompresowanych określonym algorytmem (stopień kompresji można pominąć – przyjmie
wartość domyślną). Z otwartego pliku korzysta się w sposób standardowy, przy czym nie
należy zmieniać miejsca odczytu (poleceniem „seek”), bo może to zdezorientować procedury
1-12
dekompresujące.
zlib – moduł do kompresji danych (algorytm podobny do „gzip”)
.compress(tekst,stopien_kompresji) – kompresuje ciąg znaków (stopień można pominąć)
.decompress(tekst) – dekompresuje ciąg znaków
.crc32(tekst) – liczy sumę kontrolną
timeit – moduł do pomiaru czasu wykonywania poleceń
.Timer(polecenia).timeit() - zwraca czas wykonania poleceń
textwrap – moduł służy do zawijania długich tekstów tak, aby mieściły się w określonej liczbie
kolumn. Jeżeli w tekście źródłowym były znaki końca linii – ignoruje je (zamienia na spacje).
.wrap(tekst,liczba) – zwraca listę linijek tekstu (nie dłuższych niż podana liczba)
.fill(tekst,liczba) – działa podobnie ale zwraca cały tekst, z odpowiednio wstawionymi
znakami końca linii.
string – moduł zawierający funkcje dotyczące operacji na ciągach znaków, część funkcji
(opisywanych w dokumentacji) tak naprawdę jest dostępnych już bez tego modułu (np. lower,
upper, capitalize, split). Do ciekawych zastosowań modułu należy natomiast szablon:
.Template(szablon) – obiekt szablonu tekstowego – tworząc go podajemy ciąg znaków,
zawierający oznaczenia zmiennych typu „$zmienna” lub „${zmienna}” (jeżeli znak „$” nam
się nie podoba, to możemy zdefiniować klasę potomną z podmienioną zmienną „delimiter”).
Obiekt szablonu ma metodę .substitute(zmienna=wartosc, ...) tworzącą na podstawie
szablonu tekst z podstawionymi zmiennymi (uwaga na „KeyError”), oraz bezpieczniejszą
.safe_substitute(slownik) podmieniającą to, co da się podmienić.
struct – moduł służący do przekształcania danych binarnych (struktur przechowujących dane w
języku „C” i innych) w struktury danych Python'a i odwrotnie.
.pack zamienia wartości zmiennych binarnych w ciąg znaków o zadanym formacie
.unpack wykonuje odwrotną zamianę.
threading – moduł pozwalający tworzyć aplikacje wielowątkowe. Dokładniej zostanie on
omówiony w drugiej części. A teraz tylko podstawowe informacje.
.Thread to klasa wątku, od której wyprowadza się klasę potomną ze zdefiniowaną metodą
„__init__” oraz „run(self)”. Wątek taki uruchamia się w programie metodą .start; aby
zaczekać na zakończenie wątku można użyć metody .join
Moduł definiuje również metody komunikacji pomiędzy wątkami, choć do tego lepiej użyć
kolejek – Queue, które zostaną dokładniej omówione razem z wątkami.
logging – moduł do tworzenia „logów” programu; posiada metody .debug .info .warning .error
.critical z jednym parametrem – tekstem komunikatu
weakref – do monitorowania istnienia zmiennych w pamięci (?)
array – pozwala na korzystanie z jednorodnych tablic (list zmiennych jednakowego typu) znanych
z klasycznych języków programowania (w Pythonie niby niepotrzebne, ale zajmują mniej
pamięci niż listy)
.array(typ,domyslny) – tworzy tablicę określonego typu i ewentualnie nadaje jej polom
wartości domyślne (jeżeli podano drugi argument – listę, ciąg znaków lub iterator
dostarczający wartości odpowiedniego typu). Typ określa się pojedynczym znakiem (jedna
litera): c-znak (litera, itp...), b-bajt ze znakiem (+/-), B-bajt dodatni (0-255), u-znak Unicode,
h lub i-lb. całkowita (2b) ze znakiem, H lub I-lb. całkowita dodatnia, l-długa lb. całkowita
(4b) ze znakiem, L-dodatnia lb całkowita długa, f-lb. zmiennoprzecinkowa (4b), d-duża liczba
zmiennoprzecinkowa (8b).
Obiekt tablicowy ma szereg metod, jak np. .count .index .append .insert .pop .remove
1-13
.extend .fromfile .fromlist .fromstring .tofile .tolist .tostring .reverse
collections – pozwala na korzystanie z kolekcji (typów przypominających listy, lecz działających
szybciej)
bisect – umożliwia stosowanie specjalnych argumentów sortujących
heapq – pozwala na korzystanie z samosortującego się stosu, który na pozycji zerowej zawsze ma
najmniejszą wartość. Stosu można używać jak listy, a moduł udostępnia specjalne funkcje:
heappush(stos,element) – dorzuca element do stosu
heappop(stos) – zdejmuje element ze stosu podając jego wartość (bez zdejmowania
sprawdzimy ją przez „stos[0]”)
heapreplace(stos,element) – kombinacja powyższych: zdejmuje ze stosu najmniejszy element
i jednocześnie dorzuca nowy; podaje wartość elementu zdjętego
heapify(lista) – zamienia nieposortowaną listę na posortowany stos
decimal – ulepszony „float” pozwalający na dokładniejsze obliczenia, lepsze zaokrąglanie, operacje
typu „modulo” itp. Gorąco polecany przy tworzeniu aplikacji finansowych (pozwala uniknąć
nieprzewidywalnych końcówek wynikających z zaokrąglania). Pozwala ustawić odpowiedni
kontekst obliczeń (precyzję zaokrągleń, itp.). Liczby zapisuje się używając konstruktora
„Decimal” z jednym argumentem – tekstowym zapisem liczny (w „decimal__doc__” jest
dużo przykładów zapisu). Obsługuje wynik dzielenia przez zero - „Infinity” oraz nieistniejący
„NaN” (można ustawić, czy ma wtedy zgłaszać wyjątek, czy nie).
1-14