Uniwersytet Ekonomiczny
w Krakowie
Praca magisterska
Wybrane zagadnienia koncepcji
głębi danych w dyskryminacji
obiektów ekonomicznych
Mateusz Bocian
Kierunek: Informatyka i Ekonometria
Specjalność: Modelowanie i prognozowanie
procesów gospodarczych
Promotor
Nr albumu: 146310
dr hab. Daniel Kosiorowski
Wydział Zarządzania
Kraków 2014
Spis treści
Wprowadzenie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1. Analiza dyskryminacyjna . . . . . .
1.1. Wprowadzenie . . . . . . . . . . .
1.2. Liniowa analiza dyskryminacyjna .
1.3. Metoda k najbliższych sąsiadów .
1.4. Własności metod . . . . . . . . . .
1.5. Ocena jakości klasyfikatora . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
2. Koncepcja głębi danych . . . . . . . . . .
2.1. Wprowadzenie . . . . . . . . . . . . . .
2.2. Statystyczne funkcje głębi . . . . . . . .
2.3. Klasyfikacja oparta na funkcjach głębi .
2.4. Przykład zastosowania głębi dla danych
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
2
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
5
5
9
10
15
17
. . . . . . . .
. . . . . . . .
. . . . . . . .
. . . . . . . .
funcjonalnych
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
21
21
23
40
42
3. Badanie empiryczne . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.1. Zbiór Iris . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2. Zbiór Boston . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.3. Zbiór pochodzący z badania Current Population Survey . . . . . . .
3.4. Badanie symulacyjne z wykorzystaniem niewypukłych zbiorów danych
49
49
54
57
61
4. Wnioski końcowe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
65
A. Wykorzystane w pracy kody w języku R . . . . . . . . . . . . . . .
67
Literatura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
76
Spis rysunków . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
80
Spis tabel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
82
1
Wprowadzenie
W życiu codziennym oraz w praktyce gospodarczej często spotykamy się
z koniecznością dzielenia lub też łączenia pewnych zjawisk w określone grupy,
klasy czy kategorie. Odpowiednie zarządzanie posiadaną informacją pozwala
na sprawne funkcjonowanie w dzisiejszym świecie, podejmowanie trafnych decyzji biznesowych. Działanie takie nabiera szczególnego znaczenia zwłaszcza
w obliczu czasów charakteryzujących się nadmiarem informacji - już w 1680
roku niemiecki filozof i matematyk Gottfried Leibniz pisał o “straszliwej liczbie
książek, która wciąż rośnie” (Rayward, 1994). Z kolei specjaliści firmy Cisco1 ,
światowego lidera w dziedzinie rozwiązań sieciowych, szacują, że w 2017 roku
roczny rozmiar danych przesyłanych w światowej sieci Internet przekroczy próg
jednego zettabajta2 .
Wraz z rozwojem komputerów i możliwości gromadzenia danych, przed statystykami pojawiły się nowe wyzwania związane z koniecznością analizowania
coraz to większych i coraz bardziej złożonych zbiorów danych. Zdarzenia te
doprowadziły do intensywnego rozwoju gałęzi statystyki zwanej statystyką obliczeniową. Pojawiające się coraz częściej problemy z odpowiednią organizacją
1. Cisco Visual Networking Index: Forecast and Methodology, 2012–2017,
http://www.cisco.com/en/US/solutions/collateral/ns341/ns525/ns537/ns705/ns827/
white_paper_c11-481360_ns827_Networking_Solutions_White_Paper.html,
dostęp: 10.10.2013, 22:00
2. 1 ZB = 109 TB = 1021 bajtów
2
Wprowadzenie
3
i przeszukiwaniem gromadzonych danych, przyczyniły się do powstania wielu
technik eksploracji danych, znanych pod wspólnym określeniem data mining.
Nadmiar informacji stał się w dzisiejszych czasach niebagatelnym problemem. Już w 1967 roku R.L. Ackoff w swojej pracy (1967) zwrócił uwagę na
trudności związane z podejmowaniem przez menedżerów wysokiego szczebla
trafnych decyzji biznesowych, a jako przyczynę wysuwał nadmiar nieistotnej
informacji. Stojąc w obliczu podobnych wyzwań, niezwykle ważne okazuje się
stosowanie metod efektywnie wykorzystujących posiadane dane. Dodatkowo
powinny one charakteryzować się odpornością na szum informacyjny obecny
w danych, tak aby podejmowane decyzje opierały się na istotnej części posiadanej informacji, a pomijały wpływ pewnych obserwacji odstających oraz
zanieczyszczeń danych.
W niniejszej pracy podjęto próbę oceny przydatności ekonomicznej klasyfikatorów opartych na funkcjach głębi danych. Porównano jakość klasyfikacji
tych metod z rezultatami osiąganymi przez klasyfikatory powszechnie wykorzystywane podczas rozwiązywania problemów dyskryminacyjnych. Szczególną
uwagę położono na klasyfikatory maksymalizujące wartość głębi lokalnej, zaproponowane przed kilkunastoma miesiącami przez Paindaveine i Van Bever
(2012b). Propozycja ta zyskuje szczególne znaczenie w kontekście zarysowanego przez autora problemu zanieczyszczenia danych z uwagi na fakt, że w
jej ramach rozwijane są obecnie metody pozwalające na odporną klasyfikację
danych.
Pierwszy rozdział rozwija pojęcie analizy dyskryminacyjnej. W jego obrębie
przedstawiono powszechnie wykorzystywane metody klasyfikacyjne oraz zwrócono uwagę na wyzwania pojawiające się przed analitykiem, zwłaszcza podczas
klasyfikacji danych w wielu wymiarach. Zaprezentowano także metody oceny
jakości klasyfikacji, pozwalające na budowanie tzw. rankingów dyskryminacyjnych. W drugim rozdziale pracy zarysowano koncepcję głębi danych (data
depth concept) oraz zaprezentowano przykład jej zastosowania praktycznego.
Przedstawiono klasyfikatory oparte na funkcjach głębi, bazujące na dwóch
Wprowadzenie
4
różnych podejściach związanych z maksymalizacją wartości głębi globalnej
oraz głębi lokalnej. W trzecim rozdziale, będącym zasadniczą częścią pracy,
zmierzono jakość klasyfikacji osiąganą przez klasyfikatory oparte na koncepcji
głębi danych. Przetestowano ich działanie na zróżnicowanych zbiorach danych i
skonfrontowano z wynikami referencyjnych metod, wykorzystywanych podczas
rozwiązywania problemów klasyfikacyjnych.
Wszystkie symulacje i obliczenia w niniejszej pracy przeprowadzono z wykorzystaniem programistycznej platformy obliczeniowej R Project. Zaimplementowane przez autora algorytmy, niezbędne do przeprowadzenia badania,
przedstawiono w Dodatku A.
Rozdział 1
Analiza dyskryminacyjna
Nadmiar informacji może utrudniać proces uczenia się, wyciągania wniosków, podejmowania decyzji. Niezbędna wówczas staje się odpowiednia redukcja dużej liczby obiektów lub cech do kilku podstawowych kategorii. Zagadnienie to jest przedmiotem rozważań w ramach klasyfikacji bezwzorcowej (inaczej
uczenie, rozpoznawanie bez nauczyciela, ang. unsupervised learning). Ma ona
zastosowanie, gdy nie posiadamy wiedzy o strukturze klas, do których mogą
należeć rozważane obiekty. Klasyfikacja bezwzorcowa często utożsamiana jest
z analizą skupień. Z kolei klasyfikację wzorcową (inaczej uczenie, rozpoznawanie z nauczycielem, ang. supervised learning) przeprowadzamy w sytuacji, gdy
znana jest struktura danych, a więc przynależność konkretnych obiektów do
konkretnych kategorii, a naszym celem jest klasyfikacja (predykcja) przynależności nowych obiektów do znanych klas. Proces ten, nazywany dyskryminacją
(ang. discrimination, Hastie, Tibshirani i Friedman, 2009), będzie przedmiotem
rozważań niniejszego rozdziału.
1.1. Wprowadzenie
W historii rozwoju analizy dyskryminacyjnej wyróżnić można trzy fazy.
Początkowo do opisu grup obiektów wykorzystywano funkcje liniowe zaproponowane przez R.A. Fishera w 1936 roku. Kolejna faza związana była z rozwo5
6
1.1. Wprowadzenie
jem metod probabilistycznych, zgodnie z nurtem badań B.L. Welcha (1939).
W czasie ostatniej, trzeciej fazy, analiza dyskryminacyjna rozpoczęła rozwój w
kierunku statystycznej teorii podejmowania decyzji.
Proces klasyfikacji związany z analizą dyskryminacyjną podzielić można na
dwa główne etapy (Gatnar, 1998):
I. Dyskryminacji, kiedy na podstawie zbioru uczącego, w którym znajdują się poprawnie sklasyfikowane obiekty, znajduje się charakterystyki
poszczególnych klas,
II. Klasyfikacji, gdy obiekty, dla których nie jest znana przynależność do
żadnej ze znanych klas, przydziela się do jednej z nich.
Przedmiotem rozważań będzie zbiór U, a jego elementami będą obiekty
poddane obserwacji. Niech xi = [xi1 , xi2 , ..., xiL ] będzie wektorem realizacji
zmiennych losowych X1 , ..., XL reprezentujących L cech i-tego obiektu, natomiast yi jest realizacją zmiennej zależnej Y, informującą o przynależności
obiektu do określonej klasy i nazywana będzie etykietą. Wówczas każdy obiekt
charakteryzowany jest przez wektor [xi , yi ] o wymiarze 1 × (L + 1). Zbiór ten
dla liczby obiektów równej n przyjmuje postać macierzy
x11 ... x1L y1
x21 ... x2L y2
U = [xi , yi ]n×(L+1) =
...
...
...
.
...
(1.1)
xn1 ... xnL yn
Dysponując zbiorem U, naszym zadaniem jest znalezienie relacji pomiędzy
Y a X = X1 , ..., XL w postaci modelu
Y = f (X) ,
(1.2)
gdzie zmienne X określamy jako predyktory (zmienne objaśniające), a zmienną
Y nazywamy zmienną zależną.
1.1. Wprowadzenie
7
W ogólnym ujęciu celem takiego postępowania jest to, aby na podstawie
modelu 1.2, znając wartości zmiennych charakteryzujących obserwacje, które
nie należą do zbioru U, ustalić wartości zmiennej Y dla tych obserwacji. Będziemy zatem poszukiwać takiej funkcji f , która charakteryzować się będzie
największą dokładnością wskazań co do wartości zmiennej Y. Proces ten, związany z wnioskowaniem o przyszłych stanach badanego zjawiska na bazie jego
modelu, nazywany jest predykcją (Devroye, Györfi i Lugosi, 1996).
Jeśli realizacje zmiennej losowej Y definiowanej w modelu 1.2, mierzone są
na skali nominalnej, wówczas w predykcji zastosowanie znajdą metody analizy
dyskryminacyjnej. Zmienne objaśniane mierzone na pozostałych skalach nie
będą przedmiotem rozważań w niniejszej pracy.
Analiza dyskryminacyjna znajduje szerokie zastosowanie w praktyce gospodarczej. W branży bankowej przy jej pomocy ocenia się zdolność kredytową
kredytobiorcy (por. Marzec, 2008), natomiast w sektorze ubezpieczeń estymuje się ryzyko ubezpieczeniowe, klasyfikując klienta do określonej grupy ryzyka. W medycynie jej wykorzystanie przyczynia się do stawiania trafniejszych
diagnoz, zwiększa prawdopodobieństwo wczesnego wykrycia wielu chorób, pozwala na analizę zaawansowanych pomiarów medycznych. Analiza dyskryminacyjna umożliwia znaczną redukcję kosztów różnorakich kampanii marketingowych, poprzez zakwalifikowanie pojedynczych klientów do poszczególnych
grup odbioru reklamy (uzyskanych wcześniej np. przy pomocy analizy skupień)
i skierowanie akcji tylko do pożądanej grupy klientów. Branża internetowa (wyszukiwarki internetowe) nie mogłyby obejść się bez metod analizy dyskryminacyjnej podczas m.in. kategoryzacji dokumentów tekstowych czy grupowania
stron internetowych i słów wprowadzanych do wyszukiwarki. Metody analizy
dyskryminacyjnej znajdują zastosowanie w rozpoznawaniu pisma ręcznego i
analizie zdjęć lotniczych oraz satelitarnych, w tym nawet o charakterze militarnym podczas rozpoznawania obiektów lub zabudowań wojskowych.
Rozważamy sytuację, gdzie L-wymiarowe obiekty znajdujące się w macierzy
X pochodzą z jednej z j populacji Π1 , ..., Πj , gdzie j ­ 2. Wartości opisujące
8
1.1. Wprowadzenie
poszczególne obiekty związane są z odpowiadającymi im wierszami w macierzy
X o rozmiarze n × L. Wiersze macierzy X podzielić można na j grup X =
T
X1 · · ·
Xj
o wymiarze (ni × L) tak, że macierz Xi reprezentuje próbę
ni obiektów pochodzących z populacji Πi . Z kolei informacja o przynależności
poszczególnych obiektów do danej populacji przechowywana jest w macierzy
Y. Wówczas celem analizy dyskryminacyjnej będzie przyporządkowanie do
jednej z j populacji, obserwacji nienależących do zbioru X (a więc takich, dla
których nie jest znana przynależność do którejkolwiek z populacji Π1 , ..., Πj ),
w oparciu o pomiar x.
W ogólności reguła dyskryminacyjna d związana będzie z takim podziałem
RL na rozłączne obszary R1 , ..., Rj , że ∪ Ri = RL . Reguła d przyjmie zatem
postać (Kosiorowski, 2008):
przyporządkuj x do populacji Πi , jeżeli x ∈ Ri , dla i = 1, ..., j.
Dysponując macierzą danych X, podzieloną na j grup, wykorzystujemy
wektor przeciętnych x̄i i macierz kowariancji z próby Si , a także ich nieobciążone estymatory m1 , ..., mj i Σi . Wówczas w przypadku gdy j = 2 reguła
dyskryminacyjna przyjmie postać:
x → Π1 ⇔ aT {x − 1/2 (x1 + x2 )} > 0,
gdzie aT = S−1
u (x̄1 − x̄2 ) oraz Su =
P
(1.3)
ni Si / (n − j).
Rozważamy sytuację, gdzie nie posiadamy informacji a priori o przynależności badanego obiektu do żadnej z populacji Πi , a więc nie możemy stosować
reguły Bayesa. Nie zakładamy także żadnych szczególnych parametrycznych
postaci rozkładów populacji Π1 , ..., Πj , stąd nie będzie możliwe korzystanie z
reguł dyskryminacyjnych NW (Największej Wiarygodności). Poszukiwać będziemy reguły pozwalającej dyskryminować obiekty pomiędzy populacjami.
9
1.2. Liniowa analiza dyskryminacyjna
1.2. Liniowa analiza dyskryminacyjna
Pierwsze podejście do liniowej analizy dyskryminacyjnej (ang. Linear Discriminant Analysis - LDA) zapronował Fisher w 1936 roku. Rozwiązał on
problem w przypadku dyskryminacji dwóch klas (j = 2), uogólnienie tej koncepcji dla j > 2 klas przedstawili Rao (1948) i Bryan (1951).
Propozycja Fishera związana jest ze znalezieniem takiego wektora a, względem którego liniowa funkcja aT x maksymalizowałaby iloraz międzygrupowej
sumy kwadratów i wewnątrzgrupowej sumy kwadratów. Przez
z = Xa =
X1 a
..
.
Xj a
=
z1
..
.
(1.4)
zj
będziemy rozumieć liniową kombinację kolumn macierzy danych X. Wówczas
całkowitą sumę kwadratów z możemy zapisać jako
zT Hz = aT XT HXa.
(1.5)
Sumę tę można podzielić na wewnątrzgrupową sumę kwadratów
X
zTi Hi zi =
X
aT XTi Hi Xi a = aT Wa,
(1.6)
oraz na międzygrupową sumę kwadratów
X
ni (z̄i − z̄)2 =
X
n
o
ni aT (x̄i − x̄)2 = aT Ba,
(1.7)
gdzie przez z̄i rozumiemy przeciętną i-tego podwektora zi wektora z, natomiast
Hi jest ni × ni macierzą centrującą1 (Kosiorowski, 2008).
Wówczas w sytuacji, gdy zgodnie z koncepcją zaproponowaną przez Fi1. Symetryczna i idempotentna macierz, której pomnożenie przez dany wektor jest równoważne odjęciu od każdego elementu tego wektora średniej z jego elementów.
10
1.3. Metoda k najbliższych sąsiadów
shera, wektor a będzie maksymalizował iloraz międzygrupowej sumy kwadratów i wewnątrzgrupowej sumy kwadratów
aT Ba/aT Wa,
(1.8)
funkcję aT x nazywamy liniową funkcją dyskryminacyjną Fishera (Devroye,
Györfi i Lugosi, 1996). Zamiennie wykorzystywane jest również określenie pierwsza zmienna kanoniczna. W wyżej wymienionej sytuacji wektor a, nazywany
wektorem dyskryminacyjnym Fishera, jest wektorem własnym macierzy W−1 B,
odpowiadającym jej największej wartości własnej.
W wyniku odnalezienia funkcji dyskryminującej możliwe staje się zaklasyfikowanie obserwacji x do jednej z j populacji. W tym celu tworzy się tzw. “ranking dyskryminacyjny” funkcji aT x (Kosiorowski, 2008). Rozważany obiekt x
przyporządkowuje się do tej populacji i, której ranking aT x jest najbardziej
zbliżony do rankingu i-tej przeciętnej, wynoszącego aT x̄i = z̄i . Wówczas regułę
dyskryminacyjną możemy zapisać:
x → Πj ⇔ aT x − aT x̄j < aT x − aT x̄i , dla każdego i 6= j.
1.3. Metoda k najbliższych sąsiadów
Alternatywą dla liniowej analizy dyskryminacyjnej może być metoda k-najbliższych
sąsiadów (ang. k-nearest neighbors rule - k-NN), będąca jedną z najprostszych
i najbardziej znanych metod analizy dyskryminacyjnej z grupy metod nieparametrycznych. Klasyfikacji analizowanego obiektu x dokonuje się poprzez
wybór k obserwacji (sąsiadów) położonych najbliżej niego, a następnie poprzez
przyporządkowanie go do tej klasy, do której należy największa liczba spośród
ustalonych k sąsiadów badanego obiektu. Regułę tę można zapisać jako (Devroye, Györfi i Lugosi, 1996):
gn (x) =
1
jeśli
0
w przeciwnym wypadku,
Pn
i=1
wni I{Yi =1} >
Pn
i=1
wni I{Yi =0}
(1.9)
1.3. Metoda k najbliższych sąsiadów
11
gdzie wni = 1/k jeżeli obserwacja Xi jest jednym z k najbliższych sąsiadów
klasyfikowanego obiektu x, w innym przypadku wni przyjmuje wartość 0. Obserwację Xi nazwiemy k-tym najbliższym sąsiadem x, jeśli odległość kx − Xi k
jest k-tą najmniejszą spośród odległości kx − Xi k , ..., kx − Xn k.
Podczas głosowania może dojść do sytuacji remisowej. Jednym z rozstrzygnięć może być arbitralny wybór klasy, do której przyporządkowany zostanie
badany obiekt. Innym rozwiązaniem jest posłużenie się dodatkowym k + 1
sąsiadem obserwacji [xi, yi ]. Dopuszcza się także wybór tej klasy, której środek
ciężkości jest położony najbliżej obserwacji [xi, yi ] (Gatnar, 2008). Z kolei Devroye, Györfi i Lugosi, aby uniknąć sytuacji remisowych sugerują przyjmowanie
nieparzystej liczby k najbliższych sąsiadów lub stosowanie ważonej metody 2k
najbliższych sąsiadów (por. Devroye, Györfi i Lugosi (1996)).
W przypadku szczególnym, gdy przyjmiemy k = 1, obiekt zostanie sklasyfikowany zgodnie z klasą obserwacji położonej najbliżej niego. Wówczas metoda
k-NN prowadzi do podzielenia przestrzeni zmiennych XL na obszary tworzące
diagram Voronoi’a, nazywany też mozaiką Dirichleta (odpowiednio ang. Voronoi diagram oraz Dirichlet tessellation). Dla każdego obszaru określona zostaje
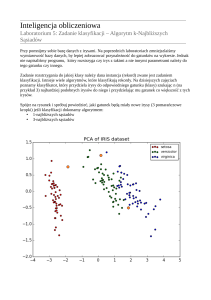
klasa, zgodna z klasą obserwacji znajdującej się w jego wnętrzu. Przykład takiego podziału (w sytuacji gdy k = 1) znajduje się na rysunku 1.2, gdzie
przedstawiono mozaikę dla dwóch wybranych cech znanego zbioru IRIS.
Przed przystąpieniem do analizy, w przypadku możliwości pomiaru cech w
różnych jednostkach, zaleca się standaryzację każdej z cech obiektów macierzy
danych X, tak aby uzyskać przeciętną o wartości 0 oraz wariancję równą 1. W
przeciwnym wypadku cechy, które przyjmują duże wartości, mogłyby niwelować wpływ innych cech. W wyniku tej operacji zmienne o różnych jednostkach
przeprowadzane są w wielkości niemianowane i porównywalne (Hastie, Tibshirani, Friedman, 2009).
Istotnym elementem stosowania metody k-NN jest także wybór metryki, za
pomocą której wyznaczane będą odległości pomiędzy rozważanymi obserwacjami xi oraz xn . Jedną z najczęściej używanych metryk, w przypadku zmien-
12
1.3. Metoda k najbliższych sąsiadów
Rysunek 1.1: Przykład klasyfikacji z wykorzystaniem metody 5-NN, przeprowadzonej na zbiorze obserwacji podzielonych na 2 klasy (po 100 obserwacji na
klasę). Dane pochodzą z pakietu {ElemStatLearn} środowiska R.
Źródło: Obliczenia własne - R Project.
nych o charakterze ciągłym, jest odległość euklidesowa (stosowana również w
pakiecie {class} środowiska R, wykorzystywanym przez autora do obliczeń w
metodzie k-NN) wyznaczana ze wzoru
d (xi , xn ) =
v
u L
uX
t
(x
il
− xnl )2 .
(1.10)
l=1
Konieczne jest zastosowanie odpowiednio dobranej miary odległości, gdy
cechy obiektów mają charakter jakościowy i porządkowy, lub określonej kombinacji tych miar, gdy jednocześnie mamy do czynienia z cechami o różnym
13
1.3. Metoda k najbliższych sąsiadów
4
3
s s
s
s
s
ss
s
ss
ss
s s
ss
s
s
sss
ss
s
0
1
2
DŁUGOŚĆ PŁATKA
5
6
7
v
vvv
v v
v v
vv
v v
v v v
v
v
v v
v
v vv
v
v v
vvv v
v
v
v
vvvv
vv
vv
v
v
v
v
c
v
v
c
c
ccc
cc
c
c
ccc
cc
c
c
c
cc
c c
c
ccc
cc
cc
c
c c
c
c
c
0.0
0.5
1.0
1.5
2.0
2.5
3.0
SZEROKOŚĆ PŁATKA
Rysunek 1.2: Przykład diagramu Voronoi’a dla zbioru IRIS w przestrzeni X2 .
Źródło: Obliczenia własne - R Project.
charakterze. Szerzej o tym zagadnieniu traktuje praca Hastie, Tibshirani i
Friedman (2009).
Istotną decyzją w przypadku stosowania metody k-NN jest wybór wartości k, a więc liczby ustalanych najbliższych sąsiadów klasyfikowanego obiektu.
Niskie wartości parametru k mogą wpływać na większą wrażliwość metody
na lokalne zanieczyszczenia danych, zapewniając jednak algorytmowi znaczną
elastyczność. Z kolei jego wysokie wartości mogą mieć wpływ na uodpornienie
metody na pewne zanieczyszczenia w rozważanym zbiorze obserwacji, ale z drugiej strony np. w przypadku niewypukłych zbiorów danych mogą spowodować
znaczne zniekształcenia wyciąganych wniosków. Warto więc poświęcić więcej
14
1.3. Metoda k najbliższych sąsiadów
uwagi doborowi liczby sąsiadów k, gdyż wybór ten może rzutować na wiarygodność całej analizy. Wartość k powinna być znacznie mniejsza niż liczebność
najmniej licznej kategorii (Gatnar, 2008). Enas i Chai (1986) zaproponowali,
aby przyjąć
K = N 2/8 lub K = N 3/8 ,
(1.11)
gdzie N oznacza liczbę obiektów w zbiorze uczącym. Odmienne podejście zaprezentował Dasarathy (1991) proponując wykorzystanie procedury cross validation do wyboru wartości parametru k, tak aby minimalizowała ona błąd
klasyfikacji. W szczególności, Hastie, Tibshirani i Friedman w swojej pracy
(2009) sugerują w tym celu stosowanie metody 10-fold cross validation. Istotę
0.08
0.06
0.04
0.02
0.00
CV
Blad klasyfikacji ^
e
0.10
oraz stosowanie metod typu cross validation przedstawiono w podrozdziale 1.5.
0
10
20
30
40
50
Liczba najbliższych sąsiadów
Rysunek 1.3: Zależność błędu klasyfikacji ê CV od liczby najbliższych sąsiadów
k dla zbioru IRIS. Ocenę błędu uzyskano przy pomocy metody 10-fold cross
validation.
Źródło: Obliczenia własne - R Project.
Do zalet metody k-NN zaliczyć należy w pewnym stopniu odporność na
zanieczyszczenia danych oraz ograniczenie wpływu obserwacji odstających.
1.4. Własności metod
15
Posiada ona jednak istotne wady - mimo prostoty koncepcji najbliższych sąsiadów, metoda ta okazuje się złożona obliczeniowo, co mocno utrudnia lub
ogranicza stosowanie jej w przypadku zbiorów danych o znacznej liczebności.
Wśród wad należy wymienić dodatkowo wrażliwość na wykorzystaną miarę odległości, a także brak odporności metody na redundancję2 zmiennych (Gatnar,
2008).
Pomimo prostoty metody k najbliższych sąsiadów, jest ona wykorzystywana w przypadku wielu zaawansowanych problemów klasyfikacyjnych, włączając w to m.in. analizę pisma ręcznego, zdjęć satelitarnych czy też wzorców
EKG w medycynie. Zastosowanie tej metody przynosi szczególne korzyści w
sytuacji, gdy klasy mogą tworzyć wiele różnych wzorców, a granice pomiędzy
klasami są bardzo nieregularne (Hastie, Tibshirani i Friedman, 2009).
1.4. Własności metod
Stosowanie opisanej metody liniowej analizy dyskryminacyjnej związane
jest z koniecznością spełnienia dwóch założeń. Dotyczą one bezpośrednio zmiennych reprezentujących cechy obiektów poddawanych klasyfikacji (Gatnar 1998):
1) zmienne powinny posiadać łącznie wielowymiarowy rozkład normalny,
2) macierze wariancji oraz kowariancji poszczególnych klas powinny być
równe.
Założenia te w praktyce okazują się istotnym ograniczeniem dla stosowania
liniowej analizy dyskryminacyjnej. W takich sytuacjach rozwiązaniem może
być zastosowanie metod z grupy nieparametrycznych, wobec których nie są
wymagane żadne założenia co do rozkładów cech. Z uwagi na ten fakt znaczenie
zyskują takie metody jak opisana w podrozdziale 1.3 metoda k-najbliższych
sąsiadów.
2. Nadmiarowość.
16
1.4. Własności metod
Techniki analizy dyskryminacyjnej wrażliwe są na tzw. “przekleństwo wielowymiarowości” (ang. curse of dimensionality). Zjawisko to, zaobserwowane
przez Bellmana w 1961 roku, związane jest z oddalaniem się obserwacji od geometrycznego środka próby, przy ustalonej jej wielkości i przy zwiększającym się
wymiarze. W przypadku wielowymiarowym na ogonach rozkładu gromadzi się
większa masa prawdopodobieństwa niż w przypadku jednowymiarowym. Metody statystyki wielowymiarowej wymagają zatem prób o większej liczności,
0.0
0.2
0.4
b
0.6
0.8
aby zapewnić wiarygodność wyników analizy.
0
5
10
15
L
Rysunek 1.4: Przykład wzrostu długości boku b hiperkostki, zawierającej
frakcję p = 0.1 obserwacji, podczas zwiększania wymiaru zagadnienia L.
Źródło: Obliczenia własne - R Project.
Zakładamy, że obserwacje ze zbioru U znajdują się w przestrzeni ograniczonej L-wymiarową, jednostkową kostką [0, 1]L . Wówczas, aby w pewnej
hiperkostce znalazła się frakcja p z ogólnej liczby obserwacji n, długość jej
boku b wyznacza się ze wzoru:
b=
√
L
p
(1.12)
17
1.5. Ocena jakości klasyfikatora
Na rysunku 1.4 przedstawiono zależność wymiaru zagadnienia i długości
boku b hiperkostki zawierającej frakcję p = 0.1 obserwacji. W szczególności,
aby w hiperkostce o wymiarze L = 10 znalazła się frakcja p = 0.1 obserwacji,
długość jej boku stanowić musi niemal 80% zakresu wartości każdej z cech.
1.5. Ocena jakości klasyfikatora
Celem analizy dyskryminacyjnej jest zbudowanie modelu D, który z jak
największą trafnością będzie określał wartości zmiennej Y dla obserwacji z
rozpoznawanego zbioru. Do oceny jakości predykcji potrzebne jest oszacowanie wartości błędu e (D, T), generowanego przez model dyskryminacyjny D i
ocenianego na podstawie zbioru T.
Precyzji klasyfikacji nie można jednak ocenić bezpośrednio na podstawie
całego zbioru uczącego U, gdyż w oparciu o niego konstruuje się sam model.
Rozwiązaniem może być wykorzystanie dodatkowego zbioru testowego T, zawierającego obserwacje niezależne od zbioru uczącego U. Zbiór taki zachowuje
strukturę zbioru U - również dla znajdujących się w nim obiektów znana jest
wartość zmiennej Y.
Predykcja Ŷ
Wartości
Populacja 1
2
1
n11 n12
2
n21 n22
...
...
...
j
nj1 nj2
empiryczne Y
...
j
...
n1j
...
n2j
...
...
...
njj
Tablica 1.1: Tabela wyników klasyfikacji obserwacji ze zbioru testowego T.
Wówczas jedną z najważniejszych miar służących do oceny trafności klasyfikacji jest frakcja błędnie sklasyfikowanych obserwacji (Gatnar, 2000):
ê T (D, T) =
B (T)
,
N (T)
(1.13)
18
1.5. Ocena jakości klasyfikatora
gdzie N (T) oznacza liczebność zbioru testowego T, natomiast liczbę obiektów
błędnie sklasyfikowanych B (T), oblicza się na podstawie wyników klasyfikacji
przedstawionych w tabeli 1.1, za pomocą wzoru:
B (T) =
j X
j
X
nki oraz i 6= k.
(1.14)
i=1 k=1
Niskie wartości wartości e T (D, T) wskazywać będą na lepszy model dyskryminacyjny. Jednak wykorzystywanie tej miary w praktyce może okazać się
trudne z uwagi na konieczność posiadania dodatkowego, niezależnego zbioru
testowego T. Spełnienie tego warunku zapewnia dobrą ocenę błędu klasyfikacji
obliczaną na podstawie formuły 1.13.
Jeśli nie dysponujemy takim zbiorem, konieczne staje się szacowanie błędu
e (D, U), a więc tylko na podstawie zbioru uczącego U. W takiej sytuacji analityk może zastosować jedno z czterech rozwiązań (Hastie, Tibshirani i Friedman,
2009):
− wykorzystanie całego zbioru uczącego U,
− użycie części zbioru uczącego U jako zbioru testowego,
− zastosowanie metod typu cross validation,
− skorzystanie z metod typu bootstrap.
Jeśli analityk zdecyduje się na wykorzystanie do szacowania błędu całego
zbioru uczącego U, to wówczas ocenę błędu nazywa się oceną resubstytucji lub
zastąpienia (ang. resubstitution estimate, Gatnar, 2008). Jednak ze względu na
fakt, że wartość błędu szacowana na podstawie tego wskaźnika zwykle okazuje
się niedoszacowana, w niniejszej pracy zrezygnowano z wykorzystywania tej
miary podczas oceny jakości modeli dyskryminacyjnych.
Kolejnym podejściem do oceny błędu klasyfikacji jest podział zbioru uczącego U na dwie rozłączne części: uczącą, na bazie której zbudowany zostanie
model oraz testową, która wykorzystana zostanie do określenia jakości zbudowanego modelu dyskryminacyjnego. W pierwszej kolejności określa się, jak
19
1.5. Ocena jakości klasyfikatora
duża część (np. 1/3) obserwacji ze zbioru uczącego U stanie się częścią testową. Następnie ustalona część obserwacji zostaje losowo wybrana ze zbioru
U i przydzielona do zbioru testowego T. Podejście takie posiada wadę - model,
w zależności od konkretnego zbioru obiektów, które pozostały po tej operacji
w zbiorze uczącym U, będzie w każdym eksperymencie wykazywać nieco inne
własności.
Na bardzo dobre oszacowanie błędu klasyfikacji pozwala wykorzystanie
metod typu cross validation (Hastie, Tibshirani i Friedman, 2009). Metoda
k-fold cross validation związana jest z podziałem zbioru uczącego U na k w
przybliżeniu równolicznych i rozłącznych podzbiorów U1 , ..., Uk . Wówczas, aby
oszacować błąd klasyfikacji e (D, U) postępuje się zgodnie z algorytmem:
1. Podziel zbiór uczący U na podzbiory U1 , ..., Uk .
2. Dla każdego i = 1, ..., k:
a) Zbuduj model dyskryminacyjny D w oparciu o zbiór uczący U − Ui
(por. rysunek 1.5),
b) Przyjmując za zbiór testowy zbiór Ui oszacuj wartość błędu klasyfikacji.
3. Oblicz wartość błędu klasyfikacji według wzoru:
ê CV (D, U) =
k
1X
ê T (D, Ui ) .
k v=i
(1.15)
Ocena błędu ê CV (D, U) jest więc średnią ocen uzyskanych w oparciu o poszczególne zbiory testowe U1 , ..., Uk .
Istotną decyzją podczas stosowania metod typu cross validation jest wybór
wartości parametru k - wykorzystanie metody k-fold cross validation z wartością k na poziomie k = n jest znane jako metoda leave-one-out cross-validation.
Stosując to podejście otrzymujemy nieobciążony estymator wartości błędu
e (D, U), jednak wskazania cechować może znaczna wariancja. Nie bez znaczenia, w przypadku dużych zbiorów danych lub zaawansowanych klasyfikatorów, jest aspekt złożoności obliczeniowej - metoda ta wymaga k-krotnego
20
1.5. Ocena jakości klasyfikatora
1
2
3
4
5
Część
ucząca
Część
ucząca
Część
ucząca
Część
ucząca
Część
testowa
Rysunek 1.5: Przykład podziału zbioru U na 5 równolicznych części podczas
stosowania metody 5-fold cross validation.
Źródło: Opracowanie własne - R Project.
powtórzenia budowy modelu dyskryminacyjnego. Z kolei ustalanie stosunkowo
niedużych wartości k wiąże się z niższą wariancją wskazań, lecz wpływa na ich
większe obciążenie (Hastie, Tibshirani i Friedman, 2009). Kompromis pomiędzy obciążonością, wariancją wskazań oraz złożonością obliczeniową estymatora zaproponowali Breiman i Spector (1992), proponując przyjęcie k = 5 lub
k = 10.
Z uwagi na bardzo dobre własności oszacowań błędu klasyfikacji e (D, U)
uzyskiwane przy pomocy metody k-fold cross validation, zdecydowano o wykorzystaniu tej metody podczas budowy rankingów modeli dyskryminacyjnych
w dalszej części pracy.
Czwarte podejście do szacowania błędu klasyfikacji e (D, U) na podstawie
zbioru U, z uwagi na brak dodatkowego zbioru testowego T, związane jest
z zastosowaniem metod typu bootstrap. Polega ona na losowaniu (ze zwracaniem) ze zbioru uczącego k niezależnych prób uczących U1 , ..., Uk , z których
każda powinna liczyć n obiektów, a więc tyle ile pierwotny zbiór uczący U. Dla
każdej próby uczącej buduje się model dyskryminacyjny, a następnie testuje
się go na tych obserwacjach, które nie zostały wylosowane do próby uczącej.
Rozdział 2
Koncepcja głębi danych
2.1. Wprowadzenie
W jednowymiarowej analizie statystycznej powszechnie wykorzystywane
są statystyki porządkowe, kwantyle czy też rangi. Ich stosowanie umożliwia
liniowy porządek obserwacji, który występuje naturalnie w przypadku jednowymiarowym. Jednak wiele procedur i miar spotykanych w analizie jednowymiarowej nie ma swoich odpowiedników w wielu wymiarach. Poszukiwać
będziemy zatem porządku obserwacji w wielu wymiarach, bazując na pewnym
wielowymiarowym centrum posiadanego zbioru obserwacji. Stosowanie statystyk porządkowych, kwantyli i rang rozszerzone może zostać na wiele wymiarów dzięki wykorzystaniu koncepcji głębi danych (ang. data depth concept). W
wyniku jej zastosowania analityk dysponować może wielowymiarowymi statystykami porządkowymi. Tak więc zamiast rozważać wektor jednowymiarowych
median, mówić będziemy wówczas o wielowymiarowej medianie, utożsamianej
z wielowymiarowym centrum zbioru obserwacji.
Koncepcja głębi danych należy obecnie do szczególnie intensywnie rozwijających się obszarów wielowymiarowej analizy statystycznej. Jest to nowoczesne
nieparametryczne podejście do odpornej analizy danych wielowymiarowych.
Metody i procedury powstające w ramach tej koncepcji znajdują zastosowanie
w wielu problemach ekonomicznych i stanowią poważną alternatywę dla powszechnie wykorzystywanych metod związanych nie tylko z konstruowaniem
21
2.1. Wprowadzenie
22
wspomnianych wielowymiarowych statystyk porządkowych. Znajdują one zastosowanie w zagadnieniach związanych z eksploracyjną analizą danych oraz
analizą dyskryminacyjną. Procedury bazujące na koncepcji głębi danych wykorzystuje się do badania stacjonarności procesów czy badania podobieństwa
rozkładów. Cechą wyróżniającą metody związane z tą koncepcją jest także
umożliwienie szacowania wielowymiarowych miar rozrzutu czy asymetrii - szerzej, zarówno o funkcjonałach rozrzutu i asymetrii, jak i o koncepcji głębi
danych, traktuje praca Kosiorowskiego (2012).
W koncepcji głębi danych, głębię dowolnego punktu x ∈ Rd , gdzie d > 1,
będącego realizacją wektora losowego X i generowanego przez rozkład prawdopodobieństwa P , definiuje się przy pomocy funkcji nazywanej głębią (ang.
depth) lub funkcją głębi (ang. depth function). Przyporządkowuje ona każdej badanej obserwacji liczbę z przedziału [0; 1], która jest miarą jej centralności wobec rozkładu P , przez który została wygenerowana. Jeśli obserwacja znajduje się blisko centrum rozkładu, funkcja głębi przyjmuje wartości zbliżone do jedności. Z kolei wartości bliskie 0 przyjmuje ona w sytuacji, gdy obserwacja znajduje się na peryferiach rozkładu. Tak więc funkcją
głębi D(x, P ) nazwiemy dowolne odwzorowanie pozwalające na porządkowanie
punktów x ∈ Rd na zasadzie odstawania od centrum d-wymiarowego rozkładu
P generującego te punkty (Kosiorowski, 2008). W przypadku kiedy postać
rozkładu generującego dane nie jest znana, a analityk dysponuje n-elementową
próbą Xn = (X1 , ..., Xn ), rozkład P zastępuje się rozkładem empirycznym Pn .
Obiekt o największej wartości funkcji głębi określa się mianem d-wymiarowej
mediany rozważanego zbioru obserwacji. Jej niewątpliwą zaletą, podobnie jak
w przypadku mediany jednowymiarowej, jest odporność na obserwacje odstające.
Statystyczne funkcje głębi są wszechstronnym narzędziem wykorzystywanym w nieparametrycznej i odpornej analizie wielowymiarowej. Pozwalają na
porządkowanie wielowymiarowych obserwacji względem pewnego centrum rozkładu P , przez który są generowane. Umożliwiają także konstruowanie wielu
2.2. Statystyczne funkcje głębi
23
użytecznych procedur statystycznych rozszerzających klasyczne procedury jednowymiarowe na przypadek wielowymiarowy. Warto także zwrócić uwagę na
odporność na obserwacje odstające wielowymiarowych median, indukowanych
przez funkcje głębi. Własność ta okazuje się szczególnie istotna podczas badania zjawisk ekonomicznych, których próby mogą charakteryzować się niską
dokładnością pomiaru bądź też podatnością na zanieczyszczenia będące efektem działania czynników ubocznych na badane zjawisko.
2.2. Statystyczne funkcje głębi
Niech P oznacza rodzinę rozkładów prawdopodobieństwa określonych na
zbiorach borelowskich w Rd . Przez PX rozumieć będziemy rozkład wektora
losowego X, natomiast każdy obiekt próby Xi traktować będziemy jako wektor
kolumnowy o wymiarze d × 1.
Aby uznać funkcję D(x, P ) za funkcję głębi, konieczne jest spełnianie przez
nią następujących warunków (Kosiorowski, 2012):
1. Niezmienniczość afiniczna: funkcja głębi powinna pozwalać na zmianę
układu współrzędnych bez wpływu na indukowany przez nią porządek.
Własność ta jest szczególnie ważna w sytuacji, gdy rozważa i interpretuje się liniowe kombinacje zmiennych, jak ma to miejsce w analizie
głównych składowych czy też analizie czynnikowej.
2. Wartość maksymalna w centrum: jeśli rozkład P posiada w pewnym
sensie centrum symetrii w punkcie m, funkcja D(x, P ) powinna przyjmować w tym punkcie maksimum.
3. Symetria: Jeśli rozkład P jest w pewnym sensie symetryczny względem
punktu m, to również funkcja D(x, P ) powinna być symetryczna w tym
sensie.
4. Zmniejszanie się wartości wzdłuż promieni: Wartość funkcji głębi po-
2.2. Statystyczne funkcje głębi
24
winna maleć wzdłuż promienia o początku w punkcie, dla którego funkcja przyjmuje wartość maksymalną.
5. Zanikanie w nieskończoności: D(x, P ) → 0, gdy kxk → ∞.
6. Ciągłość D(x, P ) jako funkcji argumentów x.
7. Ciągłość D(x, P ) jako funkcjonał rozkładu generującego P .
8. Quasi wypukłość D(x, P ) jako funkcji x: zbiór {x : D(x, P ) ­ α} jest
wypukły dla każdego α ∈ [0; 1].
Zuo i Serfling (2000) zaproponowali obecnie najbardziej rozpowszechnioną
definicję funkcji głębi. Zgodnie z nią, odwzorowanie D(·, ·) : Rd × P →
− [0, 1]
nazywamy statystyczną funkcją głębi, jeśli spełnia ono następujące warunki:
(P1) Dla dowolnej d × d nieosobliwej macierzy A, dowolnego d wektora b
oraz dla dowolnego wektora losowego X zachodzi D(Ax + b, PAX+b ) =
D(x, PX ), gdzie PAX+b jest rozkładem AX + b, podczas gdy X ma
rozkład P .
(P2) Dla każdego P ∈ P posiadającego w pewnym sensie centrum symetrii
w punkcie m, D(m, P ) = sup x∈Rd D(x, P ) .
(P3) Dla dowolnego rozkładu P ∈ P mającego punkt o największej głębi m,
D(x, P ) ¬ D(λx + (1 − λ)m, P ), λ ∈ [0, 1] dla dowolnego x ∈ Rd .
(P4) Dla każdego P ∈ P D(x, P ) → 0, gdy kxk → ∞.
Jako centrum określać będziemy punkt symetrii, natomiast symetrię rozumiemy jako centralną symetrię (zob. Serfling, 2006).
W literaturze zdefiniowano wiele funkcji głębi - oprócz tzw. głębi położenia (ang. location depths), które są przedmiotem rozważań niniejszego podrozdziału, definiuje się funkcje głębi m.in. na przestrzeni macierzy lub funkcji.
Pomiędzy różnymi głębiami położenia występują istotne różnice, m.in. pod
względem stopnia odporności na wartości odstające czy też stopnia złożoności
obliczeniowej. Dostarczać mogą one analitykowi różnych informacji, w zależności od wykorzystywanych podczas ich definiowania cech rozkładów generujących dane (Kosiorowski, 2012).
25
2.2. Statystyczne funkcje głębi
W koncepcji głębi danych, podczas budowy procedur opartych na funkcjach
głębi oraz wizualizacji struktury danych przez nie indukowanej, niezbędne jest
zdefiniowanie pojęć charakterystycznych dla tej koncepcji. Zbiór:
n
x ∈ Rd : D(x, P ) = α
o
(2.1)
nazywany jest poziomem α lub konturem głębi α. Określa się go także mianem
d-wymiarowego kwantyla rzędu α, α ∈ [0; 1].
Z kolei zbiór, będący obszarem ograniczonym przez kontur głębi α:
n
o
Rα (P ) = x ∈ Rd : D(x, P ) ­ α ,
(2.2)
nazywany jest α przyciętym (centralnym) obszarem, gdzie α ∈ [0; 1].
Na podstawie danej funkcji głębi definiuje się wielowymiarową medianę
jako punkt o maksymalnej głębi. Niech D(x, P ) będzie funkcją głębi, wówczas
wielowymiarową medianę indukowaną przez tę funkcję głębi definiujemy jako:
M (P ) = arg sup D(x, P ) .
(2.3)
x∈Rd
Do jednych z najprostszych głębi należy głębia Euklidesa, obliczana za
pomocą wzoru:
DEU K (y, Xn ) =
1
,
1 + ky − x̄k
(2.4)
gdzie przez x̄ rozumiemy wektor średnich z n-elementowej próby Xn .
Kolejnym przykładem stosunkowo prostej i popularnej funkcji głębi jest
głębia Mahalanobisa definiowana jako:
DM AH (y, Xn ) =
1
,
1 + (y − x̄) S−1 (y − x̄)
0
(2.5)
gdzie S jest macierzą kowariancji z próby Xn . Należy jednak zaznaczyć, że wie-
26
2.2. Statystyczne funkcje głębi
1.0
4
0.8
2
0.6
0
0.4
-2
0.2
-4
0.0
-4
-2
0
2
4
Rysunek 2.1: Wykres konturowy dla głębi Euklidesa z próby w przypadku
danych pochodzących z dwuwymiarowego rozkładu normalnego.
Źródło: Obliczenia własne - pakiet {depthproc} środowiska R.
lowymiarowe mediany indukowane zarówno przez funkcję głębi Euklidesa jak
i Mahalanobisa nie są odporne na obecność w próbie obserwacji odstających.
Głębię symplicjalną (SD) zdefiniowała w swojej pracy R. Liu (1990). Głębię
tego typu w punkcie x ∈ Rd względem pewnego rozkładu F definiuje się jako:
SD(x, F ) = PF {x ∈ S [X1 , ..., Xd+1 ]} ,
(2.6)
gdzie przez S [X1 , ..., Xd+1 ] rozumiemy domknięty sympleks o wierzchołkach
w punktach wyznaczonych przez d + 1 punktów pochodzących ze zbioru X.
Empiryczną wersję powyższej funkcji głębi uzyskuje się przez zastąpienie
w SD(x, F ) rozkładu F jego empirycznym odpowiednikiem Fn obliczanym na
27
2.2. Statystyczne funkcje głębi
podstawie próby Xn = (X1 , ..., Xn ) lub poprzez ustalenie frakcji sympleksów
w próbie Xn = (X1 , ..., Xn ) zawierających punkt x:
n
SD(x, Fn ) =
d+1
!−1
X
1¬ i1 ¬ ... ¬ id ¬ n
I(x∈S [xi , ..., xi ]) ,
1
d+1
(2.7)
gdzie IA oznacza indykator zbioru A.
1.0
6
0.8
4
0.6
2
0.4
0
0.2
-2
-4
0.0
-2
0
2
4
6
Rysunek 2.2: Wykres konturowy dla głębi projekcyjnej z próby w przypadku
danych pochodzących z mieszanki dwóch dwuwymiarowych rozkładów normalnych.
Źródło: Obliczenia własne - pakiet {depthproc} środowiska R.
Głębia Liu charakteryzuje się znaczną złożonością obliczeniową, ujawniającą się wyraźnie w przypadku zbiorów danych liczących kilka tysięcy obserwacji. W istotny sposób utrudnia to jej praktyczne zastosowania. Z myślą wykorzystywania głębi symplicjalnej w analizie wielkich zbiorów danych, zaleca
się stosowanie przybliżonych algorytmów jej obliczania (Kosiorowski, 2012).
Głębia projekcyjna (PD) została zaproponowana przez Y. Zuo (2003). Dla
28
2.2. Statystyczne funkcje głębi
punktu x ∈ Rd pochodzącego z próby Xn = (X1 , ..., Xn ) oblicza się ją według
wzoru:
P D(x, Xn ) = 1 + sup
kuk=1
−1
T
u x − m u T Xn ,
(2.8)
σ (uT Xn )
gdzie m i σ są jednowymiarowymi miarami położenia oraz rozrzutu.
1.0
Mean
Depth Median
0
0.8
0.6
-5
0.4
-10
0.2
-15
0.0
0
5
10
15
Rysunek 2.3: Wykres konturowy dla głębi projekcyjnej z próby w przypadku
zbioru zawierającego obserwacje generowane z dwuwymiarowego rozkładu normalnego oraz 10% obserwacji odstających. Warto zwrócić uwagę na neutralne
zachowanie mediany indukowanej przez funkcję głębi wobec obecności obserwacji odstających (centralne położenie wobec rozkładu głównej części danych).
Z kolei ich obecność wpłynęła negatywnie na wskazanie wielowymiarowej średniej - wskazanie znajduje się na obrzeżach głównej chmury danych.
Źródło: Obliczenia własne - pakiet {depthproc} środowiska R.
Najczęściej stosowaną postacią głębi projekcyjnej dla punktu x ∈ Rd pochodzącego z próby Xn = (X1 , ..., Xn ) jest miara odstawania dowolnej projekcji
x ∈ Rd od mediany tej projekcji (Kosiorowski, 2012). W ujęciu tym wykorzy-
29
2.2. Statystyczne funkcje głębi
stuje się odporne miary położenia oraz rozrzutu, odpowiednio medianę oraz
miarę MAD:
P D(x, Xn ) = 1 + sup
−1
T
u x − M ed uT Xn ,
M AD (uT Xn )
kuk=1
(2.9)
gdzie M ed oznacza jednowymiarową medianę, natomiast przez M AD rozumiemy medianę odchyleń absolutnych od mediany i obliczamy ją według wzoru:
M ADd (Xn ) = M ed d {|xi − M ed (Xn )|} ,
(2.10)
gdzie M ed d = x(bn+dc/2) + x(bn+d+1c/2) /2, bxc oznacza największą liczbę całkowitą mniejszą lub równą x, natomiast przez x(1) ¬ x(2) ¬ . . . ¬ x(n)
rozumiemy uporządkowane obserwacje.
Głębia projekcyjna jest przykładem podejścia znanego w statystyce pod
nazwą projection pursuit - metody badania jednowymiarowych rzutów (projekcji) wielowymiarowej obserwacji.
0.8
1.0
Mean
Depth Median
10
0.7
0.8
0.6
0.6
5
0.5
0.6
0.4
0.4
0.4
0
0.2
0.3
0.2
10
10
5
-5
0.2
5
y
0.0
0
5
10
0
0
x
-5
0.1
Rysunek 2.4: Wykres konturowy (po lewej) oraz wykres perspektywiczny (po
prawej) dla głębi projekcyjnej z próby w przypadku danych pochodzących z
mieszanki trzech dwuwymiarowych rozkładów normalnych.
Źródło: Obliczenia własne - pakiet {depthproc} środowiska R.
Zarówno samą głębię projekcyjną, jak i indukowane przez nią estymatory
2.2. Statystyczne funkcje głębi
30
położenia i rozrzutu, cechują bardzo dobre własności statystyczne w kontekście
odporności, szybkości zbieżności z próby, efektywności oraz nieobciążoności
procedury statystycznej (Zuo i Lai, 2011). Jednak stosowanie głębi projekcyjnej w powyżej przedstawionej postaci jest ograniczane przez znaczną złożoność
obliczeniową, zwłaszcza w sytuacji analizowania wielkich zbiorów danych. Problem ten został w istotny sposób zredukowany dzięki osiągnięciom R. Dyckerhoffa, który w swojej pracy (2004) przedstawił przybliżony algorytm obliczania
tej głębi. Obecnie głębia projekcyjna jest uznawana za jedną z najlepszych
funkcji głębi dla zastosowań ekonomicznych, zapewniając dobry kompromis
pomiędzy odpornością, efektywnością oraz złożonością obliczeniową (Kosiorowski, 2012).
W literaturze odnaleźć można więcej propozycji statystycznych funkcji głębi
- do najpopularniejszych należy głębia domkniętej półprzestrzeni Tukey’a (Tukey, 1975) oraz głębia zonoidalna (Koshevoy i Mosler, 1997). Koncepcje te nie
będą jednak rozwijane w niniejszej pracy.
Wymienione do tej pory funkcje głębi okazują się odpowiednie tylko dla
rozkładów wypukłych oraz jednomodalnych (por. Zuo i Serfling, 2000). Z kolei,
w wielu zastosowaniach praktycznych rozkłady badanych cech nie są wypukłe
lub też charakteryzują się wielomodalnością. W przeciągu ostatnich kilku lat
przedstawiono propozycje, które pozwoliły na tyle uelastycznić metody bazujące na koncepcji głębi danych, że mogą być one z powodzeniem stosowane
także w przypadku rozkładów niewypukłych lub wielomodalnych. Jedno z takich podejść znane jest pod określeniem głębi lokalnej (ang. local depth). W
2011 roku Agostinelli i Romanazzi zaproponowali lokalne wersje głębi domkniętej półprzestrzeni oraz głębi symplicjalnej (por. Agostinelli i Romanazzi, 2011).
Z kolei Paindaveine i Van Bever (2012b) przedstawili podejście pozwalające na
przemianę dowolnej funkcji głębi położenia w jej wersję lokalną. Zaletą takiego
podejścia jest fakt, że jego stosowanie nie wymaga tworzenia definicji wersji
lokalnych dla poszczególnych funkcji głębi.
Głębia lokalna Paindaveine i Van Bever definiowana jest jako głębia glo-
2.2. Statystyczne funkcje głębi
31
balna warunkowana przez pewne sąsiedztwo (zbiór sąsiadujących obserwacji)
rozważanego punktu. Koncepcja ta jest ściśle oparta na koncepcji głębi danych
- sąsiedztwo rozważanego punktu nie jest określane z wykorzystaniem miar
odległości, jak ma to miejsce m.in. w metodzie klasyfikacyjnej k najbliższych
sąsiadów, lecz z użyciem procedury wykorzystującej m.in. głębię symplicjalną
do określania sąsiedztwa punktu (Paindaveine i Van Bever, 2012a).
Dla potrzeby zdefiniowania głębi lokalnej Paindaveine i Van Bever, oprócz
α przyciętego centralnego obszaru Rα (P ) (por. wzór 2.2), dla dowolnego β ∈
[0; 1] na jego podstawie definiuje się także najmniejszy obszar głębi z zawartością prawdopodobieństwa P większą lub równą β:
Rβ (P ) =
\
Rα (P ) , gdzie A (β) = {α ­ 0 : P [Rα (P )] ­ β} .
(2.11)
α∈A(β)
Zarówno otrzymany zbiór Rβ (P ) jak i zbiór Rα (P ) utożsamiać można z
określonym w pewien sposób sąsiedztwem punktu x o najwyższej wartości
funkcji głębi. Indeksację dolną i górną wykorzystuje się celowo, by odróżnić
przycięte na pewnym poziomie obszary głębi (α) od obszarów głębi o pewnej
zawartości prawdopodobieństwa (β).
Zdefiniowanie głębi lokalnej wymaga również wprowadzenia pojęcia sąsiedztwa (ang. neighborhoods) dowolnego punktu x ∈ Rd . Paindaveine i Van
Bever (2012a) zaproponowali zastąpienie rozkładu generującego P przez jego
wersję Px poddaną tzw. symetryzacji. Symetryzacji próby dokonuje się poprzez
zastąpienie rozkładu generującego P = P X przez rozkład
1
1
Px = P X + P 2x−X .
2
2
(2.12)
Tak więc do oryginalnej próby dodaje się odbicia punktów próby względem
x, tak by punkt x stanowił centrum. W wyniku zastosowania tej procedury
uzyskuje się oparte na głębi sąsiedztwa punktu x w odniesieniu do rozkładu
P : Rx,α (P ) oraz Rxβ (P ), związane odpowiednio z α-przyciętym obszarem cen-
32
2.2. Statystyczne funkcje głębi
tralnym oraz z najmniejszym obszarem o zawartości prawdopodobieństwa β.
Parametr α (odpowiednio β) odgrywa rolę parametru lokalności (ang. locality
parameter) - mniejsze sąsiedztwo związane jest z większą wartością parametru
1
-2
-1
0
y
2
3
4
α (odpowiednio z większą wartością parametru β).
-1
0
1
2
3
x
Rysunek 2.5: Przykład symetryzacji zbioru danych. Oryginalny zbiór obserwacji oznaczono kolorem jasnoczerwonym. Symetryzację przeprowadzono względem punktu o współrzędnych x = (1, 1), zaznaczonego na rysunku za pomocą
czarnego krzyżyka. Obserwacje powstałe wskutek symetryzacji, oznaczono kolorem niebieskim.
Źródło: Obliczenia własne - R Project.
Na podstawie tak zdefiniowanego sąsiedztwa bazującego na głębi, definiuje
się głębię lokalną zaproponowaną przez Paindaveine i Van Bever (2012b). Niech
D( · , P ) będzie funkcją głębi. Wówczas związaną z nią funkcję głębi na poziomie lokalności β (inaczej β-lokalną funkcję głębi, ang. β-local depth function)
definiuje się jako:
LDβ ( · , P ) : Rd → R+ : x 7→ LDβ (x, P ) = D x, Pxβ ,
(2.13)
33
2.2. Statystyczne funkcje głębi
h
i
gdzie Pxβ [ · ] = P · | Rxβ (P ) jest rozkładem warunkowym P , warunkowanym
1
-2
-1
0
y
2
3
4
przez Rxβ (P ) - sąsiedztwo rozważanego punktu x.
-2
-1
0
1
2
3
4
x
Rysunek 2.6: Przykład symetryzacji zbioru danych - oryginalny zbiór stu obserwacji (kolor jasnoczerwony) wygenerowano
z dwuwymiarowegorozkładu
nor 0
10
X
malnego P o wektorze średnich 0 i macierzy kowariancji 0 1 . Punkt o
współrzędnych x = (1, 1), względem którego dokonano symetryzacji, oznaczono czarnym krzyżykiem. Z kolei dodatkowe obserwacje pochodzące z rozkładu P 2x−X powstałe wskutek symetryzacji, oznaczono kolorem niebieskim.
Warto zauważyć, że punkt x początkowo znajdujący się na peryferiach rozkładu P X , po symetryzacji stanowi centrum rozkładu Px = 12 P X + 12 P 2x−X .
Źródło: Obliczenia własne - R Project.
Autorzy wyżej przedstawionej głębi proponują podczas jej definiowania
stosowanie parametryzacji względem β. Nie zalecają wykorzystywania parametryzacji α z uwagi na fakt, że maksymalny poziom przycięcia α∗ (P ) =
maxx∈Rd D(x, P ), a więc i zakres wartości α, zależy od rozkładu generującego
34
2.2. Statystyczne funkcje głębi
P oraz funkcji głębi D. Co więcej, sąsiedztwo Rx,α (P ) mogłoby mieć zerowe
prawdopodobieństwo względem rozkładu P dla α bliskiego α∗ (P ), przez co
głębia LDα (x, P ) = D(x, P [ · | Rx,α (P )]) nie byłaby poprawnie zdefiniowana.
Z kolei głębia β-lokalna okazuje się zawsze poprawnie zdefiniowana, a zakres
wartości β nie zależy od rozkładu P ani od funkcji głębi D - parametr β zawsze
przyjmuje wartości od 0 do 1.
LICZBA PRZESTĘPSTW / 10000 mieszk.
1.0
0.8
15
0.6
10
0.4
0.2
5
0.0
5
10
15
20
25
30
POZIOM BEZROBOCIA [%]
Rysunek 2.7: Wykres konturowy dla głębi lokalnej Paindaveine i Van Bever na
poziomie lokalności β = 0.4, z wykorzystaniem głębi projekcyjnej, na podstawie danych GUS. Na rysunku zaznaczono dwuwymiarowe obserwacje, zawierające informację o poziomie bezrobocia (w %) i liczbie przestępstw przeciw
rodzinie (na 10 000 mieszkańców) w poszczególnych jednostkach terytorialnych
Polski w 2006 roku.
Źródło: Obliczenia własne - pakiet {depthproc} środowiska R.
Konstrukcja głębi lokalnej (2.13) może być stosowana wraz z dowolną funkcją głębi D, zapewnia ona także niezmienniczość afiniczną na każdym poziomie
lokalności β. Głębia lokalna rozszerza koncepcję zwykłej głębi globalnej - dla
35
2.2. Statystyczne funkcje głębi
β = 1 sprowadza się ona do wyjściowej globalnej funkcji głębi D (Paindaveine
i Van Bever, 2012b).
Rozważając empiryczne zastosowanie β-lokalnej głębi, rozpatrujemy d-wymiarowe
obserwacje X1 , ..., Xn generowane przez rozkład P . Przez P (n) oznaczamy jego
empiryczny odpowiednik związany z próbą X1 , ..., Xn . Empiryczne odpowied
niki regionów Rα (P ) i Rβ (P ) oznaczamy odpowiednio jako Rα P (n)
oraz
Rβ P (n) .
Dla każdej obserwacji x ∈ Rd rozważa się wersję rozkładu P (n) poddaną symetryzacji, rozpatrujemy więc rozkład empiryczny związany z próbą X1 , ..., Xn , 2x−
X1 , ..., 2x−Xn . Niech D( · , P ) będzie funkcją głębi, wówczas empiryczną wersję
związanej z nią β-lokalnej głębi definiuje się jako (Paindaveine i Van Bever,
2012b):
LDβ · , P (n) : Rd → R+ : x 7→ LDβ x, P (n) = D x, Pxβ,(n) ,
(2.14)
gdzie Pxβ,(n) oznacza rozkład empiryczny bazujący na tych punktach spośród
Xi , które należą do zbioru Rxβ P (n) . Zbiór Rxβ P (n) jest najmniejszym empirycznym obszarem głębi zawierającym co najmniej proporcję β z 2n wektorów
losowych X1 , ..., Xn , 2x − X1 , ..., 2x − Xn lub równoważnie - zawierającym proporcję β z n orginalnych punktów Xi (dzięki temu, że po operacji symetryzacji
centrum kolejnych obszarów głębi staje się punkt x). W sytuacji, gdy dla zbioru
punktów uporządkowanych według wartości głębi, miejsce podziału dla proporcji β podzieli sekwencję punktów o takiej samej wartości głębi (przypadki
takie w literaturze angielskiej określa się jako ties), Rxβ P (n) zawierać będzie
więcej punktów niż wynikałoby to z proporcji β.
Paindaveine i Van Bever (2012b) w swojej pracy przedstawili algorytm
obliczania empirycznej wersji β-lokalnej funkcji głębi LDβ x, P (n) . Procedura
obliczania głębi punktu x ∈ Rd w odniesieniu do rozkładu P (n) obliczanego na
podstawie próby X1 , ..., Xn przebiega według następujących kroków:
1. Oblicz D Xi , Px(n) , i = 1, ..., n, gdzie Px(n) jest rozkładem empirycznym
36
2.2. Statystyczne funkcje głębi
obliczanym na podstawie próby poddanej symetryzacji X1 , ..., Xn , 2x −
X1 , ..., 2x − Xn .
2. Uporządkuj obserwacje (pochodzące z orginalnej próby) według sche
matu D X(1) , Px(n) ­ D X(2) , Px(n) ­ . . . ­ D X(n) , Px(n) .
n
3. Określ nβ Px(n) = max ` = [nβ] , ..., n : D X(`) , Px(n) = D X([nβ]) , Px(n)
4. Oblicz LDβ x, P (n)
o
.
= D x, Pxβ,(n) , gdzie Pxβ,(n) jest empirycznym
rozkładem związanym z próbą X(1) , ..., X(n
(n)
β (Px ))
.
1.0
6
0.8
4
y
0.6
2
0.4
0
0.2
-2
0.0
-2
0
2
4
6
8
x
Rysunek 2.8: Wykres konturowy dla głębi projekcyjnej z próby w przypadku
danych pochodzących z mieszanki dwóch dwuwymiarowych rozkładów normalnych.Wykres konturowy dla głębi lokalnej Paindaveine i Van Bever na
poziomie lokalności β = 0.1, z wykorzystaniem głębi projekcyjnej. Punkty
przedstawione na wykresie są mieszaniną dwóch dwuwymiarowych rozkładów
normalnych (dla każdego 100 obserwacji). Zastosowanie głębi lokalnej pozwoliło na wyodrębnienie kilku rozdzielnych obszarów o wysokiej wartości głębi i
uwzględnienie wielomodalności rozkładu.
Źródło: Obliczenia własne - pakiet {depthproc} środowiska R.
Obliczenia związane z szacowaniem wartości β-lokalnej funkcji głębi LDβ x, P (n)
w przypadku dużych zbiorów danych mogą okazać się czasochłonne. Konieczne
jest obliczenie n + 1 wartości głębi - n wartości głębi z próby składającej się
37
2.2. Statystyczne funkcje głębi
z 2n obserwacji w Kroku 1 oraz jednej wartości głębi z próby o liczebności
nβ Px(n) (¬ n) w Kroku 4. Jednak w wielu zastosowaniach praktycznych użycie głębi β-lokalnej sprowadza się do szacowania głębi tylko w jednym bądź
kilku punktach, jak ma to miejsce m.in. w problemach klasyfikacyjnych (w
przypadku ustalonej wartości parametru β). Aspekt wykorzystywania funkcji
głębi podczas klasyfikacji obiektów zostanie poruszony w podrozdziale 2.3.
1.0
25
POZIOM BEZROBOCIA [%]
0.8
20
0.6
15
0.4
10
0.2
5
0.0
1
2
3
4
5
6
STOPA INFLACJI [%]
Rysunek 2.9: Wykres konturowy dla głębi lokalnej Paindaveine i Van Bever na
poziomie lokalności β = 0.5, z wykorzystaniem głębi projekcyjnej, na podstawie danych Eurostat. Na rysunku przedstawiono dwuwymiarowe obserwacje,
zawierające informację o poziomie bezrobocia (w %) i stopie inflacji rok do
roku (w %) dla krajów Unii Europejskiej w 2012 roku. Warto zwrócić uwagę
na obecność kilku maksimów lokalnych głębi podczas stosowania głębi lokalnej
- wykorzystanie głębi globalnych nie dopuszcza takiej możliwości.
Źródło: Obliczenia własne - pakiet {depthproc} środowiska R.
Odrębny nurt w koncepcji głębi danych stanowią badania funkcji głębi
określanych na przestrzeni funkcji. Narzędzia rozwijane w ramach tej koncepcji
znajdują zastosowanie w odpornej analizie szeregów czasowych i w przypadku
zjawisk ekonomicznych zmieniających się na przestrzeni czasu (por. rysunek
2.10). Na szczególną uwagę zasługuje funkcjonalny wykres ramka-wąsy (ang.
38
2.2. Statystyczne funkcje głębi
functional boxplot) rozwijany w obrębie tej koncepcji, będący uogólnieniem wykresu ramka-wąsy (por. rysunek 2.11) na przypadek danych w postaci szeregów
czasowych (por. Sun i Genton, 2011).
29
28
27
26
25
24
TEMPERATURA [ °C]
30
Temperatura powierzchni Centralnego Pacyfiku
Sty
Lut
Mar Kwi Maj Cze
Lip
Sie Wrz Paź
Lis
Gru
MIESIĄC
Rysunek 2.10: Przykład zbioru obserwacji funkcjonalnych - miesięczne
pomiary temperatury powierzchni Centralnego Pacyfiku w latach 1950-2012.
Źródło: Obliczenia własne - pakiet {fda} środowiska R.
Niech xi (t) , ..., xn (t) będzie zbiorem funkcji rzeczywistych, należących do
C [0, 1] ciągłych funkcji zdefiniowanych na przedziale [0, 1]. Wykres funkcji x
będzie zatem podzbiorem R2 (Kosiorowski, 2012):
G (x) = {(t, x(t)) : t ∈ [0, 1]} .
(2.15)
Dla dowolnej funkcji x pochodzącej ze zbioru funkcji {x1 , ..., xn } , j ­ 2 zde-
39
2.2. Statystyczne funkcje głębi
finiować można zbiór punktów przedziału [0, 1], dla których funkcja x znajduje
się wewnątrz pasma wyznaczanego przez obserwacje xi1 , xi2 , xij :
(
)
Aj (x) ≡ A(x; xi1 , xi2 , ..., xij ) ≡ t ∈ [0, 1]: min xr (t) ¬ x(t) ¬ max xr (t) .
r=i1 ,...,ij
r=i1 ,...,ij
(2.16)
Rysunek 2.11: Przykład funkcjonalnego wykresu ramka-wąsy – inflacja w krajach UE w latach 1997-2011, na podstawie danych Eurostat. Czarna linia wewnątrz wykresu przestawia przebieg mediany funkcjonalnej.
Źródło: Obliczenia własne - pakiet {fda} środowiska R.
Niech λ będzie miarą Lebesque’a na przedziale [0, 1], wówczas przez λ (Aj (x))
rozumiemy frakcję czasu, w którym funkcja x znajduje się wewnątrz pasma.
Niech
n
GSn(j) (x) =
j
!−1
X
1¬i1 <i2 <···<ij ¬n
λ A(x; xi1 , ..., xij ) , j ­ 2.
(2.17)
2.3. Klasyfikacja oparta na funkcjach głębi
40
Uogólnioną głębię pasma, zaproponowaną przez Lopez-Pintado i Romo
(2006), określa się jako część czasu, w którym wykres funkcji x(t) należy do
pasma wyznaczonego przez pozostałe krzywe i definiuje jako:
GSn,J (x) =
J
X
GSn(j) (x), J ­ 2.
(2.18)
j=2
Zastosowanie głębi pasma dla danych funkcjonalnych umożliwia określenie
porządku dla pewnej rodziny krzywych. Możemy obliczyć głębię pasma każdej
krzywej i uporządkować je malejąco ze względu na wartość głębi. Jeśli przez
y[i] (t) oznaczymy krzywą powiązaną z i-tą największą wartością głębi pasma, to
wówczas krzywą o najwyższej wartości głębi uznajemy za najbardziej centralną
krzywą i nazywamy medianą funkcjonalną (por. rysunek 2.11).
2.3. Klasyfikacja oparta na funkcjach głębi
Za pierwszą propozycję zastosowania koncepcji głębi danych w zagadnieniach klasyfikacyjnych uznać można pracę Hardy i Rasson (1982), którzy badali objętości powłok wypukłych wyszczególnionych skupisk. Popularne obecnie podejście, znane w literaturze anglojęzycznej pod określeniem max-depth,
zostało wprowadzone przez Liu i in. (1999), a jego własności badali m.in.
przez Ghosh i Chaudhuri (2005). Kolejny klasyfikator oparty na koncepcji
głębi wprowadził Li i in. (2012) definiując tzw. DD-klasyfikator. Szczegóły tej
propozycji można znaleźć także w pracy Lange, Mosler i Mozharovskyi (2012).
Koncepcja DD-klasyfikatora nie będzie jednak rozwijana w niniejszej pracy.
Klasyfikatory oparte na funkcjach głębi przypisują badany punkt x do tej
populacji, wobec której jest on najbardziej centralny. W szczególności - klasyfikator max-depth przyporządkowuje punkt x do tej populacji, w której wartość
głębi tego punktu jest największa.
Rozważamy sytuację, gdzie dysponujemy n×d próbą uczącą Z, reprezentującą populacje Π1 , ..., Πk w d wymiarach. Poszukujemy reguły L, pozwalającej
41
2.3. Klasyfikacja oparta na funkcjach głębi
n
o
dyskryminować obiekty pomiedzy populacjami. Niech Πj = x1 , ..., xnj , j =
1, ..., k będzie nj × d podmacierzą Zj próby uczącej Z związaną z nj obserwacjami pochodzącymi z populacji Πj . Naszym celem jest przyporządkowanie
nowej obserwacji y niezależnej od Z do jednej z populacji Π1 , ..., Πk . Regułę
klasyfikacyjną L, funkcjonującą w ramach koncepcji klasyfikatora max-depth,
można zapisać jako:
L (y | z) = arg maxj D(y | Πj ) .
(2.19)
Reguła L przyporządkowuje zatem nową obserwację y do tej populacji Πj , w
której wartość głębi y jest największa. Jej konstrukcja pozwala na stosowanie
wraz z nią dowolnej głębi położenia.
Kosiorowski w swojej pracy (2012) zaproponował modyfikację reguły max-depth
polegającą na włączeniu klasyfikowanego punktu w skład próby uczącej podczas budowy rankingu klasyfikacyjnego populacji. Propozycję tę bazującą na
głębi projekcyjnej można zapisać jako:
L (y | z) = arg maxj P D(y | Πj ∪ {y}) ,
(2.20)
gdzie przez P D(y | Π) oznaczamy głębię projekcyjną punktu y obliczaną na
podstawie próby Π = {x1 , ..., xn }.
Paindaveine i Van Bever (2012b) pokazali, że głębia globalna może zawodzić w przypadku zbiorów niewypukłych. Wykazali, że również wskazania
klasyfikatora max-depth bazującego na głębi globalnej mogą być obciążone wysokim błędem klasyfikacji w sytuacji, gdy obserwacje nie są generowane przez
rozkład wypukły. Aby rozwiązać problem związany z tego typu rozkładami,
zaproponowali oni klasyfikator max-local-depth, uzyskiwany poprzez zastąpienie w definicji (2.19) klasyfikatora max-depth głębi globalnej przez β-lokalną
głębię LDβ :
L (y | z) = arg maxj LDβ (y | Πj ) .
(2.21)
2.4. Przykład zastosowania głębi dla danych funcjonalnych
42
Zmodyfikowana w ten sam sposób propozycja Kosiorowskiego (2.20) przybiera postać:
L (y | z) = arg maxj LDβ (y | Πj ∪ {y}) ,
(2.22)
Poziom lokalności β ∈ (0, 1] ustala się wykorzystując metodę cross-calidation,
tak by minimalizował on błąd klasyfikacji obliczany dla próby uczącej. Paindaveine i Van Bever, stosując w obliczeniach wersję lokalną głębi półprzestrzeni
Tukey’a, wykazali bardzo dobre wyniki klasyfikacji uzyskane z wykorzystaniem
ich propozycji (por. Paindaveine i Van Bever, 2012b).
2.4. Przykład zastosowania głębi dla danych
funcjonalnych
Jednym z przykładów niebanalnego wykorzystania statystycznych funkcji
głębi w badaniach ekonomicznych jest estymacja funkcji gęstości, bazująca
na koncepcji głębi danych dla danych funkcjonalnych, zaproponowanej przez
Lopez-Pintado i Romo (2009). Kosiorowski i Bocian w swojej pracy (2013)
przedstawili procedurę odpornej i nieparametrycznej estymacji funkcji gęstości
dla danych panelowych. Dane tego rodzaju pojawiają się w analizie ekonomicznej w szeregu zagadnień, m.in. w statystyce regionalnej, statystyce społecznej
czy też na rynkach finansowych. Estymacja funkcji gęstości w przypadku danych tworzących skupiska stanowi szczególne wyzwanie w sytuacji obecności
obserwacji odstających. Odporny estymator funkcji gęstości powinien uwzględniać obserwacje wchodzące w skład głównej części danych i z kolei ograniczać
wpływ jednostek odstających na oszacowanie globalnej funkcji gęstości.
Propozycja ta bazuje na koncepcji nieparametrycznego estymatora funkcji
gęstości k-najbliższych sąsiadów (Loftsgaarden i Quesenberry, 1965). Niech
X1 , ..., Xn oznaczają niezależne zmienne losowe o takim samym rozkładzie w
Rd o gęstości f . Oznaczmy za pomocą λ miarę probabilistyczną związaną ze
zmienną losową X oraz niech Sx,ε oznacza domkniętą kulę o promieniu ε > 0
2.4. Przykład zastosowania głębi dla danych funcjonalnych
43
wycentrowaną w x. Estymator gęstości k-najbliższych sąsiadów Loftsgaarden
i Quesenberry definiujemy za pomocą formuły:
fn (z) =
k
,
(2.23)
λ Sz,kz−x(k) (z)k
gdzie x(k) (z) jest k-tym najbliższym sąsiadem z pośród x1 , ..., xn . Bliskość obserwacji ujmuje się w kategoriach zwykłej odległości euklidesowej.
Istnieje co najmniej kilka sposobów na “uodpornienie” nieparametrycznego
estymatora funkcji gęstości. W niniejszej propozycji procedury estymacji gęstości metodą k-najbliższych sąsiadów wykorzystano w tym celu głębię symplicjalną dla określania sąsiedztwa punktów (por. wzór 2.6).
Niech X1 , ..., Xn oznaczają niezależne zmienne losowe o takim samym rozkładzie w Rd o gęstości f . Oznaczamy za pomocą µ miarę probabilistyczną
związaną ze zmienną losową X, a co(x1 , ..., xn ) oznacza otoczkę wypukłą wokół punktów x1 , ..., xn . Wówczas estymator gęstości k-najbliższych sąsiadów
zdefiniować można jako:
fn (z) =
k
n
o ,
µ co x(k) (z)
(2.24)
gdzie x(k) (z) jest zbiorem k-najbliższych sąsiadów z pośród x1 , ..., xn , 2z −
x1 , ..., 2z − xn w sensie głębi symplicjalnej - podejście to związane jest z symetryzacją próby, a więc dodaniu do oryginalnej próby odbić punktów próby
względem z, tak aby punkt z stanowił centrum, por. wzór 2.12 i rysunek 2.6).
Za punkt wyjścia dla rozważań przyjęto model komponentów wariancyjnych (VARCOMP)
yij = β + bi + εij , i = 1, ..., N, j = 1, ..., ni .
(2.25)
Uwagę skupiono na oszacowaniu gęstości prawdopodobieństwa h dla zmiennej losowej Yi w oparciu o dane pochodzące z N paneli. Założono przy tym,
44
2.4. Przykład zastosowania głębi dla danych funcjonalnych
że zmienne w panelach są mieszaninami pewnej ogólnej zmiennej X o gęstości
f oraz zmiennej Wi specyficznej dla każdego z paneli z osobna (np. związanej
z modelem SETAR) o gęstości gi :
Yi = (1 − β)X + βWi , i = 1, ..., N.
(2.26)
Zakładano, że w każdym skupisku może pojawiać sie pewna frakcja γ obserwacji odstających, a typ odstawania może różnić się pomiędzy skupiskami.
Frakcja obserwacji odstających γ powinna być istotnie mniejsza od wielkości
β definiującej mieszaninę (2.26). Rozważano zatem zanieczyszczone dane
zij = yij + oij , i = 1, ..., N, j = 1, ..., ni .
(2.27)
gdzie oij ∼ Fi , Fi to rozkład generujący zanieczyszczenie.
Za cel postawiono oszacowanie globalnej funkcji gęstości f zmiennej X i
gęstości gi zmiennych reprezentujących efekty związane ze skupiskami Wi , przy
pominięciu wpływu obserwacji odstających. Nie zakładano jakiejkolwiek wiedzy nt. klasy gęstości f oraz gi . W sytuacji takiej nie można zatem skorzystać
ze standardowych metod parametrycznej estymacji funkcji gęstości.
Założono dysponowanie na tyle niewielkimi próbami nij w obrębie każdego
skupiska (panela) w porównaniu do liczby rozpatrywanych skupisk N , że nie
jest możliwe szacowanie gęstości oddzielnie dla każdego ze skupisk. Dodatkowo
dopuszczono możliwość występowania różnego typu obserwacji odstających w
obrębie każdego ze skupisk.
Kosiorowski i Bocian w swojej pracy (2013) przedstawili procedurę szacowai
nia globalnej gęstości f . Zakładamy, że dysponujemy obserwacjami{zij }N,n
i=1,j=1 ,
rozpatrywanymi z perspektywy modelu zdefiniowanego za pomocą (2.26) i
(2.27). Przy stosowanych w tym modelu oznaczeniach zaproponowano wykorzystanie następującego algorytmu:
1. Ustalamy α ∈ (0, 0.5) np. na podstawie uprzednio zdobytej wiedzy.
45
2.4. Przykład zastosowania głębi dla danych funcjonalnych
n
n
2. Dane z każdego skupiska dzielimy na dwie części Ai = zij : D(zij |Zi j ) > α
n
n
n
o
i Bi = zij : D(zij |Zi j ) ¬ α , gdzie D(zij |Zi j ) oznacza wartość funkcji
n
głębi zij pod warunkiem próby Zi j .
3. Dla każdego skupiska szacujemy oddzielnie gęstości fˆi w oparciu o dane
ze zbioru Ai oraz ĝi w oparciu o dane ze zbioru Bi za pomocą metody
k-najbliższych sąsiadów.
4. Za oszacowanie globalnej gęstości przyjmujemy medianę funkcjonalną
Lopez-Pintado i Romo fˆ = M EDM BD {fˆi } (por. wzór 2.18).
5. Za oszacowania efektów specyficznych dla skupisk przyjmujemy oszacowane w kroku 3 gęstości ĝi .
6. Procedurę powtarzamy kilkukrotnie w celu właściwego wyboru parametru α. Sugerowany jest wybór takiej wartości parametru α, która
0.5
maksymalizuje wartość głębi mediany Lopez-Pintado i Romo.
0.3
Gęstość
0.4
N(0,1)+t(2,0)
N(0,1)+t(2,1)
N(0,1)+t(2,2)
N(0,1)+t(2,3)
N(0,1)+t(2,4)
N(0,1)+t(2,5)
0.0
0.0
0.1
0.2
1.0
0.5
Gęstość
1.5
N(0,1)+t(2,0)
N(0,1)+t(2,1)
N(0,1)+t(2,2)
N(0,1)+t(2,3)
N(0,1)+t(2,4)
N(0,1)+t(2,5)
-0.5
0.0
0.5
1.0
z
1.5
2.0
0
10
20
30
40
50
z
Rysunek 2.12: Oszacowania gęstości fˆi (po lewej) oraz gęstości ĝi (po prawej)
- wynik pojedynczej symulacji.
Źródło: Obliczenia własne - R Project.
W celu zbadania statystycznych własności propozycji pięćset razy genero-
o
46
2.4. Przykład zastosowania głębi dla danych funcjonalnych
wano dane z modelu, w ramach którego rozpatrywano 6 skupisk, a w każdym
skupisku po 200 obserwacji
Yi = (1 − β)X + βWi , i = 1, ..., 6,
(2.28)
gdzie X ∼ N (0, 1), Wi ∼ t(2, mi ) oraz β = 0.2.
Podczas generowania symulacji wykorzystano model SETAR (ang. Self
Exciting Threshold Auto Regressive model, por. Franses i van Dijk, 2000). Rozważamy jednowymiarowy proces stochastyczny {Xt }t∈T w czasie dyskretnym.
Wówczas model SETAR definiujemy za pomocą równania:
Xt+s =
φ1 + φ10 Xt + φ11 Xt−d + ... + φ1L Xt−(L−1)d + εt+s
φ2 + φ20 Xt + φ21 Xt−d + ... + φ2L Xt−(L−1)d + εt+s
Zt ¬ th
,
Zt > th
(2.29)
gdzie th oznacza pewną stałą, a Zt jest zmienną, od poziomu której uzależniona
jest zmiana reżimu. Z reguły za Zt przyjmuje się zmienną z {Xt , Xt−d , ..., Xt−δd }.
Przyjęto, że w każdym skupisku może występować do 5% obserwacji odstających zij = yij + oij , oi ∼ SET AR(φ0i , φ1i ), δ = 1, th = 3 oraz εt+s ∼ t(3, 0).
Wi ∼ t (2, mi )
Par. niecentr. mi
Skup. 1
m1
0
Skup. 2
m2
1
Skup. 3
m3
2
Skup. 4
m4
3
Skup. 5
m5
4
Skup. 6
m6
5
Tablica 2.1: Specyfikacja Wi w rozważanym modelu.
Skup. 1
Skup. 2
Skup. 3
Skup. 4
Skup. 5
Skup. 6
φ01 φ11 φ02
φ12 φ03 φ13 φ04 φ14 φ05 φ15 φ06 φ16
Zt ¬ th
1 0.1
1 0.25
5 0.2
1 0.9
2 0.4
2 0.3
Zt > th
5 -0.1
5 -0.25 10 -0.2
3 -0.9
6 -0.4
4 -0.3
Tablica 2.2: Specyfikacja oi w rozważanym modelu.
Własności propozycji zostały sprawdzone na przykładzie empirycznym dotyczącym przychodów gospodarstw domowych w podziale na województwa w
roku 2005 – badanie zostało przeprowadzone przez GUS. Z każdego z woje-
47
2.4. Przykład zastosowania głębi dla danych funcjonalnych
0.36
0.98
1.6
-0.87 -0.25
0.36
0.98
1.6
2.22
-0.87 -0.25
0.36
0.98
Skupisko 4
Skupisko 5
Skupisko 6
0.98
z
1.6
2.22
Różnica oszacowań gęstości
2.22
1.6
2.22
-0.5
Różnica oszacowań gęstości
-0.5
0.36
1.6
0.5 1.0 1.5 2.0 2.5
z
0.5 1.0 1.5 2.0 2.5
z
-0.5
-0.87 -0.25
0.5 1.0 1.5 2.0 2.5
-0.5
Różnica oszacowań gęstości
0.5 1.0 1.5 2.0 2.5
2.22
z
0.5 1.0 1.5 2.0 2.5
-0.87 -0.25
Różnica oszacowań gęstości
Skupisko 3
-0.5
Różnica oszacowań gęstości
0.5 1.0 1.5 2.0 2.5
Skupisko 2
-0.5
Różnica oszacowań gęstości
Skupisko 1
-0.87 -0.25
0.36
0.98
z
1.6
2.22
-0.87 -0.25
0.36
0.98
z
Rysunek 2.13: Funkcjonalne wykresy ramka-wąsy dla poszczególnych skupisk.
Różnice bezwzględne pomiędzy wartościami estymowanych funkcji gęstości, a
wartościami funkcji gęstości zbioru referencyjnego.
Źródło: Obliczenia własne - pakiet {fda} środowiska R.
wództw wylosowano po 100 obserwacji. W tym przypadku kryterium maksymalizujące głębię mediany funkcjonalnej wskazało na α = 0.1, jednakże dla
tej wartości usuwanych jest stosunkowo niewiele wartości odstających. Z kolei
poziom 0.4 okazał się być zbyt duży - zbyt wiele wartości jest uznawanych
za odstające, a gęstość szacowana jest jedynie do wartości 3500 zł. Ustalono
w takiej sytuacji α = 0.25 ze względu na ocenę gęstości na obszarze gęstości
wyraźnie powyżej 0, przy jednoczesnym uniknięciu dużych obszarów o bardzo
niskiej gęstości. Wyniki oszacowań przedstawia rysunek 2.14.
W pracy Kosiorowskiego i Bociana (2013) zwrócono uwagę na obiecujące
własności przedstawionej propozycji. Jednak pomimo stosunkowo dobrych wyników symulacji i możliwości jakie prezentuje, posiada ona kilka istotnych wad.
O ile estymacja funkcji gęstości w przypadku niewielkich zbiorów danych, ustalonej wartości α oraz liczby sąsiadów k jest akceptowalna pod względem złożoności obliczeniowej, o tyle poszukiwanie wartości parametru α, która maksyma-
0.0010
Dolnośląskie
Kujawsko-Pomorskie
Lubelskie
Lubuskie
Łódzkie
Małopolskie
Mazowieckie
Opolskie
48
Podkarpackie
Podlaskie
Pomorskie
Śląskie
Świętokrzyskie
Warmińsko-Mazurskie
Wielkopolskie
Zachodniopomorskie
0.0005
0.0000
Gęstość
0.0015
2.4. Przykład zastosowania głębi dla danych funcjonalnych
1000
2000
3000
4000
5000
Przychód gospodarstwa
Rysunek 2.14: Oszacowania gęstości rozkładów przychodów gospodarstw domowych w podziale na województwa w roku 2005, na podstawie danych GUS.
Źródło: Obliczenia własne - R Project.
lizuje wartość głębi mediany Lopez-Pintado i Romo okazuje się bardzo czasochłonne (przynajmniej w przypadku możliwości obliczeniowych przeciętnych
komputerów na przełomie lat 2013/2014), nie uwzględniając czasu potrzebnego na ustalenie optymalnej liczby sąsiadów k, wykorzystywanej w równaniu
2.24. Dodatkowo, w przypadku parametryzacji względem α (por. wzór 2.2)
maksymalny poziom przycięcia α∗ (P ) = maxx∈Rd D(x, P ) zależy od rozkładu
generującego P oraz funkcji głębi D. Zastosowanie parametryzacji względem β
(por. wzór 2.11) zapewniłoby zawsze poprawne zdefiniowanie stosowanej funkcji głębi, co w wyniku braku konieczności monitorowania i ręcznego korygowania przyjętej wartości α, pozwoliłoby na znaczne zautomatyzowanie obliczeń
wykonywanych w obrębie przedstawionej metody.
Rozdział 3
Badanie empiryczne
3.1. Zbiór Iris
Do analiz wykorzystano znany zbiór IRIS, przygotowany przez R.A. Fishera. Zawiera on 150 obserwacji dotyczących kwiatów irysa. Każdy kwiat
charakteryzowany jest przez cztery cechy mierzone w centymetrach: długość
działki kielicha (ddk), szerokość działki kielicha (sdk), długość płatka (dp) i
szerokość płatka (sp). Zmienna zależna, informująca o przynależności kwiatu
do danego gatunku, przyjmować będzie wartości z trójelementowego zbioru
{S, C, V }, odnosząc się odpowiednio do gatunków: Iris Setosa, Iris Versicolor,
Iris Virginica. Każdy z nich reprezentowany jest przez tę samą (50) liczbę
obserwacji. Na rysunku 3.1 przedstawiono wykresy rozrzutu wszystkich par
zmiennych oraz wykres gęstości dla każdej z cech (na przekątnej).
Na rozważanym zbiorze danym przetestowano działanie wyróżnionych w
pracy klasyfikatorów. Obserwacje klasyfikowano przy pomocy liniowej analizy dyskryminacyjnej (LDA) z wykorzystaniem pakietu {class} oraz metody
k-najbliższych sąsiadów (KNN). W przypadku metody k-NN uwzględniono
aspekt, na który zwrócili uwagę Paindaveine i Van Bever (2012b) - ze względu
na wrażliwość na zmianę jednostek metody k-NN, przetestowano także jej
wersję z pomnożoną przez 10 pierwszą współrzędną punktów (KNNx) oraz
z pomnożoną przez 10 drugą współrzędną punktów (KNNy). W przypadku
wszystkich klasyfikatorów związanych z koncepcją k-NN, liczbę k najbliższych
49
50
3.1. Zbiór Iris
2.0
3.0
4.0
0.5
1.5
4.5 5.5 6.5 7.5
ddk
2.5
1 2 3 4 5 6 7
2.0
3.0
4.0
sdk
2.5
dp
1.5
sp
0.5
Setosa
Versicolor
Virginica
4.5 5.5 6.5 7.5
1 2 3 4 5 6 7
Rysunek 3.1: Wykresy rozrzutu dla zmiennych ze zbioru IRIS.
Źródło: Obliczenia własne - R Project.
sąsiadów ustalano na takim poziomie, aby minimalizowała ona błąd klasyfikacji
obliczany przy pomocy metody 10-fold cross validation. Obserwacje klasyfikowano także przy pomocy metody Support Vector Machine (SVM), dostępnej
w pakiecie {e1071} środowiska R - teoretyczne aspekty wspomnianej metody
znaleźć można m.in. w pracy Hastie, Tibshirani i Friedman (2009). Testowano
także klasyfikatory związane z koncepcją max-depth - wykorzystujące funkcję
głębi Mahalanobisa (max-DMAH ), głębię Euklidesową (max-DEUK ) oraz głębię
projekcyjną (max-DPROJ ). Dodatkowo przeprowadzano klasyfikację za pomocą
klasyfikatorów max-local-depth wykorzystujących wymienione funkcje głębi i
oznaczonych odpowiednio przez max-LDMAH , max-LDEUK oraz max-LDPROJ .
Poziom lokalności β ustalano na takim poziomie, aby minimalizował on błąd
klasyfikacji obliczany przy pomocy metody 10-fold cross validation.
W przypadku wszystkich klasyfikatorów opartych na koncepcji głębi danych do zbioru uczącego dodawano klasyfikowaną obserwację, zgodnie z propo-
51
5
4
3
2
DŁUGOŚĆ PŁATKA
6
7
3.1. Zbiór Iris
1
Setosa
Versicolor
Virginica
0.0
0.5
1.0
1.5
2.0
2.5
SZEROKOŚĆ PŁATKA
Rysunek 3.2: Podzbiór zbioru IRIS poddany klasyfikacji.
Źródło: Obliczenia własne - R Project.
zycją Kosiorowskiego (2012). Zabieg ten pozwala uniknąć wielu sytuacji remisowych, gdzie głębia rozważanej obserwacji względem wszystkich skupisk jest
równa 0. Jeśli jednak dojdzie do sytuacji remisowej, obserwacja przydzielana
jest losowo do jednego z tych skupisk, względem których miała najwyższą (taką
samą) wartość głębi. Podczas obliczania wartości głębi wykorzystano funkcje
oferowane przez pakiety {depthproc} i {depth} środowiska R. Ze względu na
fakt, że w momencie przeprowadzania analizy, w żadnym pakiecie środowiska
R nie ukazała się implementacja algorytmu obliczania β-lokalnej głębi zaproponowanej przez Paindaveine i Van Bever (2012b), zdecydowano o własnej
implementacji wspomnianego algorytmu - funkcja napisana w języku R została
załączona w Dodatku A.
52
3.1. Zbiór Iris
Jakość klasyfikacji wszystkich wymienionych klasyfikatorów oceniano przy
pomocy metody 10-fold cross validation z wykorzystaniem funkcji dostępnych
w pakiecie {cvTools} środowiska R. Procedurę oceny jakości klasyfikatorów z
użyciem tej metody prześledzić można w Dodatku A.
Klasyfikacji poddano dwuwymiarowe obserwacje pochodzące ze zbioru IRIS,
zawierające informacje o wartości dwóch cech - szerokości płatka oraz długości
płatka. Klasyfikowany zbiór obserwacji przedstawiony został na rysunku 3.2.
Zbiór ten charakteryzuje się stosunkowo wyraźnym odseparowaniem i wypukłością podzbiorów poszczególnych klas. Obserwacje przyporządkowywano do
jednego z trzech gatunków: Iris Setosa (Setosa), Iris Versicolor (V ersicolor)
oraz Iris Virginica (V irginica). Wyniki klasyfikacji przy pomocy rozważanych
0.20
0.05
0.10
0.15
maxDPROJ
maxLDPROJ
maxLDMAH
maxLDEUK KNN
maxDMAH
KNNx KNNy
LDA
SVM maxDEUK
0.00
BŁĄD KLASYFIKACJI
klasyfikatorów przedstawia rysunek 3.3.
1
2
3
4
5
6
7
8
9
10
11
METODA
Rysunek 3.3: Wyniki klasyfikacji dla podzbioru zbioru IRIS.
Źródło: Obliczenia własne - R Project.
Najlepsze wyniki klasyfikacji uzyskano przy pomocy metod opartych na
koncepcji głębi danych - max-DMAH , max-LDMAH oraz max-LDEUK - błąd klasyfikacji ukształtował się na poziomie 0,027. Nieznacznie gorzej klasyfikowała
metoda KNN. W przypadku zbioru IRIS brak niezmienniczości afinicznej reguły KNN nie wpłynął negatywnie na wskazania klasyfikatorów KNNx oraz
KNNy. Metoda LDA znalazła się w połowie rankingu dyskryminacyjnego z
3.1. Zbiór Iris
53
wynikiem 0,04, a nieco gorsze wyniki dało zastosowanie klasyfikatora SVM
oraz max-DEUK .
Wyraźnie gorzej w przypadku rozważanego zbioru danych wypadły metody
związane z głębią projekcyjną max-DPROJ oraz max-LDPROJ - niemal co piąta
obserwacja okazałaby się niepoprawnie klasyfikowana. Pewną część winy ponosić może rozkład empiryczny obserwacji w poszczególnych klasach - kontury
głębi projekcyjnej nierzadko okazywały się determinowane przez grupę obserwacji o takiej samej pierwszej lub drugiej współrzędnej - rozkłady empiryczne
w niektórych przypadkach okazywały się zbliżone do rozkładów dyskretnych.
Sytuacja taka miała miejsce ze względu na dokładność pomiaru tylko do części
dziesiętnych i uwidaczniała się szczególnie podczas stosowania klasyfikatorów
opartych na głębiach lokalnych.
Rozpatrując szczegółowo wyniki klasyfikatorów związanych z koncepcją
głębi lokalnej, należy zwrócić uwagę na wartości parametru lokalności β, które
pozwoliły na osiągnięcie takich rezultatów. Rejestrowano zależność błędu klasyfikacji od wartości parametru β - stwierdzono wyraźne różnice poziomu β
minimalizującego błąd klasyfikacji w kontekście metody 10-fold cross validation w zależności od wykorzystywanej funkcji głębi. W przypadku głębi Mahalanobisa błąd klasyfikacji osiągał minimum dla β ∈ [0.5; 1], z kolei dla głębi
Euklidesa odpowiednio β ∈ [0.15; 0.4]. Dla głębi projekcyjnej stwierdzono dwa
rejony wartości β minimalizujące błąd klasyfikacji, w pobliżu wartości 0,5 oraz
0,8. Klasyfikator głębi Euklidesowej preferował zatem znacznie mniejszą liczbę
obserwacji podczas obliczania wartości głębi klasyfikowanego punktu w stosunku do pozostałych dwóch klasyfikatorów max-local-depth.
Nieznaczną przewagę w przypadku zbioru IRIS wykazały metody oparte
na funkcjach głębi. W przypadku klasyfikatorów opartych na głębiach lokalnych, przewaga ta została jednak okupiona wielokrotnie dłuższym czasem obliczeń w porównaniu do pozostałych rozważanych metod. Należy jednak zwrócić
uwagę, że w przypadku ustalonej wartości parametru lokalności β, klasyfikatory te charakteryzuje złożoność obliczeniowa porównywalna z klasyfikatorami
3.2. Zbiór Boston
54
max-depth. W praktyce, kiedy klasyfikacji poddawane są pojedyncze obserwacje, złożoność taka zdaniem autora nie wyklucza wspomnianych klasyfikatorów
z zastosowań praktycznych.
3.2. Zbiór Boston
Do porównania skuteczności klasyfikatorów przedstawionych szczegółowo
w podrozdziale 3.1 wykorzystano znany zbiór Boston dostępny w pakiecie
{MASS} środowiska R, opisujący wybrane nieruchomości na przedmieściach
Bostonu w Stanach Zjednoczonych. Zawiera on 506 obserwacji 14-tu zmiennych opisujących bezpośrednio pewne cechy nieruchomości, jak i określających
sytuację demograficzną, społeczną i ekonomiczną w pobliżu nieruchomości dane zawierają informację o średniej liczbie pokoi wchodzących w skład nieruchomości (RM ), liczbie przestępstw na jednego mieszkańca (zmienna CRIM ),
odsetku ludności murzyńskiej (B) i o niskim statusie społecznym (LSTAT ),
frakcji posiadłości o znacznej powierzchni (ZN ) oraz terenów przemysłowych
(INDUS ). Dane opisują także dostęp do infrastruktury transportowej (RAD),
zanieczyszczenie środowiska w rejonie każdej nieruchomości (NOX ), położenie
w stosunku do rzeki Charles River (CHAS ), liczbę uczniów przypadającą na
jednego nauczyciela (PTRATIO) czy też wysokość podatku od nieruchomości
(TAX ).
Do analiz wykorzystano zmienną AGE, zawierającą informację o udziale
procentowym budynków wybudowanych przed rokiem 1940 w stosunku do
ogólnej liczby budynków położonych na obszarze, do którego należała opisywana nieruchomość. Pod uwagę wzięto także zmienną DIS, opisującą odległość
dzielącą nieruchomość od pięciu najważniejszych centrów zatrudnienia w Bostonie oraz zmienną MEDV, informującą o medianie wartości nieruchomości na
obszarze na którym położona była dana nieruchomość poddana badaniu. Dla
55
3.2. Zbiór Boston
2
4
6
DIS
8
10
12
MEDV < med(MEDV)
MEDV >= med(MEDV)
0
20
40
60
80
100
AGE
Rysunek 3.4: Klasyfikowany podzbiór zbioru Boston.
Źródło: Obliczenia własne - R Project.
celów klasyfikacji, zdyskretyzowano zmienną MEDV tworząc sztuczną zmienną
Y o etykietach 0 i 1. Dyskretyzację przeprowadzono według reguły
Y =
0
jeżeli MEDV < med(MEDV )
1
jeżeli MEDV ­ med(MEDV ),
(3.1)
gdzie med(MEDV ) oznacza medianę wartości zmiennej MEDV.
Klasyfikacji poddano zatem dwuwymiarowe obserwacje o współrzędnych
bazujących na wartościach zmiennych AGE oraz DIS. Obserwacje przyporządkowywano do jednej z klas < med(MEDV ) lub ­ med(MEDV ), określając
przewidywaną etykietę, odpowiednio 0 lub 1.
Podzbiory poszczególnych klas rozważanego podzbioru zbioru Boston są
wypukłe, tak jak miało to miejsce podczas analizy zbioru IRIS w podrozdziale
3.1. Jednak w rozważanym ujęciu zbiór ten charakteryzuje się utrudnioną se-
56
3.2. Zbiór Boston
parowalnością klas. Klasyfikowany zbiór obserwacji przedstawiono na rysunku
3.4.
Obserwacje klasyfikowano z wykorzystaniem klasyfikatorów przedstawionych szczegółowo w podrozdziale 3.1. Wyniki klasyfikacji dla rozważanego
0.3
maxLDMAH
KNNy
maxLDEUK
KNN
KNNx
LDA
5
6
7
0.1
0.2
SVM
maxD
maxLDPROJ PROJ
maxDMAH
maxDEUK
0.0
BŁĄD KLASYFIKACJI
podzbioru zbioru Boston przedstawia rysunek 3.5.
1
2
3
4
8
9
10
11
METODA
Rysunek 3.5: Wyniki klasyfikacji dla podzbioru zbioru Boston.
Źródło: Obliczenia własne - R Project.
Najniższy błąd klasyfikacji, oceniany przy pomocy metody 10-fold cross
validation, uzyskano przy pomocy metody SVM. Nieznacznie gorszy wynik
osiągnięto przy pomocy dwóch klasyfikatorów max-local-depth: max-LDMAH
oraz max-LDEUK - ich wyniki są zauważalnie lepsze w porównaniu do ich odpowiedników w koncepcji max-depth: odpowiednio max-DMAH oraz max-DEUK .
Metody z grupy związanej z regułą k-najbliższych sąsiadów (KNN, KNNx,
KNNy) osiągnęły na tle pozostałych klasyfikatorów dość dobry rezultat. Również w przypadku zbioru Boston, modyfikacja zakresu danych (KNNx, KNNy)
nie wpłynęła istotnie na jakość oszacowań - wyniki w przypadku wszystkich
klasyfikatorów z tej grupy okazały się zbliżone. Nieco niższą jakość klasyfikacji
osiągnięto z wykorzystaniem klasyfikatora LDA oraz wspomnianej wcześniej
metody max-DMAH oraz max-DEUK . Podobnie jak w przypadku danych IRIS,
3.3. Zbiór pochodzący z badania Current Population Survey
57
wyraźnie największy błąd klasyfikacji wykazały metody związane z głębią projekcyjną: max-LDPROJ oraz max-DPROJ .
Analizując szczegółowo jakość klasyfikatorów związanych z koncepcją głębi,
warto zwrócić uwagę na fakt, że wszystkie metody oparte na koncepcji max-local-depth
osiągnęły niższy błąd klasyfikacji niż ich odpowiedniki w koncepcji max-depth.
Podobnie jak w przypadku zbioru IRIS, zachowana została zależność pomiędzy
β minimalizującym błąd klasyfikacji dla różnych klasyfikatorów głębi lokalnych
- największym stopniem lokalności (a więc najmniejszą wartością parametru
β) posługiwała się ponownie lokalna wersja głębi Euklidesowej (0,475). Z kolei
lokalna głębia projekcyjna operowała na poziomie prawie globalnym (0,95).
Lokalna głębia Mahalanobisa preferowała β na poziomie 0,775.
W przypadku zbioru Boston większość rozważanych klasyfikatorów przedstawiała stosunkowo wyrównany poziom jakości klasyfikacji (wyraźniej odstawały jedynie metody związane z głębią projekcyjną). Po raz kolejny większą skuteczność osiągnęły klasyfikatory oparte na koncepcji max-local-depth
w stosunku do tych opartych na koncepcji max-depth. Dodatkowo klasyfikatory max-LDMAH oraz max-LDEUK ponownie znalazły się na czele rankingu
klasyfikacyjnego, lepszy wynik uzyskano jedynie w przypadku metody SVM
i to właśnie ten klasyfikator należy uznać za najlepszy w tym porównaniu,
również ze względu na bardzo krótki czas obliczeń w stosunku do złożoności
obliczeniowej klasyfikatorów max-local-depth.
3.3. Zbiór pochodzący z badania Current Population
Survey
Rozważany zbiór danych pochodzi z badania rynku pracy w Stanach Zjednoczonych, znanego pod nazwą Current Population Survey (CPS), przeprowadzanego w 1985 roku. Zawiera on 534 obserwacje jedenastu cech. W skład
zbioru danych wchodzi 11 zmiennych opisujących płacę, doświadczenie zawodowe oraz informacje na temat płci, wieku czy pochodzenia każdej z ba-
3.3. Zbiór pochodzący z badania Current Population Survey
58
danych osób. Zmienna WAGE informuje o stawce godzinowej w dolarach, z
kolei zmienna OCCUPATION o kategorii zatrudnienia (kadra zarządzająca,
sprzedaż, usługi etc.). Dostępne są także dane dotyczące sektora gospodarki,
w których zatrudnione były badane osoby (SECTOR) oraz dane dotyczące
przynależności do związków zawodowych (UNION ).
Zmienne EDUCATION i EXPERIENCE przechowują informację o odpowiednio liczbie lat edukacji oraz długości doświadczenia zawodowego. Kolejna grupa zmiennych uwzględnia osobiste cechy każdej badanej osoby takie jak wiek (AGE), płeć (SEX ), status małżeński (MARR) czy pochodzenie
(rasa biała, pochodzenie z Ameryki Łacińskiej (Latynosi) lub pozostałe rasy)
- zmienna RACE. Dodatkowo dostępna jest także informacja o części miasta,
w której żyła ankietowana osoba, w podziale na dzielnice południowe oraz
pozostałe (SOUTH ).
Za cel analizy obrano klasyfikację obserwacji do jednej z kategorii zmiennej RACE. Dla zmiennej tej określono trzy etykiety - white, świadczącą o
przynależności badanej osoby do rasy białej, hispanic, mówiącą o pochodzeniu
latynoskim oraz others, w przypadku gdy ankietowana osoba nie należała do
żadnej z poprzednich dwóch grup.
Obserwacje klasyfikowano na podstawie informacji zawartych w dwuwymiarowym podzbiorze zbioru CPS. W jego skład weszła zmienna WAGE, opisująca stawkę godzinową (w dolarach) oraz zmienna EXPERIENCE, informująca o doświadczeniu zawodowym (w latach). Klasyfikowany zbiór danych
przedstawia rysunek 3.6.
Obserwacje klasyfikowano z wykorzystaniem liniowej analizy dyskryminacyjnej (LDA) oraz metody k-najbliższych sąsiadów (KNN). Liczbę k najbliższych sąsiadów ustalano na takim poziomie, aby minimalizowała ona błąd
klasyfikacji obliczany przy pomocy metody 10-fold cross validation. Klasyfikację przeprowadzono także przy pomocy metody Support Vector Machine
(SVM) oraz klasyfikatorów związanych z koncepcją głębi danych - wykorzystano klasyfikatory max-depth - oparte na głębi Mahalanobisa (max-DMAH ),
59
3.3. Zbiór pochodzący z badania Current Population Survey
20
0
10
WAGE
30
40
white
hispanic
others
0
10
20
30
40
50
EXPERIENCE
Rysunek 3.6: Klasyfikowany zbiór pochodzący z badania Current Population
Survey.
Źródło: Obliczenia własne - R Project.
głębi Euklidesowej (max-DEUK ) oraz głębi projekcyjnej (max-DPROJ ). Dodatkowo przeprowadzano klasyfikację za pomocą klasyfikatorów max-local-depth:
max-LDMAH , max-LDEUK oraz max-LDPROJ . Poziom lokalności β ustalano na
takim poziomie, aby minimalizował on błąd klasyfikacji obliczany przy pomocy metody 10-fold cross validation. Wyniki klasyfikacji rozważanego zbioru
danych przedstawia rysunek 3.7.
Najlepszy rezultaty klasyfikacji rozważanego zbioru danych osiągnięto z
wykorzystaniem metod KNN oraz SVM - błąd klasyfikacji w przypadku obu
metod ukształtował się poniżej wartości 0,2. Wśród wyników pozostałych klasyfikatorów zarysowały się pewne grupy, dotyczące w szczególności klasyfikatorów max-local-depth i max-depth. Błąd klasyfikacji metod opartych na głębiach
lokalnych okazał się wyraźnie wyższy od rezultatów metod KNN i SVM - jedynie w przypadku klasyfikatora max-LDPROJ można mówić o akceptowalnej
60
0.6
maxDEUK maxDMAH
0.2
0.4
maxLDEUK
maxLDMAH
LDA
maxDPROJ
6
7
maxLDPROJ
KNN
SVM
1
2
0.0
BŁĄD KLASYFIKACJI
0.8
3.3. Zbiór pochodzący z badania Current Population Survey
3
4
5
8
9
METODA
Rysunek 3.7: Wyniki klasyfikacji zbioru pochodzącego z badania Current
Population Survey.
Źródło: Obliczenia własne - R Project.
jakości klasyfikacji w stosunku do wyników osiągniętych przez metody KNN
i SVM. Metody oparte na głębiach globalnych zawiodły w przypadku rozważanego zbioru danych, znajdując się wraz z metodą LDA na końcu rankingu
dyskryminacyjnego.
Klasyfikatory głębi lokalnych posługiwały się wysokim stopniem lokalności
(niską wartością parametru lokalności β). W przypadku metody max-LDPROJ
był to poziom 0,11. Klasyfikator max-LDMAH preferował nieco mniejszą lokalność na poziomie β = 0, 15, natomiast na najniższej wartości parametru
lokalności operowała metoda wykorzystująca lokalną wersję głębi Euklidesa
(0,05). Co ciekawe, metoda KNN osiągała najniższy błąd klasyfikacji zarówno
dla stosunkowo niskich (k = 15) jak i wysokich (k = 200) wartości liczby
sąsiadów k (parametr ten w pewnym sensie można uznać za poziom lokalności
na jakim operowała metoda KNN).
Po raz kolejny stwierdzono znacznie lepsze wyniki klasyfikacji dla metod
związanych z koncepcją max-local-depth w stosunku do rezultatów osiąganych
przez klasyfikatory max-depth. Pomimo tego, jakość klasyfikacji metod SVM
i KNN ukształtowała się na poziomie nieosiągalnym dla pozostałych rozważa-
3.4. Badanie symulacyjne z wykorzystaniem niewypukłych …
61
nych klasyfikatorów. Klasyfikatory te charakteryzuje też znacznie niższa złożoność obliczeniowa, zwłaszcza w porównaniu do klasyfikatorów opartych na
lokalnych funkcjach głębi - fakt ten może okazać się szczególnie istotny podczas
klasyfikowania znacznie większych zbiorów danych.
3.4. Badanie symulacyjne z wykorzystaniem
niewypukłych zbiorów danych
Aby sprawdzić działanie rozważanych klasyfikatorów w przypadku niewypukłych zbiorów danych, zdecydowano o sztucznym wygenerowaniu dwuwymiarowych danych o kształcie chmury danych zbliżonym do współśrodkowych
okręgów (ang. ring-supported distribution). W tym celu 100 razy symulowano
zbiór danych składający się z N = 3 skupisk, w każdym z nich n = 100
obserwacji.
Symulując dane w pierwszej kolejności dla każdego skupiska generowano
po n wartości ωij , gdzie ωij ∼ U (0; 2π) , i = 1, 2, 3, j = 1, ..., n. Następnie na
tej podstawie, przyjmując promienie okręgów r1 = 1, r2 = 2, r3 = 3, utworzono
dla każdego skupiska n obserwacji dwuwymiarowych
yij = (ri ∗ cos ωij ; ri ∗ sin ωij ) , i = 1, 2, 3, j = 1, ..., n.
(3.2)
Dodatkowo, dla dodania pewnego szumu do wygenerowanych danych, finalne
zbiory obserwacji powstawały poprzez
zij = yij ∗ oij , i = 1, j = 1, ..., n,
(3.3)
gdzie oij ∼ U (0; 1.5), oraz
zij = yij ∗ qij , i = 2, 3, j = 1, ..., n,
(3.4)
3.4. Badanie symulacyjne z wykorzystaniem niewypukłych …
62
gdzie qij ∼ N (1; 0.1). Przykładowy zbiór obserwacji powstały w wyniku jednej
0
-4
-2
y
2
4
takiej symulacji przedstawiono na rysunku 3.8.
-4
-2
0
2
4
x
Rysunek 3.8: Przykład symulowanego zbioru danych o podzbiorach
niewypukłych.
Źródło: Obliczenia własne - R Project.
Klasyfikacji dokonano z wykorzystaniem klasyfikatorów szczegółowo opisanych w podrozdziale 3.1. Błąd klasyfikacji mierzono tak jak dotychczas przy
pomocy metody 10-fold cross validation. Wyniki klasyfikacji dla stukrotnie
wygenerowanej próby, tworzonej według algorytmu przedstawionego powyżej,
przedstawiają wykresy ramka-wąsy na rysunku 3.9.
W przypadku rozważanego zbioru danych najlepsze wyniki klasyfikacji osiągnięto przy pomocy klasyfikatora SVM, metody klasyfikacyjnej KNN oraz metod opartych na koncepcji max-local-depth. Należy jednak zwrócić uwagę na
3.4. Badanie symulacyjne z wykorzystaniem niewypukłych …
63
KNN
KNNx
KNNy
LDA
SVM
maxDMAH
maxDEUK
maxDPROJ
maxLDMAH
maxLDEUK
maxLDPROJ
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
BŁĄD KLASYFIKACJI
Rysunek 3.9: Wyniki klasyfikacji dla niewypukłych zbiorów danych.
Źródło: Obliczenia własne - R Project.
brak niezmienniczości afinicznej metody KNN - jej odpowiedniki, klasyfikujące
ten sam zbiór danych, z przemnożoną przez 10 pierwszą współrzędną obserwacji (KNNx) oraz przemnożoną przez 10 drugą współrzędną (KNNy) charakteryzuje znacznie wyższy błąd klasyfikacji niż w przypadku bazowej metody
KNN. Na sytuację tę zwrócili uwagę Paindaveine i Van Bever, przedstawiając
wyniki klasyfikacji dla różnych typów zbiorów niewypukłych (por. 2012b).
Metoda klasyfikacyjna LDA zupełnie zawiodła w przypadku niewypukłych
zbiorów danych - błąd klasyfikacji na poziomie 0,6-0,7 oznacza skuteczność na
poziomie co najwyżej losowego przyporządkowywania obserwacji do skupisk.
Podobnie sytuacja kształtowała się w przypadku klasyfikatorów max-depth
max-DMAH , max-DEUK oraz max-DPROJ . Koncepcje klasyfikacyjne oparte na
głębi globalnej zupełnie nie radzą sobie ze zbiorami niewypukłymi.
Z kolei wykorzystując klasyfikatory max-local-depth, a w szczególności max-LDEUK
3.4. Badanie symulacyjne z wykorzystaniem niewypukłych …
64
osiągnięto bardzo dobre rezultaty klasyfikacji - jej jakość była zbliżona do tej
prezentowanej przez metodę SVM. Po raz kolejny zachowana została zależność poziomu lokalności β, na którym operowały poszczególne funkcje głębi,
aby zminimalizować błąd klasyfikacji - największym stopniem lokalności (najmniejszą wartością parametru β) posługiwała się ponownie lokalna wersja głębi
Euklidesowej (mediana z symulacji to 0,05). Na najniższym poziomie lokalności
operowała lokalna głębia projekcyjna (0,15). Na poziomie pośrednim pomiędzy
wymienionymi pozostał parametr β w przypadku lokalnej głębi Mahalanobisa,
która preferowała β na poziomie 0,1.
Zdecydowanie najlepszą jakością klasyfikacji dla zbiorów niewypukłych wykazał się klasyfikator SVM - przemawia za tym najniższa mediana błędu klasyfikacji oraz jego nieduży rozrzut. Jednak nawet w przypadku tak dobrego
wyniku bardzo obiecujący wydaje się klasyfikator koncepcji max-local-depth
oparty na głębi Euklidesowej. Charakteryzowała go bardzo zbliżona do metody
SVM jakość klasyfikacji oraz rozrzut błędu. Podsumowując, zarówno klasyfikator SVM, jak i klasyfikatory maksymalizujące wartość głębi lokalnej osiągnęły
satysfakcjonującą jakość klasyfikacji w przypadku rozważanych niewypukłych
zbiorów danych.
Rozdział 4
Wnioski końcowe
Przydatność rozważanych klasyfikatorów w istotny sposób zależeć będzie
od wielkości i typu klasyfikowanego zbioru. Duża liczba obserwacji lub cech z
nimi związanych, może doprowadzić do wydłużenia czasu trwania obliczeń do
czasu nieakceptowanego przez analityka. Jednak w sytuacji obliczeń przeprowadzanych z ustaloną wartością β (a więc wybieraną w sposób arbitralny, nie z
wykorzystaniem metody k-fold cross validation) złożoność obliczeniowa klasyfikatorów max-local-depth jest akceptowalna dla zbiorów liczących do 1000 obserwacji (dwuwymiarowych). W celu zwiększenia szybkości wykonywania obliczeń, autorzy tej koncepcji proponują modyfikacje sposobu dobierania próby
(poprzez metodę bootstrap) oraz wykorzystywania podobieństwa warunkowych
rozkładów prawdopodobieństwa obserwacji położonych blisko siebie (por. Paindaveine i Van Bever, 2012b). W przypadku pewnego rodzaju zbiorów danych
(m.in. o wysokiej liczbie zmiennych mierzonych na skali nominalnej) istotnym ograniczeniem może stać się fakt, że rozważane klasyfikatory bazujące
na koncepcji głębi, do poprawnego działania wymagają obecności zmiennych
objaśniających o charakterze ciągłym.
W niniejszej pracy zarysowano koncepcję głębi danych (data depth concept)
oraz zaprezentowano szeroki wachlarz możliwości analitycznych związanych z
tym podejściem. Przedstawiono klasyfikatory oparte na funkcjach głębi i bazujące na dwóch różnych podejściach maksymalizowania wartości głębi globalnej
65
Rozdział 4. Wnioski końcowe
66
oraz lokalnej. Wszelkie analizy, symulacje, pomiary przeprowadzono z wykorzystaniem programistycznej platformy obliczeniowej R Project. W obliczeniach korzystano przede wszystkim z pakietów {depth} i {depthproc} ogólnie
dostępnych dla platformy R, a także z własnych implementacji algorytmów
przedstawionych w niniejszej pracy.
W zasadniczej części pracy przy pomocy metody k-fold cross validation
zmierzono jakość klasyfikacji osiąganą przez klasyfikatory oparte na koncepcji głębi danych. Przetestowano ich działanie na czterech zróżnicownych zbiorach danych. Osiągnięte rezultaty skonfrontowano z wynikami referencyjnych
metod, szeroko wykorzystywanych podczas rozwiązywania problemów klasyfikacyjnych. Obserwacje przyporządkowywano do odpowiednich klas z wykorzystaniem liniowej analizy dyskryminacyjnej (Linear Discriminant Analysis),
reguły klasyfikacyjnej k-najbliższych sąsiadów (k-Nearest Neighbors Rule) oraz
metody klasyfikacyjnej SVM (Support Vector Machine).
O przydatności w praktyce gospodarczej zaprezentowanych klasyfikatorów
max-local-depth, w dużej mierze decydują względy złożoności obliczeniowej,
zwłaszcza, że jak pokazano w pracy, jakość klasyfikacji tych metod nie odbiega
znacznie od rezultatów osiąganych przez najlepsze znane obecnie metody klasyfikacyjne. W praktyce, kiedy klasyfikacji poddawane są pojedyncze obserwacje,
złożoność taka zdaniem autora nie wyklucza wspomnianych klasyfikatorów z
zastosowań praktycznych.
Badania metod przedstawionych w pracy mogą dotyczyć redukcji ich złożoności obliczeniowej. Właściwość ta zdaniem autora jest największym ograniczeniem, w pewnych przypadkach uniemożliwiającym stosowanie klasyfikatorów
opartych na funkcjach głębi w praktyce gospodarczej.
Dodatek A
Wykorzystane w pracy kody w języku
R
# ========================================================
# FUNKCJA DO OBLICZANIA WARTOŚCI GŁĘBI LOKALNEJ
# ========================================================
localdepth = function(x, DATA, beta=0.5,
depth1="Liu", depth2="Projection") {
#
#
#
#
#
#
#
#
#
#
x
- obiekt, dla którego obliczana jest
wartość głębi lokalnej
DATA
- zbiór danych, względem którego wyznaczana
jest wartość głębi punktu x
beta
- parametr lokalności, przyjmuje wartości
z przedziału (0;1]
depth1 - funkcja głębi wykorzystywana do określania
sąsiedztwa punktu x w sensie głębi depth1
depth2 - funkcja głębi wykorzystywana do obliczania
głębi lokalnej punktu x
# załadowanie niezbędnych pakietów
require(depthproc)
require(depth)
# przygotowanie danych
x = as.matrix(x)
DATA = as.matrix(DATA)
# określenie wymiaru danych
ncol = ncol(DATA)
nrow = nrow(DATA)
67
Dodatek A. Wykorzystane w pracy kody w języku R
# inicjalizacja wektora z wartościami głębi
# wykorztystywanymi do określania sąsiedztwa
# punktu x w sensie głębi
depths = rep(0,nrow)
# symetryzacja zbioru danych
symDATA = rbind(DATA,
t(apply(DATA, 1, function(k) 2*x-k)))
# wyznaczenie głębi punktów całego zbioru DATA względem
# zbioru DATA poddanemu symetryzacji
depths = apply(DATA, 1, function(y)
depth::depth(y, symDATA, method=depth1))
# określenie minimalnej wartości głębi, która zapewnia
# włączenie obserwacji do docelowego zbioru R
quan = quantile(depths, probs=1-beta)
# określenie najbliższych sąsiadów punktu x w sensie
# głębi depth1 jako docelowego zbioru R poprzez
# pobranie obserwacji z głębią większą lub równą
# obliczonemu kwantylowi rzędu 1-beta
Rset = as.matrix(DATA[ signif(depths,digits=6) >=
signif(quan,digits=6), ])
# obliczenie wartości głębi punktu x względem zbioru R
LD = depthproc::depth(x, Rset, method=depth2, digits=2)
return(LD)
}
# ========================================================
# SYMULACJA I KLASYFIKACJA NIEWYPUKŁYCH ZBIORÓW DANYCH
# ========================================================
# zainicjowanie wektorów, osobnych dla każdej metody
# klasyfikacyjnej, w których zapisywane będą wartości
# błędu klasyfikacji po każdej symulacji
knn_min_eCVs = c()
lda_min_eCVs = c()
ldmah_min_eCVs = c()
ldeuk_min_eCVs = c()
68
Dodatek A. Wykorzystane w pracy kody w języku R
ldproj_min_eCVs = c()
svm_min_eCVs = c()
# zainicjowanie wektorów, osobnych dla każdego klasyfikatora
# opartego na funkcjach głębi, w których zapisywane będą
# wartości beta minimalizujące błąd klasyfikacji
ldmah_beta = c()
ldeuk_beta = c()
ldproj_beta = c()
# liczba symulacji
nsym = 100
for(f in 1:nsym) {
# liczba obserwacji na klasę
n = 100
r1 = 3
omega1 = runif(n,min=0,max=2*pi)
dane1 = cbind(r1*cos(omega1),r1*sin(omega1))
dane1 = apply(as.matrix(dane1), 1,
function(x) x*rnorm(1,1,0.1))
r2 = 2
omega2 = runif(n,min=0,max=2*pi)
dane2 = cbind(r2*cos(omega2),r2*sin(omega2))
dane2 = apply(as.matrix(dane2), 1,
function(x) x*rnorm(1,1,0.1))
r3 = 1
omega3 = runif(n,min=0,max=2*pi)
dane3 = cbind(r3*cos(omega3),r3*sin(omega3))
dane3 = apply(as.matrix(dane3), 1,
function(x) x*runif(1,0,1.5))
DATA = cbind(rbind(t(dane1), t(dane2), t(dane3)),
rep(x=1:3, each=n))
### PRZYGOTOWANIE DANYCH DO OCENY KLASYFIKACJI
### Z WYKORZYSTANIEM METODY 10-FOLD CROSS VALIDATION
69
Dodatek A. Wykorzystane w pracy kody w języku R
# wykorzystanie pakietu cvTools
require(cvTools)
# liczba podzbiorów, na które zostanie podzielony zbiór
nfolds = 10
# obiekt związany z podziałem zbioru obserwacji na $nfolds$
# w przybliżeniu równolicznych części
folds = cvFolds(nrow(DATA), K = nfolds, type = "random")
# zbiór zawierający informację do którego
# podzbioru należy dana obserwacja
indices = cbind(folds$which, folds$subsets)
# porządkowanie zbioru indices po numerach obserwacji
indices = indices[order(indices[,2]), ]
# dołączenie do orginalnego zbioru informacji
# o numerze podzbioru do którego należy
DATA = cbind(DATA, indices[,1])
DATA = data.frame(DATA)
colnames(DATA)[4] = "fold"
list = 1:nfolds
### METODA K-NAJBLIŻSZYCH SĄSIADÓW
# zainicjowanie wektora w którym przechowywane będą
# wartości błędu dla różnej liczby sąsiadów
knn_eCVs = c()
# wektor wartości k sąsiadów
k = c(1:5, seq(10,50,5))
for(j in k){ # dla każdej wartości k sąsiadów
# wektor błędów dla poszczególnych podzbiorów
knn_eTs = c()
for(i in 1:nfolds) { # dla każdego podzbioru
70
Dodatek A. Wykorzystane w pracy kody w języku R
71
trainingset = subset(DATA, fold %in% list[-i])
testset = subset(DATA, fold %in% list[i])
knn_object = knn(train=trainingset[,1:2],
test=testset[,1:2],
cl=trainingset[,3], k=j)
# dodanie do wektora błędu dla podzbioru $i$
knn_eTs = append(knn_eTs,
sum(knn_object!=testset[,3])/nrow(testset))
}
# uśrednianie wyników podzbiorów
knn_eCV = sum(knn_eTs)/nfolds
# zapis błędu CV dla danej liczby sąsiadów
knn_eCVs = append(knn_eCVs, knn_eCV)
}
# liczba sąsiadów k minimalizująca błąd eCV
(kmin = k[which(knn_eCVs==min(knn_eCVs))])
# zapisanie do głównego wektora błędów najniższego rezultatu
knn_min_eCVs = append(knn_min_eCVs, min(knn_eCVs))
### LINIOWA ANALIZA DYSKRYMINACYJNA
# wektor błędów dla poszczególnych podzbiorów
lda_eTs = c()
for(i in 1:nfolds) { # dla każdego podzbioru
# wektor etykiet przewidywanych przez LDA
lda_results = c()
trainingset = subset(DATA, fold %in% list[-i])
testset = subset(DATA, fold %in% list[i])
lda_object = lda(x=trainingset[,1:2],
grouping=trainingset[,3],prior=c(1,1,1)/3)
# predykcja
lda_results = predict(lda_object, testset[,1:2])$class
Dodatek A. Wykorzystane w pracy kody w języku R
72
# zapis błędu dla podzbioru $i$
lda_eTs = append(lda_eTs,
sum(lda_results!=testset[,3])/nrow(testset))
}
# uśrednianie wyników podzbiorów
lda_eCV = sum(lda_eTs)/nfolds
# zapisanie do głównego wektora błędów końcowego rezultatu
lda_min_eCVs = append(lda_min_eCVs, lda_eCV)
### KLASYFIKATOR SVM
# wektor błędów dla poszczególnych podzbiorów
svm_eTs = c()
for(i in 1:nfolds) { # dla każdego podzbioru
# wektor etykiet przewidywanych przez SVM
svm_results = c()
trainingset = subset(DATA, fold %in% list[-i])
testset = subset(DATA, fold %in% list[i])
svm_object = svm(x=trainingset[,1:2],
y=as.factor(trainingset[,3]))
# etykiety jako factor
# predykcja
svm_results = predict(svm_object, testset[,1:2])
# zapis błędu dla podzbioru $i$
svm_eTs = append(svm_eTs,
sum(svm_results!=as.factor(testset[,3]))/nrow(testset))
}
# uśrednianie wyników podzbiorów
svm_eCV = sum(svm_eTs)/nfolds
# zapisanie do głównego wektora błędów końcowego rezulatu
svm_min_eCVs = append(svm_min_eCVs, svm_eCV)
Dodatek A. Wykorzystane w pracy kody w języku R
### KLASYFIKATOR LOKALNEJ/MAXDEPTH GŁĘBI
### MAHALANOBISA/EUKLIDESA/PROJEKCYJNEJ
# przygotowanie parametrów
labels = DATA[,3]
labelset = unique(labels)
nlabel = length(labelset)
# wektor błędów dla poszczególnych poziomów beta
ld_eCVs = c()
# wersja LOCALDEPTH
beta = c(seq(0.01,1,0.01))
# wersja MAXDEPTH
# beta = 1
for(j in beta){ # dla każdego poziomu beta
# wektor błędów dla poszczególnych podzbiorów
ld_eTs = c()
for(i in 1:nfolds) { # dla każdego podzbioru
trainingset = subset(DATA, fold %in% list[-i])
testset = subset(DATA, fold %in% list[i])
# liczba obserwacji w zbiorze testowym
nx = nrow(testset)
# wektor predykcji klasy dla obserwacji testowych
classes = rep(0,nx)
for(s in 1:nx) { # dla każdego testowanego punktu
# wektor
ld_results = rep(0,nlabel)
for(p in 1:nlabel) { # względem zbioru obserwacji
# każdej klasy
# obserwacja poddawana klasyfikacji
x = testset[s,1:2]
# wersja MAHALANOBISA
ld_results[p] = localdepth(x,
73
Dodatek A. Wykorzystane w pracy kody w języku R
#
#
#
#
#
#
#
#
74
rbind(trainingset[trainingset[,3]==labelset[p], 1:2],x),
beta=j, depth1="Liu", depth2="Mahalanobis")
wersja EUKLIDESA
ld_results[p] = localdepth(x,
rbind(trainingset[trainingset[,3]==labelset[p], 1:2],x),
beta=j, depth1="Liu", depth2="Euclidean")
wersja PROJEKCYJNA
ld_results[p] = localdepth(x,
rbind(trainingset[trainingset[,3]==labelset[p], 1:2],x),
beta=j, depth1="Liu", depth2="Projection")
}
# indeks skupiska dla którego osiągnięto
# maksymalną wartość głębi
maxdepth_index = which(ld_results==max(ld_results))
# zapis prognozowanej etykiety
# jeśli wartość głębi taka sama dla>=2 klas
# to wówczas etykieta jest spośród nich losowana
classes[s] = as.character(labelset[
ifelse(length(maxdepth_index)>1 ,
sample(maxdepth_index,1) , maxdepth_index ) ])
}
# zapis błędu dla podzbioru $i$
ld_eTs = append(ld_eTs,
sum(classes!=testset[,3])/nrow(testset))
}
# uśrednianie wyników podzbiorów
ld_eCV = sum(ld_eTs)/nfolds
# zapis błędu CV dla danego poziomu beta
ld_eCVs = append(ld_eCVs, ld_eCV)
}
# zapisanie do głównego wektora błędów najniższego rezulatu
# wersja MAHALANOBISA
ldmah_min_eCVs = append(ldmah_min_eCVs, min(ld_eCVs))
# wersja EUKLIDESA
# ldeuk_min_eCVs = append(ldeuk_min_eCVs, min(ld_eCVs))
# wersja PROJEKCYJNA
# ldproj_min_eCVs = append(ldproj_min_eCVs, min(ld_eCVs))
Dodatek A. Wykorzystane w pracy kody w języku R
75
# zapis poziomu beta minimalizującego bład klasyfikacji
# wersja MAHALANOBISA
ldmah_beta = append(ldmah_beta,
beta[which(ld_eCVs==min(ld_eCVs))])
# wersja EUKLIDESA
# ldeuk_beta = append(ldeuk_beta,
#
beta[which(ld_eCVs==min(ld_eCVs))])
# wersja PROJEKCYJNA
# ldproj_beta = append(ldproj_beta,
#
beta[which(ld_eCVs==min(ld_eCVs))])
cat(f,"/",nsym,"\n")
}
Literatura
[1] Ackoff R.L.: Management Misinformation Systems. Management Science, Vol.
14, No. 4, 1967.
[2] Agostinelli C., Romanazzi M.: Local depth. J. Statist. Plann. Inference, 141, s.
817–830, 2011.
[3] Bocian M., Kosiorowski D., Zawadzki Z., Węgrzynkiewicz A.: Pakiet środowiska
R depthproc, 2012.
URL: https://r-forge.r-project.org/projects/depthproc/.
[4] Breiman L., Spector P.: Submodel selection and evaluation in regression: the
X-random case. International Statistical Review 60: 291–319, 1992.
[5] Dasarathy B.V.: NN concepts and techniques: an introductory survey. [w:] Dasarathy B.V. (red.): Nearest Neighbor Norms: NN Pattern Classification Techniques. IEEE Computer Society Press, 1991.
[6] Devroye L., Györfi L., Lugosi G.: A Probabilistic Theory of Pattern Recognition.
Springer-Verlag, 1996.
[7] Dyckerhoff R.: Data Depths Satisfying the Projection Property. Allgemeines Statistisches Archiv, vol. 88, 2004.
[8] Enas G.G., Chai S.C.: Choice of smoothing parameter and efficiency of the
k-nearest neighbor classification. Computers and Mathematics with Applications, 12, 1986.
[9] Franses P. H., Van Dijk, D.: Non-linear Time Series Models in Empirical Finance. Cambridge: Cambridge University Press, 2000.
76
Literatura
77
[10] Gatnar E.: Symboliczne metody klasyfikacji danych. Wydawnictwo Naukowe
PWN, 1998.
[11] Gatnar E.: Nieparametryczna metoda dyskryminacji i regresji. Wydawnictwo
Naukowe PWN, 2000.
[12] Gatnar E.: Podejście wielomodelowe w zagadnieniach dyskryminacji i regresji.
Wydawnictwo Naukowe PWN, 2008.
[13] Ghosh A. K., Chaudhuri P.: On Maximum Depth and Related Classifiers. Scand.
J. Statist., 32, s. 327–350, 2005.
[14] Hardy A., Rasson J.P.: Une nouvelle approche des problemes de classification
automatique. Statistique et analyse des donnees, vol. 7, 1982.
[15] Hastie T., Tibshirani R., Friedman J.: The Elements of Statistical Learning:
Data Mining, Inference, and Prediction. Springer, 2009.
[16] Hastie T., Tibshirani R., Friedman J., Halvorsen K.: Pakiet środowiska R ElemStatLearn, 2012.
URL: http://cran.r-project.org/web/packages/ElemStatLearn/.
[17] Koshevoy G.A., Mosler K.: Zonoid Trimming for Multivariate Distributions.
The Annals of Statistics, vol. 25, 1997.
[18] Kosiorowski D.: Wstęp do wielowymiarowej analizy statystycznej zjawisk ekonomicznych. Wydawnictwo Uniwersytetu Ekonomicznego w Krakowie, 2008.
[19] Kosiorowski D.: Statystyczne funkcje głębi w odpornej analizie ekonomicznej.
Wydawnictwo Uniwersytetu Ekonomicznego w Krakowie, 2012.
[20] Kosiorowski D., Bocian M.: Odporna estymacja funkcji gęstości dla danych panelowych w analizie strumienia danych ekonomicznych o wielu reżimach. Niepublikowany, 2013.
[21] Lange T., Mosler K., Mozharovskyi P.: Fast Nonparametric Classification Based
on Data Depth. Springer-Verlag, 2012.
[22] Li J., Cuesta-Albertos J., Liu R.Y.: DD-Classifier: Nonparametric Classification
Procedures Based on DD-Plots. J. Amer. Statist. Assoc., vol. 107, s. 737–753,
2012.
[23] Liu R.Y.: On a Notion of Data Depth Based on Random Simplices. The Annals
of Statistics, vol. 18, s. 405–414, 1990.
Literatura
78
[24] Liu R.Y., Parelius J. M., Singh K.: Multivariate analysis by data depth: descriptive statistics, graphics and inference (with discussion). The Annals of Statistics,
vol. 27, s. 783–858, 1999.
[25] López-Pintado S., Romo J.: On The Concept of Depth for Functional Data.
Journal of the American Statistical Association 104: 718–734, 2009.
[26] Marzec J.: Bayesowskie Modele Zmiennych Jakościowych i Ograniczonych w
Badaniach Niespłacalności Kredytów. Wydawnictwo Uniwersytetu Ekonomicznego w Krakowie, 2008.
[27] Paindaveine D., Van Bever G.: Nonparametrically Consistent Depth-Based
Classifiers. Niepublikowany, 2012a.
[28] Paindaveine D., Van Bever G.: From Depth to Local Depth: A Focus on Centrality. Working Papers ECARES 2012-047, Universite Libre de Bruxelles, 2012b.
[29] Ramsay J.O., Wickham H., Graves S., Hooker G.: Pakiet środowiska R fda,
2012.
URL: http://cran.r-project.org/web/packages/fda/.
[30] Rayward W.B.: Some Schemes for Restructuring and Mobilising Information
in Documents: A Historical Perspective. Information Processing & Management
Vol. 30, No. 2, s. 163-175, 1994.
[31] Serfling R.J.: Multivariate Symmetry and Asymmetry. [w:] Encyclopedia of Statistical Science. S. Kotz, C.B. Read, N. Balakrishnan, B. Vidakovic (eds), 2nd
ed., John Wiley, 2006.
[32] Sun Y., Genton M. G.: Adjusted Functional Boxplots for Spatio-Temporal Data
Visualization and Outlier Detection. Envirometrics, (wileyonlinelibrary.com)
DOI: 10.1002/env.1136, 2011.
[33] Tukey J.: Mathematics and Picturing Data. [w:] Proceedings of the 1974 International Congress of Mathematicians., 2, R.James (ed.), Canadian Math. Congress, 1975.
[34] Welch B.L.: Note on discriminant functions. Biometrika, t. 31, 1939.
[35] Zuo Y., Serfling R.: General Notions of Statistical Depth Function. The Annals
of Statistics, vol. 28, s. 461-482, 2000.
Literatura
79
[36] Zuo Y.: Projection Based Depth Functions and Associated Medians. The Annals
of Statistics, vol. 31, 2003.
[37] Zuo Y., Lai S.: Exact Computation of the Bivariate Projection Depth and
Stahel-Donoho Estimator. Computational Statistics and Data Analysis, vol. 55,
nr 3, 2011.
Spis rysunków
1.1
Przykład klasyfikacji z wykorzystaniem metody 5-NN. . . . . . . . . . .
12
1.2
Przykład diagramu Voronoi’a dla zbioru IRIS w przestrzeni X2 . . . . .
13
1.3
Zależność błędu klasyfikacji ê CV od liczby najbliższych sąsiadów k dla
zbioru IRIS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.4
Przykład wzrostu długości boku b hiperkostki, zawierającej frakcję
p = 0.1 obserwacji, podczas zwiększania wymiaru zagadnienia L.
1.5
2.1
. . .
16
stosowania metody 5-fold cross validation. . . . . . . . . . . . . . . . . .
20
Przykład podziału zbioru U na 5 równolicznych części podczas
Wykres konturowy dla głębi Euklidesa z próby w przypadku danych
pochodzących z dwuwymiarowego rozkładu normalnego. . . . . . . . . .
2.2
14
26
Wykres konturowy dla głębi projekcyjnej z próby w przypadku
danych pochodzących z mieszanki dwóch dwuwymiarowych rozkładów
normalnych. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.3
27
Wykres konturowy dla głębi projekcyjnej z próby w przypadku zbioru
zawierającego obserwacje generowane z dwuwymiarowego rozkładu
normalnego oraz 10% obserwacji odstających. . . . . . . . . . . . . . . .
2.4
28
Wykres konturowy i perspektywiczny dla głębi projekcyjnej z próby w
przypadku danych pochodzących z mieszanki trzech dwuwymiarowych
rozkładów normalnych. . . . . . . . . . . . . . . . . . . . . . . . . . . .
29
2.5
Przykład symetryzacji zbioru danych. . . . . . . . . . . . . . . . . . . .
32
2.6
Przykład symetryzacji zbioru danych. . . . . . . . . . . . . . . . . . . .
33
80
Spis rysunków
81
2.7
Wykres konturowy dla głębi lokalnej Paindaveine i Van Bever. . . . . .
34
2.8
Wykres konturowy dla głębi lokalnej Paindaveine i Van Bever w
przypadku mieszanki rozkładów normalnych. . . . . . . . . . . . . . . .
36
Wykres konturowy dla głębi lokalnej Paindaveine i Van Bever. . . . . .
37
2.10 Przykład zbioru obserwacji funkcjonalnych. . . . . . . . . . . . . . . . .
38
2.11 Przykład funkcjonalnego wykresu ramka-wąsy. . . . . . . . . . . . . . .
39
2.12 Oszacowania gęstości fˆi oraz gęstości ĝi . . . . . . . . . . . . . . . . . . .
45
2.13 Funkcjonalne wykresy ramka-wąsy dla poszczególnych skupisk. . . . . .
47
2.9
2.14 Oszacowania gęstości rozkładów przychodów gospodarstw domowych w
podziale na województwa. . . . . . . . . . . . . . . . . . . . . . . . . . .
48
3.1
Wykresy rozrzutu dla zmiennych ze zbioru IRIS. . . . . . . . . . . . . .
50
3.2
Klasyfikowany podzbiór zbioru IRIS. . . . . . . . . . . . . . . . . . . . .
51
3.3
Wyniki klasyfikacji dla podzbioru zbioru IRIS. . . . . . . . . . . . . . .
52
3.4
Klasyfikowany podzbiór zbioru Boston. . . . . . . . . . . . . . . . . . .
55
3.5
Wyniki klasyfikacji dla podzbioru zbioru Boston. . . . . . . . . . . . . .
56
3.6
Klasyfikowany zbiór pochodzący z badania Current Population Survey.
59
3.7
Wyniki klasyfikacji zbioru pochodzącego z badania Current Population
Survey. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
60
3.8
Przykład symulowanego zbioru danych o podzbiorach niewypukłych. . .
62
3.9
Wyniki klasyfikacji dla niewypukłych zbiorów danych. . . . . . . . . . .
63
Spis tabel
1.1
Tabela wyników klasyfikacji obserwacji ze zbioru testowego T. . . . . .
17
2.1
Specyfikacja Wi w rozważanym modelu. . . . . . . . . . . . . . . . . . .
46
2.2
Specyfikacja oi w rozważanym modelu. . . . . . . . . . . . . . . . . . .
46
82