Sieciowe serwery baz danych
Sieciowe serwery baz danych
ZAGADNIENIA
Historia powstania MySQL
Początki i rozwój serwera PostgreSQL
Komercyjne systemy bazodanowe
MySQL
Początki MySQL sięgają roku 1995, gdy Michael Widenius (znany jako Monty) rozpoczął
pracę, wraz z Dawidem Axmarkiem, nad kodem bazy MySQL, który ukończyli w 1996 r.
Projekt tworzony był w TCX DataKonsult AB i jako MySQL AB został sprzedany Sun
Microsystems w 2008 r. Baza danych MySQL swoją nazwę prawdopodobnie odziedziczyła
po córce Wideniusa – My. Monty stworzył jeszcze jeden SZBD oparty na MySQL oraz
silniku Aria. Produkt znany jest jako MariaDB. 27 stycznia 2010 roku Sun Microsystems
został przejęty przez Oracle za 7,4 miliardów dolarów na podstawie porozumienia
podpisanego 20 kwietnia 2009 r. Od tego czasu MySQL rozwijany jest przez Oracle. Mimo
że kod MySQL dostępny jest na licencji GPL, ma również wersje komercyjne, które cechuje
rozszerzona funkcjonalność. SZBD MySQL wykorzystywany jest bardzo często przez firmy
hostingowe, ponieważ cechuje go duża szybkość transakcji.
Nie zmniejsza to stabilności, szybkości i wysokiej funkcjonalności pozostałych systemów,
takich jak PostgreSQL. Systemy bazodanowe, podobnie jak systemy operacyjne, mają swoich
zwolenników i przeciwników, a spory toczone pomiędzy nimi przypominają „święte wojny”
na tle religijnym. Celem tego podręcznika nie jest testowanie wydajności i funkcjonalności
obu systemów, tylko przygotowanie przyszłych informatyków do stawiania pierwszych
kroków w administracji i konfiguracji SZDB.
PostgreSQL jest jednym z najstarszych i najlepiej przetestowanych serwerów
bazodanowych. Serwer ten ma bardzo wiele rozszerzeń w formie wtyczek (plugins), które
sprawiają, że może konkurować z komercyjnymi SZBD najwyższej klasy. Historia stgreSQL
sięga roku 1970, kiedy to na uniwersytecie Berkeley powstał projekt Inter aktywnej Grafiki w
Systemie Wyszukiwawczym (INGRES). W1980 r. poprawioną wersję skrócono do Postgres.
W 1993 r. projekt oficjalnie zakończono w Berkeley. Rozwojem Postgresa zajęła się
społeczność open source pod nazwą Postgres95. Ponieważ system Sten wspierał SQL, jego
nazwa została zmieniona na PostgreSQL, którą nosi do dziś. PostgreSQL wykorzystują z
powodzeniem firmy i instytucje przetwarzające duże ilości danych, np. Skype, United States
Federal Aviation Administration (FAA). Instalację PostgreSQL można przeprowadzać na
różne sposoby w zależności od przeznaczenia systemu operacyjnego. Oprócz wymienionych
wyżej systemów, które omawiane są ze wzglądu na popularne oraz na łatwy i darmowy
dostęp (każdy może je za darmo pobrać i testować), istnieją również systemy komercyjne,
które oprócz profesjonalnych zastosowań cechuje wysoka cena. Ze względu na to, iż w
przypadku chęci użycia produktów firmy Microsoft czy Oracle należy przygotować się na
wydatek kilku lub kilkudziesięciu tysięcy złotych, stosowane są one w firmach, które stać
również na przeprowadzanie szkoleń z obsługi tych systemów, i Nie bez znaczenia pozostaje
to, że większość narzędzi prezentowanych w obrębie tego podręcznika ma interfejsy zbliżone
do ww. komercyjnych rozwiązań. Dokładne poznanie sposobu administrowania, użytkowania
i projektowania przy użyciu MySOL i PostgreSQL będzie bardzo pomocne w wypadku, gdy z
rozwiązań darmowych zajdzie potrzeba migracji do rozwiązań komercyjnych, np. zastąpienia
MySQL lub PostgreSQL bazą danych Microsoft SQL Server lub SZBD Oracle.
1
Do czego może służyć serwer - serwer bazy danych 1
Z serwerem plików „spokrewniony” jest serwer bazy danych. Wspólna funkcja to
udostępnianie informacji wszystkim użytkownikom sieci. Różnica polega na tym, że w
przypadku serwera plików informacje są przechowywane w postaci ogromnej ilości plików,
zapisanych w uporządkowany sposób w wielopoziomowym systemie folderów.
Na bazę danych można spojrzeć jak na jeden wielki plik, do którego dostęp kontroluje
specjalne oprogramowanie. Oprogramowanie to odpowiada na zapytania pochodzące od
użytkowników, generowane przez programy, w których użytkownicy pracują. Jako przykład
można podać tu program finansowo-księgowy – wszystkie dane przechowywane są w bazie
danych na serwerze bazodanowym. Użytkownicy uruchamiają na swoich komputerach
programy, które sięgają po potrzebne informacje do bazy danych, wysyłając do serwera
zapytania o konkretne zestawy danych, które serwer bazodanowy następnie wyszukuje i
odsyła. Analogicznie w przypadku konieczności zmiany danych w bazie – nie jest wysyłany
cały plik (jak ma to miejsce w serwerze plików) a jedynie odpowiednie polecenie do serwera
bazy danych wraz z danymi do zapisania.
W przypadku serwera bazy danych rośnie znaczenie procesora, który ma o wiele więcej pracy
niż w przypadku serwera plików. Połączenie sieciowe nie jest już tak istotne, bo z reguły ilość
przesyłanych danych jest mniejsza (ale nie zawsze).
Funkcje serwera bazy danych i serwera plików można z powodzeniem łączyć w jednym
komputerze-serwerze. Należy przestrzegać zasady, aby baza danych była przechowywana na
oddzielnym dysku (logicznym, fizycznym, wolumenie).
Kiedy potrzebuję serwera bazy danych ?
Konieczność uruchomienia serwera bazy danych na ogół narzucona jest przez program, który
chcemy wdrożyć – jak np. wspomniany wyżej program finansowo-księgowy. Konkretny
program zwykle narzuca konkretne wymagania odnośnie serwera (zarówno sprzętu jak i
oprogramowania).
Kiedy nie potrzebuję serwera bazy danych ?
Serwer bazy danych nie jest potrzeby gdy nie korzystasz z programu nie wymagającego bazy
danych, która powinna znajdować się na oddzielnym serwerze.
Co Ci da serwer bazy danych ?
Po pierwsze możliwość korzystania z programu, na który się zdecydowałeś, kierując się jego
funkcjonalnością. Natomiast gromadzenie informacji w bazie danych w porównaniu z plikami
na serwerze plików zapewnia o wiele większą wydajność i bezpieczeństwo.
Przykładowe rozwiązania
1
Obecnie dostępnych jest wiele rozwiązań bazodanowych, np. MS-SQL, Oracle, MySQL,
PostgreSQL. Każdy z wymienionych przykładów wymaga serwera z zainstalowanym
systemem operacyjnym, może to być np. MS-Windows Server (MS-SQL, Oracle), Linux
(MySQL, PostgreSQL, Oracle).
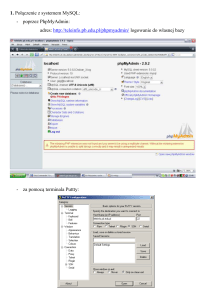
http://lsb.pl/czytelnia/67/do-czego-moze-sluzyc-serwer-serwer-bazy-danych
2
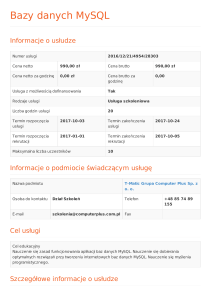
Serwer baz danych a baza danych
Serwer baz danych jest programem, który zarządza bazami danych. Natomiast utworzenie bazy
danych i wypełnienie jej informacjami jest zadaniem programisty lub administratora serwera. Czyli po
zainstalowaniu serwera należy jeszcze zaprojektować i utworzyć bazę danych, dopiero potem będzie
można zastosować serwer w aplikacji WWW.
Baza danych utworzona w jednym serwerze (np. MySQL) nie może być bezpośrednio używana w
innym środowisku (np. PostgreSQL), ale same tabele i zapisane w nich dane mogą być dość łatwo
przenoszone pomiędzy serwerami. Znacznie gorzej wygląda kwestia przeniesienia utworzonych w
bazie procedur lub funkcji.
SZBD działające w architekturze klient-serwer
Większość obecnie spotykanych systemów działa w trybie klient-serwer, gdzie baza danych
jest udostępniana klientom przez SZBD będący serwerem. Serwer bazy danych może
udostępniać dane klientom bezpośrednio lub przez inny serwer, np. poprzez serwer WWW
lub serwer aplikacji.
Systemy bazy danych w architekturze klient-serwer to m.in.:
DB2
Informix Dynamic Server
Firebird
MariaDB
Microsoft SQL Server
MySQL
Oracle
PostgreSQL
SZBD bez podziału na klienta i serwer
Istnieją bazy danych, które nie muszą być współdzielone przez wielu użytkowników
jednocześnie. W takim przypadku używa się SZBD nierozróżniających podziału na klienta i
serwer, np.
Microsoft Access – zgodny z SQL, korzystający z Microsoft Jet
Kexi – zgodny z SQL, korzystający z SQLite
3
Tabele baz danych – iloczyn kartezjański
Relacja – tabela
Aby wyjaśnić pojęcie relacji, warto odświeżyć kilka istotnych informacji z matematyki i teorii
zbiorów. Iloczyn kartezjański zawdzięcza swoją nazwę kartezjańskiemu układowi
współrzędnych.
Jest to prostoliniowy układ współrzędnych o parach prostopadłych osi.
Nazwa pojęcia pochodzi od łacińskiego nazwiska francuskiego matematyka i filozofa
Kartezjusza (René Descartes), który opisał tę ideę w 1637 r. w traktacie La Geometrie.
Iloczynem kartezjańskim prostej A i B będzie zbiór punktów płaszczyzny zawartej między
nimi (każdy punkt należący do tej płaszczyzny). Idąc tym tokiem myślenia, jeśli będziemy
mieć dwa zbiory A i B, to iloczynem kartezjańskim tych zbiorów będzie taki zbiór C, w
którym każdy element A będzie połączony z każdym elementem B. Prześledźmy tą sytuację
na przykładzie.
Zbiór A przechowujący cyfry
Zbiór B przechowujący imiona
Iloczynem kartezjańskim tych dwóch zbiorów będzie następujący zbiór C, w którym każdemu
elementowi zbioru A, będzie odpowiadał element zbioru B:
4
Teraz spróbujemy zdefiniować relację.
Relacją nazywamy podzbiory iloczynu kartezjańskiego.
Niech podzbiorem dla naszego przykładu będą (1-Jacek, 2 – Ewa). Jeśli umieścimy te
elementy w tabeli, otrzymamy:
Numery
1
2
1
3
2
3
Imiona
Jacek
Ewa
Ewa
Ewa
Jacek
Jacek
Dlatego w relacyjnych bazach danych relacją nazywać będziemy tabele bazy danych,
ponieważ zawartość tabeli ulega ciągłym zmianom. Kolumny – atrybuty mogą przechowywać
wartości określonych typów, jednak wartości te mogą być modyfikowane. Podobnie jest w
naszym przykładzie. Relacja (tabela) przechowuje dane, które zwykle ulegają pewnym
zmianom. Zawartość tabeli, jeśli nie jest modyfikowana, może być rozszerzana o kolejne
wiersze (rew). Operacje, jeśli nie zachodzą w danej chwili, mogą zajść w przyszłości, dlatego
zawartość relacji możemy traktować jako zmienną. Teoretyk baz danych Chris Date
zaproponował określanie tabel w relacyjnych bazach danych mianem relvar. Jest to skrót od
relation (relacja – tabela) oraz variable - zmienna. Ten nowy termin w języku polskim
tłumaczymy jako zmienna relacyjna. Takie definiowanie tabeli w relacyjnej bazie danych ma
na celu uświadomienie osobom poznającym teorie, że tabela spełnia wymogi matematyczne
relacji, a jej zawartość (to co jest przechowywane wewnątrz tabeli) może ulegać zmianom w
określonym czasie.
W większości opracowań dotyczących baz danych pojęcie relacja odnosi się do tabeli w
relacyjnej bazie danych. Problemem teorii baz danych jest stosowanie terminu relacja również
do związków, które występują pomiędzy tabelami (np. relacja jeden do wielu). W efekcie
przyjęcia takiej nomenklatury, gdy chcemy powiedzieć, że pomiędzy tabelą A i tabelą B
5
występuje związek „jeden do wielu”, mówimy, że pomiędzy relacją A a relacją B występuje
relacja „jeden do wielu” (zupełnie tak, jakby oznaczało to istnienie trzeciej tabeli o nazwie
„jeden do wielu”). Jak łatwo zauważyć, postępowanie takie doprowadza do zatarcia sensu
wypowiedzi. W tym podręczniku konsekwentnie używane będą jako synonimy pojęcia relacja
i tabela, a stosunki pomiędzy tabelami nazywane będą związkami, np. związkiem jeden do
wielu, związkiem jeden do jednego.
PRZYKŁAD
Tabela 7.1. Lista reprezentantów Polski w piłce nożnej
Nr Imię
i Data
Występy Gole Klub
nazwisko
urodzenia
/
Wiek
12 Grzegorz
5
września 3
0
Jagiellonia
Sandomierski 1989 / 22 lata
Białystok
1 Wojciech
18
kwietnia 11
0
Arsenał F.C.
Szczęsny
1990 / 22 lata
22 Przemysław 4
stycznia 8
0
PSY
Tytoń
1987 / 25 lat
Eindhoven
Tabela przedstawia fragment składu reprezentacji Polski w piłce nożnej. W dniu 16.07.2012 r.
odpowiadała rzeczywistości, jednak po pewnym czasie jej zawartość może ulec zmianie.
Wystarczy, że któryś z zawodników strzeli gola, wtedy zawartość relacji ulegnie zmianie.
Podobnie dane ulegną modyfikacji po podjęciu decyzji personalnej przez selekcjonera
mającego wpływ na ostateczny skład reprezentacji Polski. W 2013 roku zmieni się również
zawartość kolumny Wiek (każdy z piłkarzy będzie o rok starszy).
Ponieważ zachowanie zawartości relacji przypomina zawartość zmiennej znanej z języków
programowania (pole przechowuje pewną wartość określonego typu i może ulec zmianie),
stąd pisząc o tabeli, której zawartość ulega zmianom, użyjemy pojęcia zmienna relacyjna,
natomiast gdy mamy na myśli tabelę, której zawartość jest rozpatrywani w danej określonej
chwili i nie ulega zmianie, będziemy mówić o wartości relacyjnej lub w skrócie, relacji.
6