Spis treści
1.
2.
3.
4.
5.
6.
7.
8.
9.
Streszczenie
Summary In English Language
Wstęp
Zalety e-commerce
Technologie i narzędzia projektowe
3.1. Język skryptowy PHP
3.2. Szablony Smarty
3.2.1. System szablonów Smarty
3.2.2. Przykład użycia
3.2.3. Inne rozwiązania
3.3. PEAR
3.3.1. Moduł PEAR DB
3.4. Baza danych MySQL
3.4.1. Niektóre z zalet MySQL
Projektowanie aplikacji
4.1. Uwzględnienie możliwości rozbudowy witryny
4.2. Architektura trójwarstwowa
Wykorzystanie i opis aplikacji
5.1. Katalog produktów
5.2. Wyszukiwanie produktów w katalogu
5.3. Zarządzanie katalogiem
5.4. Koszyk na zakupy
5.5. Obsługa zamówień
5.6. Rekomendowanie produktów
5.7. Dane klientów
5.8. Oceny i recenzje produktów
Bezpieczeństwo technologii e-commerce
6.1. Rozwiązania zwiększające bezpieczeństwo zastosowane w aplikacji
6.2. Serwer internetowy Apache
Zaistnienie w internecie
7.1. Wyszukiwarki
7.2. Pozycjonowanie
Zakończenie
Bibliografia
1
3. Technologie i narzędzia projektowe
3.1 Język skryptowy PHP
Język PHP jest językiem wysokiego poziomu, czyli jego polecenia nie przekładają się
bezpośrednio na rozkazy procesora taj jak dzieje się to w przypadku różnych odmian
asemblera. Jest interpreterem zgodnym z ideą open source. Jest przeznaczony do tworzenie
dynamicznych, interaktywnych stron WWW. Na oficjalnej stronie projektu PHP (pod
adresem http://www.php.net (1)), twórcy umieścili następującą definicje: „PHP jest często
stosowanym językiem skryptowym ogólnego przeznaczenia, który został zaprojektowany
specjalnie dla aplikacji WWW i którego kod może być osadzany w dokumentach HTML”.
Nazwa języka stanowi skrót od słów Personal Home Page, lecz zgodnie z konwencją
nazewnictwa obowiązującą dla produktów GNU (Gnu to skrót od słów Gnu’s Not Unix – Gnu
to nie Unix – projekt bezpłatnego systemu operacyjnego , zgodnego funkcjonalnie z
systemem Unix), skrót ten jest obecnie rozwijany jako PHP Hypertext Preprocessor.
Język PHP został stworzony w 1994 roku, jego twórcą jest jeden człowiek, Rasmus Lerdorf.
Od tego czasu PHP uległo czterem poważnym modyfikacjom, których wynikiem jest obecny,
dojrzały produkt o szerokim zastosowaniu. W kwietniu 2007 roku PHP był wykorzystywany w
około 20 milionach domen.
Rysunek 1. Wykres przedstawiający użycie PHP w domenach od kwietnia 2000 do kwietnia 2007 roku. (
Wykres pobrany ze strony http://www.php.net (1), źródło danych: http://news.netcraft.com (2)
2
Wśród przyczyn sukcesu tak szerokiego stosowania jeżyka PHP wymienia się:
Interpreter PHP jest dostępny za darmo (idea open surce) – przy użyciu razem z
serwerami przeznaczonymi dla systemów Linux język PHP stanowi bardzo
ekonomiczną platformę dla dynamicznych dokumentów WWW.
Społeczność zgromadzona wokół projektu PHP działa bardzo efektywnie, co owocuje
częstym dodawaniem nowych elementów języka oraz dostępnością wielu
użytecznych bibliotek oraz częstym uaktualnianiem wcześniejszych bibliotek (np.
Smarty i PEAR).
Interpreter PHP charakteryzuje się uniwersalnością wykorzystywanych platform.
Pracuje z różnymi serwerami WWW i w różnych systemach operacyjnych (na
platformach unikowych, w systemie Windows i Mac OS).
To jeden z młodszych języków skryptowych stworzony do zastosowań związanych z WWW.
Jego interpreter może być skonfigurowany jako CGI (ang. Common Gateway Interface) i
umożliwiać pisanie skryptów uruchamianych z linii poleceń lub być modułem serwera.
Składnia języka PHP zawiera w sobie najlepsze cechy języka C (m.in. zwięzłą składnię) oraz
Perla (wyrażenia regularne, możliwość stosowania zewnętrznych modułów, parsowanie
kodu ze zmiennych tekstowych). Dodatkowo część funkcji ma takie same nazwy jak w języku
C. Język PHP może być "przeplatany" w kodzie strony z czystym językiem HTML.
Użytkowników C++ ucieszy to, że w PHP można stosować obiekty.
PHP nie jest jednak jedynym językiem skryptowym działającym po stronie serwera. Innymi
popularnymi rozwiązaniami tego typu są: JSP (Java Server Pages), Perl, ColdFusion czy
ASP.NET. Istnieje wiele różnic pomiędzy wymienionymi powyżej rozwiązaniami, jednak
można wymienić co najmniej jedną ich wspólną cechę. Dokumenty powstałe przy ich
wykorzystaniu złożone są ze standardowego kodu HTML, tworzącego statyczną część strony
oraz z kodu generującego część dynamiczną.
3.2 Szablony Smarty
Rozdział ten został opary na materiałach pochodzących z ksiązki „Smarty – Szablony w
aplikacjach PHP” (3), oraz artykułu z CHIP-a nr 05/2005 (4)
Smarty jest on napisaną w języku PHP klasą, za pomocą której będziemy w stanie połączyć
tworzone oddzielnie kod źródłowy sterujący witryną WWW oraz opracowane w HTML-u
szablony stron. Nie jest konieczny, ale bardzo przydatny w profesjonalnych projektach.
3
Już od ponad dwunastu lat język PHP jest z dużym powodzeniem używany przez
programistów aplikacji WWW o otwartym kodzie, jest jedną z najlepszych technologii
tworzenia witryn w Internecie. Jednak wraz z wzrostem złożoności powstających aplikacji
pojawił się nowy problem. Jak oddzielić warstwę logiczną (biznesową) od warstwy
prezentacji (dokładniej warstwową strukturą aplikacji zajmę się w rozdziale 4), czyli jak
oddzielić kod pisany przez programistów PHP od kodu tworzonego przez projektantów
aplikacji, czyli od kodu HTML.
Technologia Smarty – system szablonów dla języka PHP – opracowano aby rozwiązać ten
problem.
Oddzielenie obu tych warstw jest konieczne. W przypadku złożonych aplikacji pozwala to na
zarządzanie kodem aplikacji, co byłoby bardzo kłopotliwe (lub nawet niemożliwe), gdyby kod
PHP był wymieszany z kodem PHP.
Smarty - podział pracy przy projekcie
Projektanci są odpowiedzialni za stworzenie wizerunku witryny WWW. Tworzą szablony
przedstawiające w jaki sposób będzie prezentowana treść na stronie. Wprowadzają
ilustracje, style tekstu, tabelki itp. Jednym słowem są odpowiedzialni za wizualizacje treści
która ma zostać przekazana odbiorcy.
Zadaniem programistów jest zaś, tworzenie kodu odpowiedzialnego za przetwarzanie w
ściśle określony sposób treści do przekazania. Nie interesuje ich jak strona ma wyglądać
(kształty, kolory, czcionki, ilustracje) lub jaki jest układ treści na stronie. Ich główną rolą jest
przekazanie treści przez wcześniej uzgodnione zmienne.
Według autorów książki „Smarty – Szablony w aplikacjach PHP” (3) podział zadań pomiędzy
programistą a projektantem witryny WWW jest następujący:
Zadanie programisty:
Odczytać dane z bazy danych za pomocą prostego zapytania.
Sprawdzić poprawność danych i przetworzyć je, stosując reguły biznesowe.
Jeśli jest taka potrzeba, zmodyfikować metody dostępu do danych oraz
implementację reguł biznesowych bez ingerencji w pracę projektanta. Na przykład
migracja z systemu bazy danych MySQL do PostgresSQL nie powinna wymagać od
projektanta żadnych zmian.
Zadania projektanta:
4
Utworzyć projekt HTML, który nie będzie miał wpływu na kod PHP tworzony przez
programistę . Jedynym zadaniem projektanta jest rozmieszczenie elementów danych
w miejscach uzgodnionych z programistą.
Wprowadzać zmiany w projekcie bez konieczności konsultacji z programistą i
niewymagające od niego wprowadzania zmian.
Przestać się martwić o techniczne modyfikacje w witrynie, które burzą sposób w jaki
jest ona prezentowana użytkownikom.
Zadania przydzielone osobom biorącym udział w projekcie dotyczą części, nad która te osoby
pracują – prezentacji, reguł biznesowych i dostępu do danych.
3.2.1. System szablonów Smarty
Szablon interfejsu Smarty (plik .tpl zawierający elementy HTML oraz znaczniki i kod właściwy
dla rozwiązań Smarty) i moduł dodatku Smarty (plik .php zawierający kod dla szablonu)
składają się na komponentowy szablon Smarty (ang. Smarty Componentized Templates).
Na rysunku 2. została przedstawiona zależność między plikiem szablonu interfejsu (Smarty
Design Template) i plikiem modułu dodatku Smarty.
5
Rysunek 2. Komponentowy szablon Smarty (Rysunek oparty na rysunku 2.4 ksiązki „PHP i MySQL
zastosowania e-commerce” (5) )
Jak piszą sami autorzy projektu Smarty w swoim serwisie (http://smarty.php.net (6)) Smarty
nie jest zwykłym systemem szablonów, ponieważ oprócz standardowej interpretacji
znaczników ma następujące możliwości:
Kompilacja
Szablony interfejsu Smarty (pliki .tpl) są plikami tekstowymi. Aby wyświetlić szablon
na ekranie monitora wszystkie systemy szablonów używają wyrażeń regularnych.
Część statyczna powstaje na podstawie określonych znaczników, podczas
przetwarzania przez szablon całego dokumentu.
Jest to proces bardzo czasochłonny, dlatego też podczas pierwszego przetwarzania
Smarty kompiluje szablon do zwykłego kodu PHP (umieszcza go w katalogi
templates_c). Następnym razem gdy Smarty otrzyma żądanie przetworzenia
szablonów, wykonuje od razu skrypt z katalogu templates_c.
Szablon może zostać powtórnie skompilowany, jest to zależne od ustawień
konfiguracyjnych, jeśli otrzyma takie żądanie z poziomu skryptu PHP korzystającego
ze Smarty lub gdy szablon oryginalny (plik .tpl) ulegnie zmianie.
6
Zastosowanie mechanizmu kompilacji pozwala oszczędzić czas niezbędny do
przetworzenia znaczników szablonu wyrażeniami regularnymi.
Cache – pamięć podręczna (ang. Caching)
Smarty dostarcza szczegółowych funkcji pamięci podręcznej (cache) dla cacheowania całej lub części wyświetlanej strony, lub pozostawienia jej części nie zapisanej
w części podręcznej. Programista może zarejestrować funkcje szablonu jako do
zapisania w cache-u albo jako niezapisywalne w cache-u. Może grupować zapisane
szablony w logiczne części dla łatwiejszego zarządzania.
Pliki konfiguracyjne (ang. Configuration Files)
Smarty może przypisywać zmienne zapisywane w plikach konfiguracyjnych.
Projektant szablonów może zarządzać wartościami wspólnymi dla kilku szablonów w
jednym miejscu, bez interwencji programisty, oraz zmienne konfiguracyjne mogą być
łatwo współdzielone między częścią programistyczną a częścią prezentacji aplikacji.
Bezpieczeństwo (ang. Security)
Szblony nie zawierają kodu PHP. Dlatego, projektant szablonu nie posiada pełnych
możliwości kodu PHP, ale tylko podzbiór funkcjonalności udostępnionych przez
programiste (aplikacje) dla niego.
Łatwe do użycia i zarządzania (ang. Easy to Use and Maintain)
Projektanci stron nie używają składni PHP, lecz łatwej do użycia składni niewiele
różniącej się od prostego HTML-a. Szablony są bardzo bliskie reprezentowania
finałowego wyglądu strony, radykalnie skracając cykl pracy programisty.
Modyfikatory zmiennych (ang. Variable Modifiers)
Zawartość przypisana do zmiennych może być łatwo dopasowana w czasie
wyświetlania przez modyfikatory, takie jak wyświetlanie wszystkich dużych liter,
formatowanie dat, skracanie bloków tekstu, dodawanie odstępów między znakami,
etc. Ponownie, jest to możliwe bez interwencji ze strony programisty
Lista modyfikatorów jest Smarty jest dość długa, a dodatkowo możemy utworzyć
własne.
Funkcje szablonów (ang. Template Functions)
Jest dostępnych wiele funkcji dla projektantów szablonów, dzięki którym szybko
możemy generować dynamiczna część kodu HTML (np. listy rozwijane, tabele, okna
pop-up, etc.). Możliwe jest wyświetlanie wewnątrz tworzonych szablonów innych
wcześniej przygotowanych szablonów, wykonywanie zadań pętli na zawartości tablic,
7
formatowanie tekstu do postaci e-mail, etc. Możemy również sami tworzyć własne
funkcje szablonów.
Filtry (ang. Filters)
Programista posiada kompletną kontrole nad wyjściową postacią szablonu i
skompilowana zawartością szablonu przez przed-filtry (ang. pre-filters) po-filtry (ang.
post-filters) i filtry wyjściowe (ang. output-filters).
Moduły rozszerzające (ang. Plugins)
Niemal każda funkcjonalność systemu szablonów Smarty jest realizowana przez zbiór
modułów rozszerzających. Są one proste w użyciu, wystarczy umieścić je w katalogu
rozszerzeń a następnie wzmiankując o nich w szablonie używać je jako kod aplikacji.
Jest możliwe pobranie wielu gotowych rozszerzeń ze strony projektu Smarty
(http://smarty.php.net)
W omawianej pracy wszystkie moduły rozszerzające stworzone na potrzeby aplikacji
umieściliśmy w katalogu smarty_plugins.
Testowanie (ang. Debugging)
Smarty posiada wbudowany system testowania, dzięki któremu możemy
kontrolować wartość zmiennych w przetwarzanych szablonach oraz szybkość
wyświetlania poszczególnych szablonów
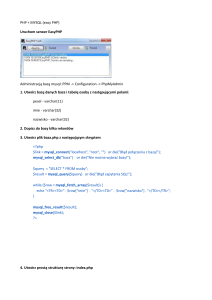
3.2.2. Przykład użycia
Samo działanie systemu Smarty zilustruje prostym przykładem przedstawionym poniżej. W
dowolnym edytorze tworzymy plik o nazwie index.tpl i zapisujemy go w katalogu
templates/. Plik ten jest w zasadzie zwykłym szkieletem strony XHTML-owej, z tą jednak
różnicą, że w miejscach, w których w statycznym kodzie znajdują się konkretne dane, tutaj
występują zmienne (linia 5 oraz 9).
Zadaniem Smarty jest przypisanie tym zmiennym właściwych wartości na podstawie
działania aplikacji. Dlatego potrzebny jest program, który tego dokona.
Tworzymy zatem plik index.php. W linii nr 2 wykonujemy polecenie require, którym
zaimplementujemy kod klasy Smarty.class.php. Należy pamiętać o właściwym podaniu
ścieżki do tego pliku (w naszym wypadku jest to katalog Smarty/). W kolejnym wierszu
tworzymy nowy obiekt klasy Smarty. Będziemy się do niego odwoływali za pomocą zmiennej
$smarty. W liniach od 6 do 9 polom nowo utworzonego obiektu (konkretnie zmiennym
8
wskazującym na cztery katalogi1 wykorzystywane przez Smarty) przypisujemy właściwe
ścieżki dostępu. Kolejny krok jest istotą działania Smarty. Zmiennym, które zdefiniowaliśmy i
umieściliśmy w szablonie index.tpl, przypisujemy konkretne wartości. Do tego celu używamy
wbudowanej w Smarty funkcji assign. Ostatnie polecenie (funkcja display) wyświetla zaś
wypełniony w ten sposób szablon jako plik HTML-owy w przeglądarce.
index.tpl
1. <?xml version="1.0" encoding="iso-8859-2"?>
2. <!DOCTYPE html PUBLIC "-//W3C// DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/ DTD/xhtml1-transitional.dtd">
3. <html xmlns="http://www.w3.org/ 1999/xhtml">
4. <head>
5. <title>{$nazwaStrony|capitalize} </title>
6. </head>
7. <body style="padding:100px;"> 8. <hr />
9. <h1 align="center">{$trescStrony |cat:"Smarty nie jest trudny!"}
</h1>
10. <hr />
11. </body>
12. </html>
index.php
1 <?php
2 require(‘Smarty/Smarty.class. php');
3 $smarty = new Smarty();
4 $smarty->template_dir = ‘templates';
7 $smarty->compile_dir = ‘templates_c';
8 $smarty->cache_dir = ‘cache';
9 $smarty->config_dir = ‘configs';
10 $smarty->assign(‘nazwaStrony', ‘::: Moje linkowisko :::');
12 $smarty->assign(‘trescStrony', ‘Witaj Swiecie! Jestem
stworzona za pomoca systemu szablonow Smarty!');
14 $smarty->display(‘index.tpl');
15 ?>
strona
Przykład przedstawiony powyżej jest bardzo prostym przykładem i przedstawia główną
zasadę działania szablonów Smarty. O wiele bardziej złożone przypadki użycia omówimy w
części analizującej główną aplikacje pracy magisterskiej.
3.2.3. Inne rozwiązania
Spośród wielu innych mechanizmów obsługi szablonów dla języka PHP warto wymienić
następujące:
1
templates/ : szablony w postaci plików TPL, templates_c/ : skompilowane wersje szablonów
(szablony kompilują się tylko raz), cache/ : rezultat wyświetlenia skompilowanych szablonów (oszczędza czas
na ich uruchomienie), configs/ : pliki konfiguracyjne
9
PHP Savant (http://phpsavant.com/yawiki/)
PHPlib (http://phplib.sourceforge.net/)
Yats (http://yats.sourceforge.net/)
FastTemplate (http://www.thewebmasters.net/php/FastTemplate.phtml)
SimpleTemplate (http://simplet.sourceforge.net/)
Yapter (http://yapter.sourceforge.net/)
patTemplate (http://trac.php-tools.net/patTemplate)
Easytemplate (www.onlinetools.org/tools/easytemplate)
TemplatePower (templatepower.codocad.com)
Większość z wymienionych powyżej systemów obsługi szablonów dla PHP, posiada
zasadniczą przewagę nad szablonami Smarty związaną z szybkością działania oraz łatwością
obsługi. Przyczyną tej przewagi jest to, iż technologia Smarty jest o wiele bardziej złożona.
Dzięki temu ma o wiele więcej do zaoferowania, a przy właściwej konfiguracji oferuje
również przyzwoitą szybkość działania.
Zdaniem autorów ksiązki „Smarty – szablony w aplikacjach PHP” (3) prawdziwą konkurencję
dla Smarty jest jedynie PHP Savant. Jest on łatwiejszy w użyciu niż Smarty, a jednocześnie
oferuje wiele funkcjonalności technologii Smarty.
Autorzy wymienionej wyżej pozycji argumentują słuszność postawionej tezy tym, iż szablony
PHP Savant są napisane w PHP a nie w innym języku jak w przypadku Smarty. Co może być
jednocześnie uznane zarówno za zaletę jak i wadę.
Jako zaletę można uznać to, iż programiści nie muszą uczyć się nowego języka, gdyż
PHP Savant jest napisane w języku PHP, co może skrócić początkowy czas wdrożenia
szablonów w pracy przy tworzeniu aplikacji internetowych.
Jednak wielką zaletą dla Smarty a przez to i wadą dla systemu Savant jest kwestia
bezpieczeństwa. Szablony Smarty są kompilowane do kodu PHP, a szablony Savant
od razu są pisane w plikach PHP. Tak więc używając szablonów Savant, dajemy pełny
dostęp projektantowi do możliwości PHP.
Savant jest łatwiejszy w obsłudze, lecz jest niemal pozbawiony mechanizmów
bezpieczeństwa, zaś inne technologie obsługo szablonów maja tylko niewielką liczbę
funkcjonalności oferowanych przez Smarty.
Tak więc można się zgodzić z tezą autorów wyżej wymienionej pozycji, iż szablony
Smarty są obecnie najlepszą technologią do obsługi szablonów w języku PHP. Co
10
potwierdza trafność wyboru wybranej technologii do zarządzania systemem szablonów
w tworzonej aplikacji.
3.3. PEAR
W rozdziale tym zostały wykorzystane materiały z ksiązki „Tworzenie sklepów internetowych
PHP i MySQL” (11)
Początki projektu PEAR sięgają 1999 roku, wtedy to Stig S. Bakken wraz z grupą
programistów rozpoczęli prace nad Repozytorium Rozszerzeń i Aplikacji PHP (ang. PHP
Extension and Application Repository). Jest on hierarchiczną biblioteką zgodną z ideą open
source udostępnioną użytkownikom języka PHP. PEAR został podzielony na pakiety (ang.
packages) które stanowią oddzielne projekty, opracowywane i rozwijane przez oddzielne
grupy programistów. Każdy pakiet jest rozpowszechniany w postaci skompresowanego pliku
w którym oprócz kodu źródłowego znajduje się jego krótki opis.
Twórcom projektu PEAR przyświecały następujące cele:
Udostępnienie programistom PHP biblioteki ze skryptami napisanymi w PHP o prostej
i zorganizowanej strukturze.
Dostarczenie systemu ułatwiającego zarządzanie pakietami ze skryptami PHP i
rozpowszechnianie ich.
Stworzenie standardu stylu pisania skryptów w PHP.
Wyodrębnienie PFC (PHP Foundation Classes) które miałoby zajmować się dobrze
napisanym, przetestowanym oraz udokumentowanym kodem wewnątrz PEAR-a.
Wspomaganie całej społeczności pracującej nad projektem PEAR poprzez utworzenie
strony WWW i listy mailingowej oraz uruchomienie zespołu serwerów tegoż że
projektu.
3.3.1. Moduł PEAR DB
Moduł PEAR DB jest jednym z pakietów PEAR. Odpowiada on abstrakcyjnej warstwie
bazodanowej, wchodzącej w skład pakietu PEAR. Zawiera użyteczne i niezwykle elastyczne
mechanizmy komunikacji z serwerami baz danych.
11
Najważniejszą częścią tego pakietu jest klasa DB, która zawiera zestaw funkcji, który
umożliwia między innymi połączenie się z bazą danych, przesłanie do niej zapytania SQL oraz
pobranie wyników zapytania. Największą zaletą tej klasy jest to, że programista określa tylko
parametry połączenia z bazą danych, a klasa decyduje sama w jaki sposób połączyć się z bazą
danych, przesłać zapytanie a następnie odebrać wyniki tegoż zapytania.
Ilość serwerów baz danych z którymi pakiet PEAR DB może się komunikować jest duża.
Zaliczają się do niej między innymi MySQL, PostgreSQL oraz Oracle. Pełną listę serwerów baz
danych obsługiwanych przez PEAR DB przedstawia Tabela 1.
Tabela 1. Serwery baz danych obsługiwane przez pakiet DB
Typ bazy danych
(zgodny z parametrem phptype ciągu DSN)
dbase
Nazwa bazy danych
fbsql
FrontBase
ibase
InterBase
ifx
Informix
msql
Mini SQL
mssql
Microsoft SQL Server
mysql
MySQL <=4.0
mysqli
MySQL >=4.1 (wymaga PHP 5, od wersji DB
1.6.3)
oci8
Oracle 7/8/9
odbc
ODBC (Open Database Connectivity)
pgsql
PostgreSQL
sqlite
SQLite
sybase
Sybase
dBase
Programista po zapoznaniu się z interfejsem dostępu do bazy danych PEAR DB, może
stosować takie same techniki programowania w różnych projektach, bazując na różnych
serwerach SQL.
12
Poniższe fragmenty kodu PHP przedstawiają różnice pomiędzy komunikacją z bazą danych za
pomocą standardowych funkcji PHP i funkcji PEAR DB.
Dostęp do bazy danych MySQL przy wykorzystaniu standardowych funkcji PHP:
/* Zestawienie połączenia z serwerem MySQL */
$link
=
mysql_connect("mysql_host",
"mysql_uzytkownik",
"mysql_haslo")
or
die("Nie
można
zestawić
połączenia:
".
mysql_error());
/* Wybór bazy danych */
mysql_select_db("moja_baza_danych") or die("Nie można wybrać bazy
danych");
/* Wykonanie zapytania SQL */
$query = "SELECT * FROM produkt";
$result
=
mysql_query($query)
or
die("Zapytanie
zakończone
niepowodzeniem: ". mysql_error());
/* Zakończenie połączenia */
mysql_close($link);
Ta sama operacja wykonana za pomocą kodu PEAR DB:
/* Dołączenie biblioteki PEAR DB */
require_once 'DB.php';
/* Nazwa źródła danych (DSN – Data Source Name) */
$dsn = "mysql://użytkownik:haslo@host/nazwa_bazy_danych";
/* Połączenie z bazą danych */
$db = DB::connect($dsn);
/* Sprawdzenie poprawności połączenia */
if (DB::isError($db)) die ($db->getMessage());
/* Wykonanie zapytania SQL */
$sql = "SELECT * FROM produkt";
$result = $db->query($sql);
/* Sprawdzenie czy zapytanie SQL zostało wykonane poprawnie */
If (DB::isError($result)) die ($result->getMessage());
/* Zakończenie połączenia */
$db->disconnect();
Używając modułu PEAR DB nie trzeba zmieniać kodu skryptu odpowiedzialnego za dostęp do
bazy danych w przypadku zmiany serwera (np. z MySQL na PostgreSQL). Pierwszy z
przedstawionych skryptów wymagałby całkowitej modyfikacji, między innymi należałoby
zamiast instrukcji mysql_connect i mysql_query użyć instrukcji pq_connect i pq_query itp.)
Dodatkowo niektóre funkcje charakterystyczne dla PostgreSQL-a wymagają zdefiniowania
innych parametrów niż w odpowiadających im funkcją MySQL.
13
Dzięki wykorzystaniu interfejsów dostępu do bazy danych ( takich jak PEAR DB), przy zmianie
systemu bazy danych, najczęściej trzeba modyfikować jedynie kod odpowiedzialny za
ustalanie połączenia. W praktyce często trzeba zmieniać składnie zapytań samego SQL-a jeśli
baza danych obsługuje inną wersję języka SQL.
3.4 Baza danych MySQL
Rozdział ten został oparty na materiałach pochodzących z książek „PHP i MySQL Tworze
stron WWW Vademecum profesjonalisty” (7), „Php5 Apache MySQL - Od podstaw” (8) oraz
?????????? (9)
MySQL jest jest bardzo szybkim , solidnym systemem zarządzania relacyjnymi bazami danych
(RDBMS – relational database management system). Jest aplikacją typu open source
umożliwiają PHP dostęp do danych. Można ją pobrać ze strony projektu
http://www.mysql.com/. MySQL został oficjalnie opublikowany w 1996 roku, lecz jego
historia sięga 1979 roku.
Bazy danych pozwalają na efektywne przechowywanie, wyszukiwanie, sortowanie oraz
pozyskiwanie danych. Serwer MySQL steruje dostępem do danych , udostępniając je
jednocześnie dla wielu użytkowników oraz zapewniając możliwość jak najszybszego z nich
korzystania. Operować na danych mogą jedynie osoby do tego uprawnione, weryfikacja
uprawnień następuje poprzez wbudowany system uwierzytelniania użytkowników.
Wszystkie wyżej wymienione cechy baz danych MySQL pozwalają nam określić omawiany
serwer MySQL wieloużytkownikowym oraz wielowątkowy.
Dostęp do bazy danych jest realizowany poprzez (będącym światowym standardem) język
SQL (Structured Query Language). Nie wszystkie elementy tego języka zostały
zaimplementowane w MySQL-u. Spowodowane jest to tym, iż twórcy języka MySQL
postawili sobie za cel stworzenie bardzo szybkiego serwera bazy danych. Każda kolejna
wersja serwera MySQL obsługuje coraz więcej elementów standardowego języka MySQL.
Jednak dostępne funkcjonalności już teraz w większości przypadków zupełnie wystarczają.
MySQL nie jest jedynym systemem RDBMS z jakimi współdziała język PHP. Przykładami
współpracujących z MySQL-em systemami baz danych są: PostgreSQL, Oracle, Microsoft SQL
Server i inne. Jednak ankieta przeprowadzona na stronach serwisu Zend
(http://www.zend.com/zend/php_survey_results.php (10)) jednoznacznie określa jako
najbardziej popularny system baz danych współpracujący z językiem PHP, system bazy
danych MySQL (Rysunek 4.).
14
System zarządzania relacyjną bazą danych jest skomplikowanym oprogramowaniem,
przeznaczonym do przechowywania danych, zarządzania danymi i możliwie szybkiego ich
udostępniania. W opisywanej aplikacji będzie on przechowywał informacje na temat
produktów, działów sklepu, użytkowników, zawartości koszyków zakupów itp.
Rysunek 3. Wynik ankiety z której wynika, że MySQL jest najpopularniejszą bazą danych wśród programistów
PHP. Tabela pochodzi z: http://www.zend.com/zend/php_survey_results.php (7.III.2007) (10)
3.4.1. Niektóre z zalet MySQL
Za wieloma publikacjami na temat MySQL-a można wymienić wiele jego zalet. Należą do nich
miedzy innymi:
Wydajność
MySQL jest bardzo szybki. Dowodem na to stwierdzenie są testy wydajności
przedstawione pod adresem http://web.mysql.com/benchmark. W wielu testach
MySQL wypada lepiej niż jego konkurenci.
Niski koszt
MySQL jest do pobrania za darmo , jego wykorzystywanie w użyciach
niekomercyjnych nie jest również obarczone opłatami. Po niskich kosztach można
również zakupić licencję komercyjną.
Łatwość użycia
Większość z nowoczesnych baz danych korzysta z języka SQL. Użytkownik który
korzystał z innych systemów RDBMS, nie powinien mieć problemów z pracą z MySQL15
em. Ponadto MySQL jest łatwiejszy w konfiguracji, niż wiele innych konkurencyjnych
produktów.
Przenośność
MySQL może pracować na wielu systemach, zarówno pod systemami Unixowymi jak i
pod Microsoft Windows.
Kod źródłowy
Podobnie jak w przypadku PHP, użytkownik może pobrać jak i modyfikować kod
źródłowy w zależności od swoich potrzeb.
7. Zaistnienie w Internecie
Stworzenie odpowiedniej witryny e-commerce nie jest jeszcze gwarantem sukcesu jej
działania. Należy jeszcze podjąć odpowiednie kroki, które doprowadzą do zaistnienia witryny
w Internecie. Celem jest sytuacja w której na dane słowo bądź słowa kluczowe nasza witryna
umiejscowiona była w wynikach wyszukiwania jak najwyżej. Żeby zobaczyć jakiekolwiek wyniki
potrzebne są wyszukiwarki, a żeby zobaczyć swoją stronę w wynikach należy ją dodać np. do
katalogów stron. Na tym nie koniec. Swojej strony nie zobaczymy wysoko w wynikach dopóki nie
zadbamy o jej optymalizację i pozycjonowanie.
Tą właśnie tematyką zajmę się w tym rozdziale. Bardzo pomocną pozycją literaturową przy
opracowaniu tego rozdziału była książka „Czas na e-biznes” [12] autorstwa Piotra Majewskiego a w
szczególności jej rozdział 12 oraz książka „osCommerce Tworzenie sklepów internetowych” (12)
7.1 Wyszukiwarki
Wyszukiwarki są istotnym elementem sukcesu witryn e-commerce. Nowo powstałe serwisy
nie mają szans na zyskanie popularności za pomocą crosslinkingu2. Przez ograniczone
fundusze często poza zasięgiem pozostają marketing bezpośredni czy masowe kampanie w
internecie, wówczas najlepszym i najtańszym rozwiązaniem pozostają wyszukiwarki. Jedyną
wadą tego rozwiązania może być długi czas oczekiwania na rezultaty.
2
Crosslinking – techniki polegające na wzajemnym promowaniu się stron internetowych. Może on przybrać
formę wymiany banerów lub zwykłych linków tekstowych.
16
Nie jest prawdą, że promocja poprzez wyszukiwarki polega na dodaniu do ich zbiorów jak
największej ilości naszych stron, które mogą przyciągnąć internautę do naszej witryny ecommerce. Na promocję w ten sposób należy poświęcić dużo czasu.
Stronę należy odpowiednio przygotować przed dodaniem ją do zbiorów wyszukiwarek. Jak
niektórzy określają, stronę należy napisać „pod wyszukiwarkę”. Polega to na umieszczeniu w
niej jak największej liczby słów kluczowych.
Według autora książki „Czas na e-biznes”:
„Słowa kluczowe (ang. keywords) – słowa lub frazy, jakie potencjalni klienci wpisują w
wyszukiwarkach, aby znaleźć produkt (usługę) identyczny z tym, co oferujesz”
Należy zwrócić uwagę na formułowanie tych słów, gdyż najczęściej to biznes próbuje opisać
swój produkt, jednak tak naprawdę to potencjalni klienci decydują jak określić dany produkt.
Listę najczęściej wprowadzanych w Polsce słów kluczowych można znaleźć pod adresem:
boksy.onet.pl/ranking.html.
Stosowany od dawna sposób umieszczania wielu słów kluczowych w znacznikach META nie
jest już skuteczny. Obecnie Google.com nie czyta już tych znaczników. Pozostaje jeszcze
wiele innych mniej lub bardziej znanych technik.
Sytuacja w Polsce
Na podstawie danych zebranych przez firmę Gemius SA i jej serwis www.ranking.pl można
dowiedzieć się które wyszukiwarki w Polsce (również i zagranicą) cieszą się największą
popularnością wśród polskich internautów. Wiarygodność przeprowadzonych badań
potwierdzają dane zebrane z dużej ilości polskich serwisów.
lp
Wyszukiwarki-domeny
22.V.2007 - 28.V.2007
1
google.com
85,5%
2
onet.pl
6,5%
3
wp.pl
4,8%
4
interia.pl
1,1%
5
msn.com
0,8%
6
szukacz.pl
0,5%
17
7
yahoo.com
0,4%
Tabela 2. Wyszukiwarki - domeny, z których trafiają na polskie witryny internauci łączący się z obszaru Polski,
Źródło: Gemius SA, gemiusTraffic (13), 4 czerwca 2007 r.
Z badań wynika jednoznacznie, iż w Polsce liderem jest serwis google.com z udziałem 85,5%,
daleko za nim znajdują się onet.pl, wp.pl oraz inne serwisy. Przewaga google.com jest
ogromna, wypracowana przez ostatnie lata co ukazują wyniki badan na przestrzeni ostatnich
lat (Rysunek 5.). Tak więc na podstawie badań, jednoznacznie mogę powiedzieć iż aby
zaistnieć ze swoja witryną e-commerce wśród polskich internautów – potencjalnych
klientów, należy się skupić na wypracowaniu pozycji w wyszukiwarce Google.com.
Rysunek 4. Wyszukiwarki – domeny (trzy z największym udziałem), z których trafiają na polskie witryny
internauci łączący się z obszaru Polski na przestrzeni kilku ostatnich lat, Źródło: Gemius SA, gemiusTraffic
(13), 4 czerwca 2007 r.
Wyszukiwarki - działanie
Liczące się wyszukiwarki nie różnią się między sobą zasadą działania. Ponadto większość z
nich wykorzystuje zbliżone algorytmy dla ustalenia pozycji strony www w rankingu
wyszukiwania. Praktycznie żadna licząca się wyszukiwarka nie korzysta wyłącznie ze swojej
bazy stron www. Wiele, jak np. wp.pl, nie posiada nawet własnej bazy i wykorzystuje zasoby
wykupione wraz z licencją od firmy zewnętrznej. Onet.pl ma własną bazę danych, ale silnik
(oprogramowanie wyszukiwarki, z ang. engine ) kupiony od firmy Inktomi, która przejęła
Infoseek. Każdy silnik działa mniej więcej na tej samej zasadzie, ale każdy ma swoje, w pełni
konfigurowalne algorytmy wpływające na strukturę rankingu. Mimo faktu, że administrator
wyszukiwarki ma pewien zakres swobody w przypisywaniu wagi poszczególnym elementom
strony www - czyniąc każdą kopię silnika unikalną - to jednak pewne cechy pozostają
wspólne. Ten fakt bardzo pomaga wpływać właścicielom stron www na ranking.
18
Administratorzy odpowiedzialni za polskie wyszukiwarki starają się, aby informacje dotyczące
konstrukcji ich algorytmów wyszukujących nie przedostawały się na zewnątrz. Stąd większość
specjalistycznej wiedzy to wynik testów i doświadczenia w pozycjonowaniu.
Fakt, że polskie wyszukiwarki wykorzystują oprogramowanie zachodnich producentów bardzo
pomaga w zdobywaniu informacji na ich temat, gdyż wiedzę z polskiego rynku można uzupełniać o
doświadczenia internautów spoza granic Polski.
Działanie większości wyszukiwarek oparte jest na podobnych zasadach, jednocześnie
wykorzystują zbliżone algorytmy pozycjonowania stron w rankingach wyszukiwania. Składają
się z 4 podstawowych elementów:
1.
2.
3.
4.
Pajączka (inne angielskie określenia: Spider, Crawler)
Bazy danych,
Indeksu,
Programu wyszukującego.
Bardzo często dokonuje się uproszczenia polegającego na rozciągnięciu nazwy "index" również na
bazę danych.
Pajączek czyta i interpretuje kod zleconych mu stron, podobnie jak czyni to przeglądarka. Jednak w
przeciwieństwie do przeglądarek, czyści interpretowany kod z niepotrzebnych znaczników HTML i
zapamiętuje tylko interesujący go tekst. O tym gdzie można go było znaleźć w kodzie strony (np. czy
był tytułem, nagłówkiem typu H1 czy też zwykłym tekstem) dany tekst informuje każdorazowo
program wyszukujący za pomocą własnych znaczników.
Po przeczytaniu strony pajączek podąża po linkach (odnośnikach) do podstron w tej samej domenie,
aby i je przeczytać. Tak operacja otrzymała w języku angielskim określenie „deep crawling”.
Głębokość na jaką dociera pajączek zależy od wyszukiwarki. Przyjęto że najważniejsze strony nie
powinny być dalej niż dwa „kliknięcia od strony głównej”. Po „przejściu” danego serwisu poprzez linki
kierujące na zewnątrz, pajączek trafia do innych, nieznanych mu wcześniej stron.
Aby ich pajączek miał dojście do jak największej liczby serwisów administratorzy nowo
uruchamianych wyszukiwarek (celem większości tych ostatnich jest dostarczenie prawidłowego
rankingu, co wymaga dotarcia do maksymalnej liczby stron) gromadzą "ręcznie" pewien zasób stron
WWW (głównie portali i katalogów). Jest to tzw. baza wyjściowa. Po linkach znajdujących się na
stronach wchodzących w skład bazy i za pośrednictwem stron przez nią znalezionych pajączek może
dotrzeć do prawie wszystkich stron, gdyż do prawie wszystkich ktoś się kiedyś odwoływał.
Warto w tym miejscu dodać, że promocja strony w wyszukiwarkach nie ogranicza się jedynie do
konieczności zbudowania witryny zgodnego ze standardami umożliwiającymi pajączkowi jej
zindeksowanie, a następnie do biernego oczekiwania na jego wizytę. Nie czekając na takie
odwiedziny należy samemu "zaprosić" pajączka wypełniając formularz wyszukiwarki. Potocznie
19
czynność ta nazywana jest "dodawaniem stron do wyszukiwarki" jednak nie jest to równoznaczne ze
zindeksowaniem strony przez wyszukiwarkę. Dlatego wysyłanie formularza należy ponawiać aż do
pojawienia się wyszukiwanej strony w wynikach. Po pewnym czasie pajączek wraca na zindeksowane
uprzednio strony. Dzieję się tak także po ponownym zaproponowaniu strony do indeksacji. Sprawdza
wówczas czy strony nie uległy zmianie. Gdy tak się stało pajączek pobiera nasze dane.
W Bazie danych dzięki pajączkom przekazującym zebrane informacje znajduje się pełny
zapamiętany tekst. Dla optymalizacji procesu wyszukiwania program stosuje tzw. "stop
words" - słowa pozbawione konkretnego znaczenia (np. spójniki, rodzajniki), których nie
uwzględnia się w wyszukiwaniu. Przykład: Gdy wyszukiwarce Google, zadamy pytanie "the
war" to program wyszukujący przejrzy indeks tylko według słowa "war", "the" dla szybszego
rezultatu zostanie pominięte. Jednakże w opisach stron "the" pozostanie.
Index to spis wszystkich unikalnych słów wraz z odnośnikami do miejsc ich występowania w
bazie danych, pełniących rolę zbliżoną do tej, wypełnionej przez indeksy spotykane w
książkach. Powstaje poprzez indeksowanie bazy danych, aktualizowane po dodaniu nowego
wpisu. Właśnie od tego, czy strona została uwzględniona w indeksie, zależy czy pojawi się
ona przy wyszukiwaniu.
Program wyszukujący Po wpisaniu w formularzu wyszukiwarki danego hasła przeszukuję
indeks w jego poszukiwaniu. Jeśli zostanie znalezione, program wyszukujący czyta z bazy
danych wszystkie strony, oznaczone w indeksie jako zawierające dane zapytanie. Następnie
posługując się własnymi algorytmami ocenia wartość danej strony. Za ocenę stron może też
odpowiadać dodatkowy program (w Google jest nim PageRank oceniający wartość strony na
podstawie stron zawierających link do danej strony) i np. fakt pojawienia się strony w
katalogu. Na podstawie ocen jest tworzony ranking.
PageRank narzędziem serwisu google.com które odpowiada, za ocenianie poszczególnych
stron. Dokonuje tego głównie na podstawie ilości stron z których istnieje bezpośredni link do
ocenianej strony (ang. link popularity).
Wzór według którego działa PageRank jest dość skomplikowany. Jednak w pewnym
uproszczeniu można przedstawić go tak: „ … każda strona zawierająca link do naszej strony
oddaje na nią jeden głos. Ten głos ma jednak pewną wagę, która zależy od tego, jaka jest
wartość PageRank strony głosującej i ile zawiera ona linków do innych stron. Z kolei link z
naszej strony na zewnątrz odejmuje nam jeden głos. Jeszcze uproszczając: link z głównej
strony portalu będzie wielokrotnie bardziej cenny niż link z kategorii w katalogu WWW. Do
strony głównej katalogu kieruje bardzo dużo linków, a ona sama zawiera mało
wychodzących. Celem katalogu jest bowiem kierowanie nas do innych, mało kto natomiast
linkuje do konkretnej kategorii w katalogu.” (14)
20
Podsumowując, wartość PageRank zależy od liczby stron z których przez link, można dotrzeć
bezpośrednio do naszej strony oraz od wartości tych głosów. Wartości głosów zależą zaś od:
pozycji w PageRank strony głosującej na naszą witrynę, liczby linków wychodzących na tej
stronie, treści linku zawartej pomiędzy znacznikami, prawdopodobnie wartość PageRank jest
uzależniona również od miejsca umieszczenia łącza w kodzie, im wyżej tym lepiej.
Na co zwracają uwagę pajączki.
Każda wyszukiwarka zbiera różne informacje poprzez „wędrującego” po witrynach
internetowych pajączka. Zapisują one jedynie te dane które we własnym algorytmie są
wykorzystywane do pozycjonowania stron.
Niektóre wyszukiwarki oprócz minimum informacji potrzebnych do generowania rankingu
tworzą oddzielne bazy danych w których umieszczają kopie zaindeksowanych stron. Tak
postępują między innymi serwisy google.com oraz wp.pl (Wirtualna Polska).
Informacji które czytają prawie wszystkie pajączki obejmują:
Cały tekst strony – czyli zawartość strony pomiędzy znacznikami BODY, niektóre
pajączki oszczędzają miejsce i zapamiętują nie więcej niż 64kB tekstu.
TITLE – Wszystkie pajączki czytają tytuły stron, czyli tekst umieszczany pomiędzy
znacznikami TITLE.
<TITLE> Tytuł strony </TITLE>
Znaczniki META – Większość współczesnych wyszukiwarek nie zwraca już uwagi na
znaczniki META (Description i Keywords – znaczniki w sekcji <HEAD> strony). Jednak
nie należy ich zupełnie ignorować, gdyż w przypadku mało konkurencyjnych słów
mogą mieć znaczenie dla wyszukiwarek. Dodatkowo niektóre przeglądarki
wykorzystują META Description do opisania strony w wynikach wyszukiwania.
<META NAME=”description” CONTENT=”Tutaj znajduje się opis
strony”>
<META
NAME=”keywords”
CONTENT=”Tutaj
znajdują
się
słowa
kluczowe, oddzielone przecinkami”>
Ramki - Polskie wyszukiwarki wspierają obsługe ramek (ang. frames), jednak obsługę
tą można określić za niepełną, gdyż wyszukiwarka prześledzi treść ramki, lecz
zaindeksuje ją jako oddzielną stronę. Tak więc internauta klikając na link wyświetlony
przez wyszukiwarkę, może nigdy nie dotrzeć do głównej strony, a np. do ramki menu
lub któreś ze stron wewnętrznych.
21
Link popularity – Określa liczbę stron które posiadają link do promowanej przez nas
strony. Oczywiście strony te nie mogą być częścią naszej witryny. Określenie to
zostało wprowadzone przy założeniu, że do ciekawych i wartościowych stron będzie
istniało wiele łączy w sieci. Metodę tą wykorzystuje wcześniej opisany mechanizm
PageRank stosowany przez Google.
Linki (łącza) – Jeśli chodzi o linki, to przeglądarki najlepiej czytają linki tekstowe,
również z linkami graficznymi większość nie ma problemów. Zaś tylko niektóre
poradzą sobie z mapami linków (ang. client-side image maps). Ważną rzeczą jest
umieszczanie słów kluczowych w anchor text – czyli w treści linku zewnętrznego.
Anchor text to treść zawarta pomiędzy znacznikami <A>. Tak więc większą wagę
będzie miło umieszczenie słów kluczowych w linku niż np. adresu WWW. W
przypadku linków graficznych jako anchor text będzie potraktowana zawartość
parametru ALT.
Żadne pajączki nie zapamiętują:
Komentarzy w kodzie
Treści plików graficznych oraz plików zewnętrznych, np. JavaScript. Dla tego typu
plików stworzono znaczniki TITLE oraz ALT, które wyszukiwarki już czytają.
7.2 Pozycjonowanie
Powstawanie rankingu
Przy tworzeniu witryny należy pamiętać o tym, iż wyszukiwarki są stworzone do tego aby
dostarczać swoim użytkownikom adresy stron które będą zawierały jak najwięcej danych na
szukany temat. Właśnie w tych celach powstał ranking.
Na uszeregowanie stron w rankingu według ich wartości wpływają trzy elementy:
odpowiedzi strony na zadane pytanie,
wartość strony,
boost
Odpowiedzi strony na zadane pytanie, polega najczęściej na występowaniu szukanego słowa
czy frazy w treści strony zapamiętanej przez pajączka. Fakt ten decyduje czy strona pojawi się
w rezultatach wyszukiwania przedstawianych przez wyszukiwarkę.
22
Wartość Strony zawsze jest określana w stosunku do zadanego pytania. W sytuacji gdy
wyszukiwarka używa takich narzędzi jak Link Popularity, dodatkowo sumowana jest wartość
określana na podstawie zawartości strony z wartością bezwzględną wynikającą z liczby
zewnętrznych łączy.
Ważnym aspektem jest również przynależność witryny do kategorii odpowiadającej na
pytanie. Przykładem może być tutaj sytuacja pytania zawierającego słowo kluczowe
„książki”. Wyżej będzie notowana strona e-commerce księgarni internetowej niż strona
konkretnego pisarza, na której będzie wymienionych tylko kilka/kilkanaście pozycji. Będzie
się dziać tak a nie inaczej gdyż a stronie księgarni będzie więcej odwołań do szukanego słowa
kluczowego.
Tytuł
Bardzo ważną rolę w pozycjonowaniu pełni tytuł (TITLE) strony. Jeśli w tytule umieścimy
słowo(a) kluczowe zwiększamy wielokrotnie szanse na znalezienie się na szczycie naszej
witryny.
Nie należy jednak przesadzać ilością słów kluczowych w tytule, gdyż wyszukiwarki
zapamiętują tylko kilkadziesiąt pierwszych znaków umieszczonych w tych znacznikach. Np.
serwis Onet.pl zapamiętuje jedynie pierwszych 95 znaków.
Adres WWW
Następnym bardzo ważnym elementem w pozycjonowaniu jest adres WWW strony.
Najczęściej adresy stron które w domenie zawierają słowa kluczowe znajdują się na szczycie
wyników wyszukiwania. Wyszukiwarka Google jest szczególnie wyczulona na ten aspekt.
Słowa kluczowe w nazwie katalogu również zwiększają wartość strony, lecz nie tak
bardzo jak w domenie.
Znaczniki META
Jeśli chodzi o znaczniki META odgrywają one już coraz mniejszą rolę. W światowym internecie
dąży się do ich całkowitego porzucenia w systemach pozycjonowania.
Przy pomocy znaczników META twórca strony może opisać ją w dowolny sposób, nawet nie
związany z treścią witryny.
Częstotliwość
Częstotliwość jest stosunkiem ilości powtórzeń szukanego słowa do ilości wszystkich słów na
stronie. Jest to kolejny ważny element uzyskania wysokiej pozycji w wynikach wyszukiwarek.
Słowa te mogą być umieszczone w tekście, tytule, opisach i słowach kluczowych.
23
Jednak nie jest prawdą, że wystarczy umieścić wiele razy słowa kluczowe (np. sto razy), gdyż
wyszukiwarki posiadają detektory SPAMU3. Tak więc możemy osiągnąć wynik wręcz
odwrotny do naszego celu – w rankingu stron zawierających dane słowa kluczowe możemy
znaleźć się na końcu. Zalecana częstotliwość wynosi 3-9%.
Jeśli wyszukiwarka posiada funkcję Stemming Words określana przez nią częstotliwość może
znacznie wzrosnąć. Funkcja ta pozwala na liczenie danych słów kluczowych nawet jeśli
występują w różnych przypadkach czy liczbach.
Gdy już obliczona zostanie Wartość Strony pozostaje doliczenie punktów za Boost. Boost
daje dodatkowe punkty do Wartości za spełnianie pewnych kryteriów. Oto najważniejsze:
Lokalizacja słów kluczowych
Słowa kluczowe znajdujące się blisko góry KODU strony – nieistotne jest, jak ona będzie
wyglądała w przeglądarce, ale gdzie w kodzie strony znajduje się szukane słowo.
Nagłówki H1
Od dawna wiadomo, ze pojawienie się szukanego słowa w Nagłówku H1-H6 jest bardzo
korzystne dla pozycji strony. Najlepiej jeśli jest to Nagłówek H1 i jest to pierwsza informacja
na stronie.
Występowanie w katalogu
Często strony, które znajdują się w katalogu załączonym do wyszukiwarki (recenzowane
przez ludzi) dostają dużo lepsze wyniki.
Najważniejsze w Polsce wyszukiwarki preferują odpowiednio:
Google - Open Directory Project (www.dmoz.org)
Onet.pl - Ogólnopolski Katalog Onetu (katalog.onet.pl)
Wirtualna Polska - Katalog WP (katalog.wp.pl)
Link Popularity
Dobry link popularity strony, czyli wiele łączy z dobrych stron do naszej strony z anchor text
zawierającym nasze słowa kluczowe (linki do naszej strony zawierające w polu anchor text
adres naszej strony dają gorszy efekt), może bardzo pomóc naszej witrynie w znalezieniu się
na wysokiej pozycji w rankingu.
3
Spam w wyszukiwarkach - efekty technik wpływania na wyniki wyszukiwania w wyszukiwarkach
internetowych z naruszeniem regulaminu systemów wyszukujących. Określa ogół technik stosowanych do
podwyższenia pozycji danej strony w wyszukiwarkach (pozycjonowania), dotyczących wybranych słów
kluczowych, które nie są związane bezpośrednio z treścią strony lub nie stanowią celu komercyjnej działalności
strony.
24
Należy zwrócić uwagę aby promować tylko jedną wersję domeny, np. pawlos.pl lub
www.pawlos.pl. Są one różnie traktowane przez wyszukiwarki, „www” przed domeną ma
znaczenie.
Wyżej wymienione metody należą do bezpiecznych, czyli nie są uznawane za SPAM,
przeglądarki nie ukażą nas za ich stosowanie.
Do metod niebezpiecznych, za które możemy zostać ukarani należą:
Duplikowanie słów kluczowych w znacznikach META i TITLE – bezpieczne jest 2-, 3krotne powtorzenia słowa kluczowego w znacznikach META i TITLE, powinny one
jednak być oddzielone innymi słowami.
Używanie słów kluczowych w znacznikach META i TITLE niewystępujących w tekście
strony.
Niewidzialny tekst – niewidzialny tekst (ang. invisible text) to zwykle tekst w kolorze
tła. Inną techniką tego typu jest również stosowanie malutkich tekstów (ang. tiny
text). Najczęściej malutkie teksty są realizowane przez stosowanie wielkości czcionki
rzędu 1 piksela. Użytkownik w takiej sytuacji, nie ma praktycznie szans, aby zobaczyć
w ten sposób wyświetlany tekst.
Jump pages, doorway pages, portal pages itd. Techniki te polegają na tworzeniu stron
maksymalnie nastawionych wymagania wyszukiwarek. Nie są one atrakcyjne dla
użytkownika. Dlatego, często takie strony są automatycznie przekierowywane na
główną stronę serwisu.
Cloaking – technika ta jest najbardziej kontrowersyjną w technikach pozycjonowania.
Polega ona na przygotowywaniu i przedstawianiu stron pod konkretne wyszukiwarki.
Przy czym pajączki również traktujemy jako przeglądarkę. Technika ta może być
stosowana uczciwie lub mniej uczciwie.
o uczciwe – przygotowywanie odpowiedniej strony pod konkretnego
użytkownika (np. język, przeglądarka)
o mniej uczciwe – techniki te polegają na przygotowywaniu stron pod
konkretne pajączki. Pajączki są reprezentowane przez Agentów i związanych z
nimi adresami ip. Skrypty mogą po zidentyfikowaniu konkretnego Agenta i
(lub) jego ip przedstawić mu specjalnie przygotowaną stronę specjalnie pod
konkretną wyszukiwarkę.
Farmy linków – to zorganizowane setki stron, które nawzajem linkują się nawzajem.
Rozwiązanie to jednak tak jak wcześniej wymienione jest już znane wyszukiwarką i
nie działa. Zostało jednak wymyślone lepsze rozwiązanie. W Polsce powstały 2 ważne
serwisy: www.linkor.pl oraz www.linkujpro.pl – są to systemy wymiany linków
(odpowiednio dynamicznie generowanych i statycznych). Pozwoliły one wielu
serwisom znacznie zwiększyć oglądalność.
25
Spamowanie w najlepszym wypadku nie pomoże osiągnąć lepszej pozycji, w najgorszym
można być trwale usuniętym z bazy danych wyszukiwarki. W wykrywaniu spamu oraz
usuwaniu z rankingów przoduje Google, jednakże również Onet.pl czasami usuwa strony z
rankingu.
Każda "specjalna" technika, która jest skuteczna dzisiaj, jutro może być uznana
za spam. Każda spamerska technika była kiedyś techniką "specjalną". Należy o tym pamiętać
w czasie promowania stron używając najnowszych pomysłów na uzyskanie wysokiej pozycji
w wyszukiwarkach.
Najlepsza strategia dotycząca wyszukiwarek
Należy tworzyć strony zawierające wiele treści. Nawet jeśli treści SA płatne, należy
udostępniać fragmenty wszystkich artykułów.
Każda strona powinna mieć własne pole TITLE oraz znaczniki META.
Wszystkie strony powinny być polinkowane, tak aby z każdej z nich po 1-2
kliknięciach można było dotrzeć do dowolnej strony witryny.
Należy zadbać o istnienie linków z innych stron powiązanych z naszą do naszej
witryny (można wykorzystać www.linkor.pl oraz www.linkujpro.pl).
Ważne jest opisywanie linków graficznych parametrem ALT.
26
Narzędzia do pozycjonowania
www.digitalpoint.com/tools/suggestion/ - Dzięki niemu możemy poznać słowa
kluczowe podobne do tego co podaliśmy (w formularzu), najczęściej wykorzystywane
przez użytkowników.
https://adwords.google.com/select/KeywordSandbox - Narzędzie do zarządzania
słowami kluczowymi. Podobne do powyższego. Oparte na wynikach z Google.
www.googlerankings.com/index.php - Doskonałe narzędzie, dzięki któremu możemy
poznać pozycję naszej (i nie tylko) strony w rankingu wyszukiwawczym Google pod
względem
danego
słowa
kluczowego
(które
sami
wpisujemy).
www.kwmap.com/ - Narzędzie obrazujące i badające bliskoznaczne słowa i frazy
kluczowe. Podobne do przedstawionych powyżej dwóch pierwszych narzędzi. Tego
typu
programy
najlepiej
używać
razem.
www.rustybrick.com/pagerank-prediction.php - Rzekomo potrafi przewidywać jaki
będzie PageRank strony po kolejnej aktualizacji bazy danych w Google
www.gritechnologies.com/tools/spider.go - To narzędzie pokazuje, jakie prowadzą z
danej WWW - adres wpisujemy w okienku.
Narzędzia do określania częstotliwości słów kluczowych
Keyword density analyzer: www.webjectives.com/keyword.htm
KeywordCount: www.KeywordCount.com
Narzędzia do określania Link Popularity
LinkPopularity: www.linkpopularity.com
Zapytanie w Onet.pl/ Altavista:
link:cneb.pl -url:cneb.pl -url:cneb.pl
Zapytanie w Wirtualna Polska:
link: cneb.pl -url: cneb.pl
Zapytanie w Google.com:
27
link:cneb.pl -site: cneb.pl
28
Bibliografia
1. Witryna projektu PHP. [Online] http://www.php.net/.
2. [Online] http://news.netcraft.com.
3. Hayder, H., Maia, J. P. i Gheorghe, L. Smarty – Szablony w aplikacjach PHP. Gliwice : Helion, 2007.
ISBN: 987-83-246-0647-4.
4. Nowojczyk, Dariusz. (Nie)szablonowa prezentacja. CHIP. 05/2005.
5. Balanescu, Emilian, Bucica, Mihai i Darie, Cristian. PHP i MySQL zastosowania e-commerce.
Gliwice : Helion, 2005. ISBN: 83-7361-830-9.
6. Witryna projektu Smarty. [Online] http://smarty.php.net.
7. Thomson, Laura i Welling, Luke. PHP i MySQL Tworze stron WWW Vademecum profesjonalisty.
Wydanie drugie. Gliwice : Helion, 2003. ISBN: 83-73-61-140-1.
8. Naramore, Elizabeth, i inni. Php5 Apache MySQL - Od podstaw. Gliwice : Helion, 2005. ISBN: 837361-997-6.
9. ???????? uzupelnic .
10. [Online] http://www.zend.com/zend/php_survey_results.php.
11. Bargieł, Daniel i Marek, Sebastian. Tworzenie sklepów internetowych PHP i MySQL. Wydanie
drugie. Gliwice : Helion, 2006. ISBN: 83-7361-939-9.
12. Mercer, David. osCommerce Tworzenie sklepów internetowych. Gliwice : Helion, 2007. ISBN: 97883-246-0649-8.
13. Gemius SA. gemiusTraffic. [Online] www.ranking.pl.
14. Majewski, Piotr. Czas na e-biznes. Wydanie drugie. Gliwice : Helion, 2007. ISBN: 83-7361-939-9.
29