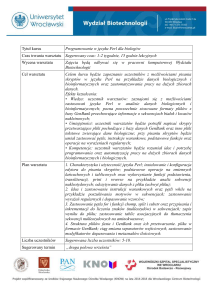
Schemat systemu komputerowego
Sp r zę t k o m p u te ro w y
(je d n o stk a c e n tra ln a p ro c e so r, p a m ię ć ,
u rzą d ze n ia w e jśc ia -w y jśc ia )
Sy ste m o p e ra c y jn y
O p ro gra m o w a n ie u Ŝy tk o w e (b a zy d a n y c h , e d y to ry , a se m b le ry ,
k o m p ila to ry ...)
.• • •
U Ŝy tk o w n ic y
Hierarchia maszyn wirtualnych wg Weidermana
M5
M4
S3
S4
M3
S2
M4’
M3’
M2
M1
M0
S3’
S2’ M - maszyna wirtualna
i
Si - oprogramowanie
S1
M0 - maszyna rzeczywista
S0
System operacyjny jest to zbiór
programów umoŜliwiających:
• efektywny podział
urządzeń systemu
(zasobów maszyny)
• dostarczenie
uŜytkownikowi
komputera
wirtualnego dla jego
potrzeb
• jednoczesną realizację
procesów
obliczeniowych dla
potrzeb jednego lub
wielu uŜytkowników
Kategorie „czystych” systemów
operacyjnych
( tryby pracy SO )
• dla przetwarzania wsadowego
( off-line, batch )
• z podziałem czasu - tryb bezpośredni,
interakcyjny ( on-line )
• dla działania w czasie rzeczywistym
( real-time )
Metody realizacji systemu
operacyjnego:
• zastosowanie wieloprogramowości
• zastosowanie wymiany ( swapping )
• wieloprocesorowość
HISTORIA
•
•
•
•
•
•
•
•
•
proste systemy operacyjne
systemy wsadowe
buforowanie i spooling
wieloprogramowość
wielozadaniowość
systemy dla komputerów osobistych
systemy równoległe
systemy rozproszone
systemy czasu rzeczywistego
Zrównoleglenie we/wy w pojedynczej maszynie
buforowanie
we
bufor
jedn.centralna
bufor
wy
Metoda jednoczesnego wykonywania obliczeń i wejścia-wyjścia dla
jednego zadania:
• nie eliminuje całkowicie przestojów CPU czy urządzeń we-wy
• wymaga przeznaczenia pamięci na systemowe bufory
• niweluje wahania w czasie przetwarzania danych
Zrównoleglenie we/wy w pojedynczej maszynie
spooling (simultaneous peripherial operation on-line)
przenoszenie danych do szybszej pamięci zewnętrznej
we
dysk
jedn.centralna
dysk
Metoda jednoczesnego wykonywania wejścia-wyjścia jednego
zadania i obliczeń dla innego zadania
MoŜliwe dzięki upowszechnieniu się systemów dyskowych
Podczas wykonywania jednego zadania system operacyjny:
– czyta następne zadanie z czytnika kart na dysk (kolejka zadań)
– drukuje umieszczone na dysku wyniki poprzedniego zadania
Pula zadań - moŜliwość wyboru kolejnego zadania do
wykonania
wy
Wieloprogramowość
• wprowadza się wiele zadań do wykonania
• program jest przetwarzany w procesorze centralnym dopóki nie
musi być wykonane we/wy
• szeregowanie zadań
• efektywne wykorzystanie zasobów systemu
• przetwarzanie wsadowe
Wielozadaniowość
• zadania przetwarzane współbieŜnie (podział czasu)
• dostęp bezpośredni zamiast przetwarzania wsadowego
• priorytety
Udogodnienia sprzętowe
• Mechanizm przerwań
• Ochrona pamięci operacyjnej
• Zbiór rozkazów uprzywilejowanych
• Zegar czasu rzeczywistego
Sterowanie przerwaniami
( interrupt drive)
Algorytm układu sterowania JC
•
•
•
•
pobierz następny rozkaz
zwiększ licznik rozkazów
wykonaj rozkaz
jeśli jest przerwanie, realizuj to, które ma
największy priorytet
• przejdź do punktu pierwszego
STRUKTURY SYSTEMÓW
KOMPUTEROWYCH
• Struktura jednolita
• Struktura warstwowa
• Struktura klient-serwer
Programy uŜytkowe
Rezydujące programy systemowe
Programy obsługi
urządzeń z poziomu
MS-DOS
Programy obsługi urządzeń z poziomu pamięci
ROM BIOS
Warstwowa struktura systemu MS-DOS
UŜytkownicy
programy shell i polecenia
kompilatory i interpretery
biblioteki systemowe
Interfejs funkcji systemowych jądra
sygnały
obsługa terminali
system znakowego we/wy
programy obsługi terminali
system plików
wymiana
system blokowego we/wy
programy obsługi
dysków i taśm
planowanie przydziału procesora
zastępowanie stron
stronicowanie na Ŝądanie
pamięć wirtualna
Interfejs między jądrem a sprzętem
sterowniki terminali
terminale
sterowniki urządzeń
dyski i taśmy
sterowniki pamięci
pamięć operacyjna
Struktura systemu UNIX
Pamięć operacyjna
(main memory)
• obszar bezpośrednio dostępny dla procesora
• rozkazy: load, store (PAO ⇔rejestr procesora)
• cykl rozkazowy:
• pobranie rozkazu z PAO do rejestru rozkazów
• dekodowanie
• realizacja (ew. pobranie argumentów z PAO
Program i dane nie mogą być na stałe w PAO
• za mała
• ulotna
Pamięć pomocnicza (secondary storage)
• rozszerzenie PAO
• trwałe przechowywanie duŜej ilości danych
• źródło i miejsce przeznaczenia informacji
sprowadzanie danych do PAO (op. we/wy)
• rejestry sterowników <==> PAO
• we/wy odwzorowane w pamięci (memory mapped I/O)
wydzielenie adresów PAO na rejestry urządzeń
(ekran, porty szeregowe i równoległe)
Wysłanie ciągu bajtów przez port szeregowy:
•
•
•
•
procesor wpisuje 1 bajt do rejestru danych
procesor ustawia bit w rejestrze kontrolnym
urządzenie pobiera bajt danych
urządzenie zeruje bit w rejestrze kontrolnym
1. Programowane we/wy (programmed I/O)
2. Przesyłanie sterowane przerwaniami
(interrupt driven)
REJESTRY - wbudowane w JC (1 cykl zegara)
dostęp do PAO - za pośrednictwem szyny pamięci
wiele cykli; utykanie procesora (stall)
SZYBKA PAMIĘĆ POMOCNICZA (cache)
JC->cache->PAO
HIERARCHIA PAMIĘCI
REJESTRY
PAMIĘĆ PODRĘCZNA
PAMIĘĆ OPERACYJNA
DYSK ELEKTRONICZNY
DYSK MAGNETYCZNY
DYSK OPTYCZNY
TAŚMY MAGNETYCZNE
Pamięć podręczna
•
•
•
•
przechowuje informacje przejściowo
80-99% dostępów
polityka zastępowania informacji
problem zgodności pamięci podręcznej:
• te same dane na róŜnych poziomach hierarchicznej struktury pamięci
–
–
–
–
A++ (liczba A w pliku B na dysku)
kopiowanie bloku z liczbą A do PAO
kopiowanie do pamięci podręcznej
kopiowanie do rejestru wewnętrznego
inkrementacja w rejestrze........
problem w środowisku wieloprocesorowym
cache coherency
PAMIĘĆ POMOCNICZA
• SO dostarcza jednolitego logicznie obrazu
przechowywania informacji w oderwaniu
od cech fizycznych urządzeń
• PLIK - logiczna jednostka informacji
• system plikowy:
• zbiór plików
• struktura katalogów
zadania SYSTEMU PLIKÓW
•Pozwala tworzyć i usuwać pliki
•UmoŜliwia dostęp do plików w celu czytania i pisania
•Zarządza automatycznie przestrzenią pamięci
pomocniczej
•UmoŜliwia odwoływanie się do plików za pomocą nazw
symbolicznych
•Chroni pliki przed skutkami uszkodzenia systemu
•Pozwala na wspólne korzystanie z tych samych plików
•Chroni pliki przed dostępem do nich nieuprawnionych
uŜytkowników
plik moŜe być otwarty przez kilku uŜytkowników
dwa poziomy tablic wewnętrznych:
wewnętrznych
• procesowa tablica plików otwartych w procesie
– bieŜący wskaźnik do kaŜdego pliku
– wskaźnik do ogólnosystemowej tablicy plików otwartych
• ogólnosystemowa tablica otwartych plików
–
–
–
–
połoŜenie pliku na dysku
daty dostępu
rozmiar pliku
licznik otwarć
• dyskowe operacje we/wy w jednostkach równych
pojedynczemu blokowi (rekord fizyczny)
• problem zamiany rekordów logicznych na rekordy
fizyczne
• fragmentacja wewnętrzna (internal fragmentation)
METODY DOSTĘPU
»dostęp sekwencyjny (sequential access)
»dostęp bezpośredni (direct access)
»dostęp indeksowy (index)
STRUKTURY KATALOGOWE
•
•
•
•
•
katalog jednopoziomowy
katalog dwupoziomowy
struktury drzewiaste
acykliczne grafy katalogów
graf ogólny katalogów
• ochrona
– prawa dostępu
– hasła
ORGANIZACJA SYSTEMU PLIKÓW
urządzenia
sterowanie we/wy
podstawowy system plików
moduł organizacji pliku
logiczny system pliku
ORGANIZACJA PAMIĘCI
POMOCNICZEJ
(metody przydziału miejsca na dysku)
•
•
•
•
system plików zwartych (przydział ciągły)
łańcuch powiązanych bloków (przydział listowy)
mapa plików (tablica alokacji)
bloki indeksów
System plików zwartych
katalog uŜytkownika
bloki pliku
znacznik końca
pliku
WŁAŚCIWOŚCI - ZALETY WADY
• łatwo implementować dostęp swobodny i
sekwencyjny
• trudno uniknąć fragmentacji zewnętrznej
• umoŜliwia najbardziej elastyczną
organizację danych - zniszczenie jednego
bloku powoduje tylko lokalną utratę danych
• odpowiednie do takich zastosowań jak bazy
danych
Łańcuch powiązanych bloków
katalog
uŜytkownika
bloki pliku
EOF
nil
WŁAŚCIWOŚCI - ZALETY WADY
• kilka bajtów, kaŜdego bloku w pliku słuŜy jako
wskaźnik do następnego bloku
• wada - konieczność uzyskania duŜej liczby
dostępów do dysku, zanim znajdzie się koniec
pliku
• dostęp do pliku jest z konieczności sekwencyjny
• metoda ta jest mało elastyczna - skutki
uszkodzenia jednego bloku mogą niespodziewanie
rozszerzyć się na cały system plików
• nie ma fragmentacji zewnętrznej
Mapa plików
katalog uŜytkownika
mapa plików
0
0
1
4
2
5
3
1
4
5
Bloki danych
2
wskaźnik pusty
1
2
3
4
5
WŁAŚCIWOŚCI - WADY ZALETY
• kaŜdy blok na dysku - pozycja w mapie
• bloki nieuŜywane - 0 w tablicy
• uszkodzenie mapy plików moŜe spowodować
powaŜne straty danych - dwie kopie mapy w
róŜnych rejonach dysku, aby w razie awarii
sprzętu nie zniszczyć wszystkich kopii
• znaczny ruch głowic dyskowych
• polepszenie czasu dostępu swobodnego
Bloki indeksów
katalog
uŜytkownika
blok indeksów
bloki pliku
5
5
-1
ewentualny następny
blok indeksów
znacznik końca pliku
WŁAŚCIWOŚCI - WADY ZALETY
• wskaźniki dowiązań do kaŜdego pliku są
pamiętane w odrębnych blokach indeksów na
dysku
• dla duŜego pliku trzeba przeznaczyć kilka bloków
indeksów
• schemat listowy
• indeks wielopoziomowy
• schemat kombinowany
• brak fragmentacji zewnętrznej
• umoŜliwia dostęp bezpośredni
Określając obowiązujący w systemie
rozmiar bloku bierze się pod uwagę
poniŜsze kryteria:
• Strata miejsca z powodu bloków nie zapełnionych
całkowicie, która zwiększa się w miarę zwiększania
rozmiaru bloków (fragmentacja wewnętrzna).
• Strata miejsca związana ze wskaźnikami – im mniejsze
bloki, tym więcej uŜytych wskaźników.
• Jednostki przesyłania danych z urządzeń zewnętrznych
do pamięci głównej - rozmiar bloku powinien być
wielokrotnością tej jednostki.
• Rozmiar obszaru pamięci głównej potrzebny do
wykonania kaŜdej operacji czytania lub pisania
odnoszącej się do pliku.
.
wydajność
• metody przydziału - róŜnice w zapotrzebowaniu na pamięć
i czas dostępu do bloków danych
• przydział ciągły - pobranie danych wymaga 1 kontaktu z
dyskiem ( dostęp sekwencyjny i swobodny)
• przydział listowy - (dostęp do i-tego bloku i operacji
czytania z dysku -- dostęp sekwencyjny)
• struktura pliku - zaleŜna od deklarowanego typu dostępu
• konwersja typu pliku - kopiowanie do nowego pliku o
wymaganym typie
Zarządzanie wolną przestrzenią
Lista wolnych obszarów (free-space list)
–wektor binarny
–lista powiązana
–grupowanie
–zliczanie
Wektor bitowy
Mapa bitowa: 1 blok = 1 bit (0-zajęty 1-wolny)
nr bloku=liczba_bitów_w_słowie x liczba_wyzerowanych_słów +
pozycja_pierwszego_ bitu”1”
• mało wydajne
• tylko dla małych dysków
dysk - 1.4GB blok=512B- mapa bitowa - 310KB
4-blokowe grona - 78KB
Lista powiązana
Wskaźnik do 1-go wolnego bloku - w specjalnym m-cu na dysku oraz
w pamięci
• metoda niewydajna - aby przejrzeć listę - odczyt kaŜdego bloku
( zazwyczaj szukany 1-szy wolny blok)
Grupowanie
w 1-szym wolnym bloku - adresy n wolnych bloków;
ostatni z nich zawiera adresy następnych n wolnych bloków
• umoŜliwia szybkie odnajdywanie większej liczby wolnych bloków
Zliczanie
pozycja wykazu wolnych obszarów:adres dyskowy 1-go wolnego
bloku + licznik kolejnych wolnych bloków
Implementacja katalogu
• Lista liniowa nazw plików ze wskaźnikami do bloków danych
wada - liniowe przeszukiwanie
(lista uporządkowana, B-drzewo)
• Tablica haszowania - funkcja haszowania odwzorowuje nazwę
pliku na wskaźnik na liście liniowej
Efektywność systemu plików
Algorytmy przydziału miejsca i obsługi katalogów
– Wstępny przydział i-węzłów – rozrzucenie ich w strefie dysku
(bloki danych blisko i –węzłów)
– Łączenie bloków w grona; zmienne rozmiary gron
– Rodzaje informacji o plikach (daty dostępu…)
– Rozmiar wskaźników w dostępie do danych 16b – 64kB;
32b-4GB
– Struktury jądra przydzielane dynamicznie (rozmiar tablicy
otwartych plików, tablicy procesów)
Wydajność systemu plików
(pamięć)
• Sprzętowe sterowniki dyskowe – pamięć podręczna
„na płycie” – czytanie całej ścieŜki
• disk cache – pamięć podręczna bloków dyskowych
w PAO; /cała wolna pamięć pulą buforów/
– Optymalizacja (dostęp sekwencyjny):
• wczesne zwalnianie
• czytanie z wyprzedzeniem
– Kontrolowana przez SO
• Komputery PC - RAM-dysk
– Kontrolowane przez uŜytkownika
INTEGRALNOŚĆ SYSTEMU
PLIKÓW
• sprawdzanie spójności (chkdsk, fsck; e2fsck)
• mechanizmy archiwizowania i odtwarzania danych
archiwizowanych - awarie sprzętu lub błędu w
oprogramowaniu.
• główne metody sporządzania kopii zapasowych
plików:
– okresowe składowanie zawartości pamięci
– składowanie przyrostowe
UNIX
VFS – Virtual File System
Te same funkcje systemowe – dostęp do kaŜdego pliku na dowolnym
systemie plikowym
Zaprojektowany na zasadach obiektowych:
• Definicje obiektów
• Oprogramowanie do działań na nich
4.2 BSD – FFS (Fast File System) – dwa rozmiary bloków:
8kB, fragment – n*1kB
wersja 7 Unix- katalog – wykaz: 14B – nazwa pliku + 2B – nr i-noda
4.3BSD – wpisy katalogowe zmiennej długości:
– długość
– nazwa
– nr i-węzła
• Pamięć podręczna naw katalogów (pamiętane są i -węzły)
wywołanie systemowe:
czytaj(4,….) / przestrzeń uŜytkownika
deskrytptor pliku
topp
tsp
lista i-węzłów w PAO /
przestrzeń systemu
bloki danych /przestrzeń dysku
topp – tablica otwartych plików procesu
tsp – tablica struktur plików
Lista i-węzłów w PAO <==> lista i-węzłów z dysku
Identyfikacja pliku przez jądro: ( nr urządzenia log., nr i-węzła)
Nr urządzenia log. – określa system plików (własny superblok; w
PAO; synchronizowany co 30 sec)
4.2 BSD – grupa cylindrów ( 1 lub więcej sąsiadujących
cylindrów)
• inf. nagłówkowe (superblok, i-węzły, blok opisu
cylindrów)- w róŜnych odległościach od początku grupy;
na róŜnych płytach dysku
• i-węzeł pliku – w tej samej grupie cylindrów co i-węzeł
katalogu (ls z opcjami odwołuje się do i –nod’ów)
• i-węzeł nowego katalogu – w innej grupie cylindrów (z
duŜą liczbą wolnych i-węzłów)
• bloki przydzielane plikom w obrębie tej samej grupy
cylindrów (małe pliki – minimalny ruch głowic)
FFS – 30% technicznej przepustowości dysku
wersja 7 – 3%
Linux
• Minix (nazwy 14-znakowe; max. rozmiar plik 64MB)
• ext2 – FFS (Second Extended File System - 1993)
– bloki w pliku katalogowym – powiązana lista wpisów
• długość wpisu
• nazwa pliku
• nr i-węzła
– nie uŜywa bloków cząstkowych ( fragmentów)
– mniejsze bloki (1, 2, 4kB)
– operowanie gronami (1 op. we/wy dotyczy kilku bloków;
logicznie sąsiadujące bloki pliku – przylegające bloki dyskowe)
– wiele grup bloków
– obsługa „dziurawych” plików
Linux
• blokom danych przydzielana ta grupa bloków, do której
naleŜy i-węzeł pliku
• i-węzły plików zwykłych - w grupie katalogu
macierzystego
• pliki katalogowe – rozproszone
• wewnątrz grup – przydziały ciągłe ( minimalizacja
fragmentacji)
• występuje mapa bitowa wolnych bloków w grupie –
szukanie miejsca dla pliku:
– tworzony nowy plik – od początku grupy bloków
– rozszerzanie pliku – od bloku przydzielonego ostatnio
Linux
Szukanie 2-etapowe
•
Całego wolnego bajta w mapie bitowej
Przydział miejsca porcjami 8-blokowymi; po znalezieniu
bajta w bitmapie – przeszukiwanie wstecz dla uniknięcia
dziur;
wstępnie przydziela się 8 bloków; przy zamykaniu pliku
odznacza się niezajęte bloki
•
Pojedynczych wolnych bitów ( jeśli 1 się nie powiedzie)
blisko początku miejsca szukania
System plików w Linuksie
Grupa 1 Grupa 2
Grupa 3
Grupa n
superblok Deskryptory Bitmapa Bitmapa tablica Bloki
grup
bloków i-węzłów i-węzłów danych
superblok, deskryptory grup – w
kaŜdej grupie lub 0,1 [3 5 7]n
Superblok (ext2_super_block)
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
liczba i-węzłów na dysku
liczba wolnych i-węzłów
liczba bloków na dysku
liczba wolnych bloków dyskowych
liczba zarezerwowanych bloków dyskowych
pierwszy blok z danymi
rozmiar bloku
rozmiar fragmentu
liczba bloków, fragmentów i i-węzłów w grupie
czas ostatniego zamontowania, zapisu na dysk, sprawdzenia
maksymalna liczba zamontowań, liczba aktualnych zamontowań
rozmiar struktury i-węzła
pierwszy niezajęty węzeł
domyślny identyfikator uŜytkownika dla bloków zarezerwowanych
domyślny identyfikator grupy dla bloków zarezerwowanych
Deskryptory grup
• Tablica rekordów opisujących poszczególne
grupy
• 1 rekord: liczba wolnych i-węzłów, liczba
wolnych bloków
• UŜywane podczas przydzielania bloków
System plików w Linuksie
•
•
•
•
•
System plików jest podzielony na grupy
KaŜda grupa ma określoną wielkość (8MB -128MB) za
wyjątkiem ostatniej
Mapa bitowa zajętości bloków ma wielkość jednego
bloku
Mapa bitowa zajętości i-węzłów - ma wielkość jednego
bloku -dla kaŜdego i-węzła jest przydzielony jeden bit
Plik w Linuxie jest identyfikowany za pomocą i-węzła.
To właśnie w i-węźle przechowywane są wszystkie
informacje o pliku
KATALOGI
• katalog w Linuksie jest takŜe plikiem
• jego wewnętrzna reprezentacja danych jest uporządkowana
• kaŜda pozycja w katalogu składa się z:
–
–
–
–
numeru i-węzła
długości pozycji katalogowej
długości nazwy
samej nazwy (do 255 znaków)….typ
• lista jednokierunkowa -> tablice haszujące
• katalog posiada prawa dostępu, lecz ich interpretacja róŜni
się od praw dostępu dla zwykłych plików
–
–
–
prawo r pozwala wyświetlać zawartość katalogu (ls)
prawo w pozwala tworzyć i usuwać pozycje w katalogu
prawo x pozwala na wejście do danego katalogu (cd), dostęp do
plików z tego katalogu, ls –s…..
ext3
• 1999r – RedHat, Stephan Tweedie
• kompatybilny z ext2
• usprawnienia
– mechanizm księgowania
– indeksowane katalogi
• struktura ext3_dir_entry – pole file_type (8 bitów)
journaling
• Mechanizm niezaleŜny od ext3 –interfejs JBD
(Journaling Block Device)
• Dodatkowe pola w superbloku:
– numer i-węzła pliku księgującego (.journal)
– urządzenie
• Zapis całych fizycznych bloków do dziennika
• MoŜliwość księgowania wszystkich danych – tryby
działania:
– writeback - metadane
– journal – metadane i dane
– ordered - metadane; transakcje: po zapisaniu danych na dysk
metadane zapisywane do dziennika
journaling
1. Umieszczenie modyfikowanych bloków w
buforach
2. Łączenie buforów – transakcje
3. Zatwierdzenie transakcji; zapis do
dziennika
4. Zapis na dysk zmodyfikowanych bloków
5. Zakończenie transakcji
Indeksowane katalogi
• bloki 0..511 katalogu – struktura indeksująca
– blok 0 – korzeń drzewa + nagłówek
– blok indeksujący: 512 wpisów(klucz, adres)
klucz – wynik fcji haszującej + znak kolizji;
adres – logiczny adres bloku danych lub kolejnej struktury
indeksującej
• 90000 plików w katalogu ; kolejny poziom ->
50mln. wpisów
• Zwiększenie wydajności; koszty – 2MB – na strukturę
-> indeksowanie – tylko dla duŜej ilości wpisów w katalogu
Szukanie pliku
• obliczenie klucza na pdst. nazwy pliku –
fcja haszująca
• odczyt korzenia struktury indeksującej
• przeszukiwanie indeksów (liniowe; binarne)
• odczyt liścia….
• w przypadku kolizji – przeszukiwanie
kolejnych bloków indeksujących
wstawianie pliku
• w przypadku pełnego bloku wymaga
rozbijania ( podział kluczy na dwa bloki; po
posortowaniu)
• w przypadku kolizji kluczy – wpis w tym
samym bloku o ile to moŜliwe; w
przeciwnym wypadku – zaznaczenie
najmniej znaczącego bita w kluczu =>
szukanie w kolejnym bloku
NTFS
•
•
•
•
Tom (volume) – podst. jednostka
Operowanie gronami (2n przyległych sektorów)
Adres dyskowy=LCN (logical cluster number)
Plik – obiekt strukturalny, złoŜony z atrybutów
– KaŜdy atrybut – niezaleŜny strumień bajtów
– Atrybuty standardowe dla wszystkich plików: nazwa;
czas utworzenia; deskryptor bezpieczeństwa; liczba
dowiązań; beznazwowy atrybut danych
MFT – Master File Table
•
•
•
•
KaŜdy plik opisany min. 1 rekordem
Rozmiar rekordu – parametr systemu (1-4kB)
Małe atrybuty – rezydentne w MFT
Wielkie atrybuty – przechowywane w rozszerzeniach na dysku;
wskaźniki do nich w rekordzie MFT
• Pliki o wielu atrybutach – podstawowy rekord pliku ( base file record)
+ wskaźniki do rekordów nadmiarowych
• kaŜdy plik ma 64-bitowy identyfikator (file reference);
48 bitów – nr rek. w MFT
16 bitów – nr kolejny (inkrementowany przy
powtórnym uŜyciu wpisu w MFT)
• struktura katalogów – B+ drzewo; kaŜdy wpis – nazwa pliku, odsyłacz,
znacznik czasu utworzenia, rozmiar (z MTFS)
Pliki metadanych
•
•
•
•
•
•
•
•
•
•
•
Tablica MFT
MftMirr – kopia metadanych (pierwsze 16 pozycji)
LogFile – plik dziennika transakcji
Volume – inf. o wolumenie (nazwa, wersja NTFS)
AttrDef – tablica definicji atrybutów
. – katalog główny
Bitmap – plik bitmapy klastrów (gron)
Boot – plik inicjacyjny
BadClus – lista złych klastrów (gron)
Quota – ograniczenia
Upcase – tablica konwersji małych liter na duŜe
ODPORNOŚĆ - TRANSAKCJE
• Dla zapewnienia integralności systemu
plików (struktury danych systemowych)
• KaŜda zmiana w systemie plików + inf. o
pomyślności zakończenia – zapisywana w
pliku logu (umoŜliwia powtórzenie lub
anulowanie operacji)
• Po awarii przetwarzanie zapisów dziennika
• Okresowo – zapis do dziennika punktów
kontrolnych – (chekpoint)
Bezpieczeństwo
• Schemat lazy write – operacje na dysku wykonywane w
pamięci podręcznej
• Sterowanie dowolnym dostępem
DAC (discretionary access control)
Szczegółowe określenie pozwoleń i zakazów dostępu
Full control – RWXDPO
Change – RWXD
Read – RX
NoAccess
– -
plik
katalog
R
oglądanie zawartości
pokazywanie plików z katalogu
W
zmiana, usunięcie zawartości
dodawanie elementu do katalogu
X
uruchomienie pliku wykonywalnego
cd
D
usuwanie pliku
usuwanie katalogu (pustego)
P
zmiana praw dostepu
zmiana praw dostepu
O
otrzymanie własności
otrzymanie własności
Zarządzanie tomem (wolumenem) - 1
Łączenie wielu partycji – tom logiczny
(do 32 stref fizycznych – partycji dysków,
dysków)
Mechanizm LCN
2.5GB
2.5GB
C
D
D
LCN numery
0 - 128000
LCN numery
128000 - 783361
C – FAT – 2GB
D – NTFS – 3GB
Zarządzanie tomem (wolumenem) - 2
System plików ze strippingiem
Schemat RAID poziomu 0 – paskowanie dysku
Redundant Array of Independent Disks
FtDisk – paski 64kB
Kolejne paski przydzielane kolejnym strefom fizycznym
Zbiór pasków – 1 tom logiczny
Równoległe operacje we/wy - polepszenie przepustowości we/wy
(duŜe pliki !!!)
Napęd logiczny C: 4GB
LCN
Dysk 1
2GB
Dysk 2
2GB
0 -15
16 - 31
32 - 47
48 - 63
64 - 79
80 - 95
•poszczególne dyski – oddzielne kontrolery
•partycje do strippingu – podobny rozmiar
•dyski nie powinny być uŜywane do innych celów
•powszechnie 2 – 4 partycje (teoretycznie do 32)
Zarządzanie tomem (wolumenem) - 3
•
•
•
•
Zbiór pasków z parzystością
RAID 5
Odporność na uszkodzenia
Kolejne porcje danych na kolejnych dyskach + dane
o parzystości (XOR) krąŜą po dyskach zestawu
Przy uszkodzeniu paska – moŜliwość
zrekonstruowania danych
Min. 3 jednakowe strefy na 3 dyskach
Napęd logiczny C: 4GB
LCN
Dysk 1
2GB
Dysk 2
2GB
Dysk 3
2GB
P
0 - 15
16 - 31
32 - 47
P
48 - 63
64 - 79
80 - 95
P
P
96 111
112 - 127
128 - 143
P
144 -159
Zarządzanie tomem (wolumenem) - 4
Dyski lustrzane DISK MIRRORING
RAID 1
•
•
•
•
2 identyczne strefy na 2 dyskach
Polepszenie bezpieczeństwa
Przyspieszenie we/wy
Oba dyski – osobne sterowniki (duplex set)
Kopia C: 2GB
C: 2GB
• NT programowo implementuje RAID 0, 1, 5
• Zapas sektorów (sector sparing)
Część sektorów nie jest ujęta w mapie dobrych sektorów rezerwa uŜyta w razie awarii ( wtórne odwzorowanie grona –
cluster remapping)
• Upakowanie
automatyczna kompresja plików; NTFS dzieli plik do
kompresji na jednostki upakowania złoŜone z 16 kolejnych
gron
pliki rozrzedzone - grona zawierające same 0 ; system nie
przydziela im miejsca na dysku (przerwy w nr gron wirtualnych);
podczas czytania – uzupełnienie 0 w buforze