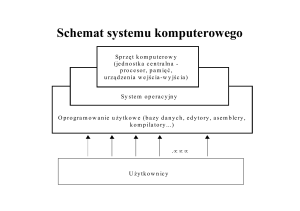
Wstęp
System plików opisuje metody oraz struktury danych, które używane są przez system operacyjny
celem zapisywania informacji o plikach oraz ich zawartościach na odpowiedniej partycji. Innymi
słowy, jest on sposobem organizacji plików na dysku. Terminu tego używa się także, jeśli chodzi
mamy na myśli daną partycję, czy dysk, może być on, zatem mylący. Różnice pomiędzy dyskiem
twardym, partycją, a systemem plików są bardzo istotne. Niektóre programy pracują opierając się o
sektory dysku twardego, są to najczęściej programy, które tworzą systemy plików. Jeżeli w polu
działania tych programów znajdzie się jakiś system plików, może on ulec uszkodzeniu lub może
zostać całkowicie wymazany. Większość spotykanych programów pracuje w oparciu o istniejący
na danej partycji określony system plików, programy te nie są w stanie pracować na partycjach
zawierających dość egzotyczne systemy plików, albo na partycjach zawierających błędy
w systemie plików. Zanim użyjemy danej partycji albo dysku twardego jako system plików, należy
go odpowiednio przygotować do tego zadania tworząc właściwe struktury. Cały proces
przygotowywania jest nazywany tworzeniem systemu plików.
Większa część systemu plików, która jest używana przez systemy oparte na jądrze Unixowym jest
bardzo podobna do siebie zarówno pod względem budowy jak i funkcjonalnie. Poszczególne
partycje Unikowe często różnią się od siebie szczegółami. Do wspólnych pomysłów, które
wykorzystywane są w każdym systemie należą i-węzeł, superblok, blok danych, blok pośredni oraz
blok katalogu. W superbloku zawarte są informacje dotyczące systemu jako całości, na przykład
znajdziemy tam informacje o rozmiarze, którego wartość dokładna zależy właśnie od użytego
systemu plików. I-węzeł posiada wszelkie informacje o danym pliku, poza jego nazwą. Nazwa pliku
jest przechowywana w katalogu, wraz z numerem odpowiedniego i-węzła. Wpisy w katalogu
zawierają liczbę i-węzłów plików oraz nazwę. W i-węźle przechowywane są numery bloków
danych, w których zawarty jest dany plik. Dzięki automatycznej alokacji miejsca mamy możliwość
przechowywania tylko niewielkiej liczby numerów, gdy jednak zajdzie taka potrzeba dodatkowa
przestrzeń zostanie alokowana dynamicznie. Bloki alokowane w sposób dynamiczny nazywane
są bezpośrednimi. Aby znaleźć określony numer bloku danych trzeba znaleźć pierwszy pośredni
blok.
Unixowe systemy plików pozwalają zazwyczaj na tworzenie dziur w plikach, które tworzone są przy
pomocy Iseek. Tworzenie dziur polega na tym, że system udaje, że na danym miejscu występuje
zero, jednak nie zajmuje ono żadnej przestrzeni dyskowej. Do sytuacji takiej często dochodzi, jeżeli
mamy do czynienia z niewielkimi binariami, bazami danych oraz bibliotekami dzielonymi Linuxa.
Dziury są przechowywane przez celowe zapisanie odpowiednich wartości w polu i-węzła
lub adresu bloku pośredniego. Adres ten oznacza, że w danym pliku znajduje się dziura. Dziury
pełnią całkiem pożyteczną funkcję, przykładowo dzięki użyciu dziur rozmiar tych samych plików
na dysku zmniejszył się, w stosunku do pierwotnej wielkości 100MB, o 2MB. Przykładowy system
zawierał niewielką ilość programów oraz nie zawierał baz danych.
Ext2
Ext2 jest skrótem od nazwy Second Extended File System, co po Polsku oznacza drugi
rozszerzony system plików. Autorem pierwszej wersji tego systemu plików był Remy Card
związany z Universite Pierre et Marie Curie w Paryżu. Wersja alfa tego systemu, którą wspomniany
człowiek stworzył w styczniu roku 1993, powstała jako zwykłe rozszerzenie systemu plików Extfs,
który miał być następcą pierwszego systemu plików zastosowanego w Linuxie - Minixa. W obecnej
chwili Ext2 stał się najczęściej używanym systemem plików w systemie Linux. Jeszcze
do niedawna Ext2 był domyślnym systemem plików w wielu dystrybucjach Linuxa. System Ext2
zaprojektowano, uwzględniając możliwość rozszerzenia jego funkcjonalności w przyszłości wraz
z zachowaniem
wstecznej
kompatybilności,
z czego
na pewno
korzystały osoby,
które
są odpowiedzialne za rozwój tego systemu. Efektem prac nad Ext2 jest powstanie wielu
rozszerzeń oraz niewielkich usprawnień.
Zalety systemu Ext2:
Wsparcie dla wszystkich elementów Unixowych systemów plików, takich jak pliki specjalne, prawa dostępu,
dowiązania symboliczne.
Wysoka wydajność, która zapewniana jest dzięki mechanizmowi przeciwdziałającemu fragmentacji danych
- jest to możliwe dzięki przydzielaniu bliskich bloków oraz dzięki prealokacji.
Wydajny mechanizm dowiązań symbolicznych.
Jest to system dobrze przetestowany i stabilny, tak samo solidny jest program używany do naprawiania tego
systemu noszący nazwę e2fsck.
Odpowiednio zdefiniowany sposób na dodawanie rozszerzeń.
Jest niezależny od systemu operacyjnego, który jest na nim zainstalowany - każde pole wielobajtowe
zapisane jest w standardzie Littre - endian.
Rozmiar maksymalny pojedynczej partycji wynosi 4TB, natomiast rozmiar maksymalny pojedynczego pliku
jest równy 2GB. Plik może mieć nazwę o maksymalnej długości wynoszącej 255 znaków.
Obsługuje dziurawe pliki, w których bloki nieużywane nie zostaną przydzielone.
Możliwość automatycznego sprawdzenia systemu w wyniku stwierdzenia awarii lub, co jakiś czas.
Wady systemu Ext2:
Niewielka efektywność obsługi katalogów, chociaż dzięki użyciu pamięci podręcznej może ona ulec
znacznej poprawie.
Niska wydajność w przypadku dużej ilości bardzo małych plików, rzędu kilkuset bajtów. Dostęp do nich jest
stosunkowo wolny, a alokacja pociąga za sobą duże straty.
W przypadku nieprawidłowego zamknięcia systemu sprawdzenie systemu plików trwa bardzo długo.
Partycja, która sformatowana jest w systemie plików Ext2 może być podzielona na bloki
o rozmiarach 1024, 2048 albo 4096 bajtów. Niektóre architektury umożliwiają zastosowanie
rozmiaru bloku nawet 8192 - bajtowego. Kolejne bloki są połączone ze sobą w grupy, których
rozmiar jest zależny od odpowiednio wybranego rozmiaru bloku. Dzięki podziałowi na grupy
zwiększona jest lokalność danych mająca związek z pojedynczym plikiem, a więc przyspieszony
jest dostęp do nich. Podczas tworzenia systemu plików grupy ustalane są statycznie. Oryginalna
wersja Ext2 wymagała, aby w każdej grupie znalazł się superblok, który opisywałby cały system
plików, a także deskryptory grup, które opisywałyby sumaryczne dane o wszystkich grupach.
Rozwiązanie takie miało na celu przyspieszenie dostępu do informacji oraz miało zabezpieczyć
istotne dane przed awarią dysku. Nowsze wersje systemu przyniosły ze sobą możliwość pomijania
kopii w niektórych grupach, zmniejszając w ten sposób ilość marnowanego miejsca na dysku.
W nowym rozwiązaniu kopie superbloków oraz deskryptorów grup znajdują się jedynie w blokach
o numerach 0,1, a także w tych będących potęgami liczb 3,5 i 7. Oprócz superblok i deskryptorów
grup, które są identyczne w strukturze całego dysku, w skład każdej grupy wchodzą:
Bitowa mapa bloków - zajmuje ona pojedynczy blok, którego każdy bit odpowiada pojedynczemu blokowi
danej grupy. Ustawiony bit oznacza, że dany blok jest zajęty.
Bitowa mapa i-węzłów, która opisuje zajętość i-węzłów w ramach danej grupy.
Tablica i-węzłów, którą tworzą bloki, w ramach, których są przydzielane metryki plików - i-węzły. Ilość iwęzłów w danej grupie jest ustalana statycznie w czasie tworzenia systemu plików.
Autorom systemu Ext2 przyświecało stworzenie bezpiecznego i solidnego systemu, który
jednocześnie byłby bardzo szybki. Aby osiągnąć ten cel, zrezygnowano ze stosowania jako
struktur danych b-drzew. Powołując się na autorów skutki awarii w momencie operacji
równoważenia drzewa byłyby bardzo trudne do naprawienia. Ext2 posiada cechy, które
w znacznym stopniu ułatwiają okresową kontrolę poprawności tego systemu oraz dokładność jego
naprawy po stwierdzeniu awarii. System plików Ext2 umieszcza w superblok specjalną sygnaturę,
która określa, czy system prawidłowo domontowano. Dzięki tej sygnaturze, podczas ładowania
systemu operacyjnego istnieje możliwość sprawdzenia, czy system plików na danej partycji
wymaga sprawdzenia, czy wymontowano go poprawne i istnieje pełna spójność danych. Ext2
przechowuje również w superblok daty ostatnich sprawdzeń systemu plików, a także ilość
montowań, które upłynęły od ostatniego sprawdzenia. Można wymusić sprawdzanie automatyczne
poprawności danego systemu plików, co pewną liczbę montowań. W tym celu należy odpowiednio
ustawić wartość pola s_max_mnt_count znajdującego się w superblok. Stała domyślna
EXT2_DFL_MAX_MNT_COUNT jest równa 20. Sprawdzanie poprawności może również
być zautomatyzowane pod względem czasu. Aby system był sprawdzany, co interesujący
nas okres czasu, wystarczy ustawić odpowiednią wartość w polu s_checkinterval należącym
do superbloku, domyślnie opcja ta jest wyłączona.
Ext3
Trzeci rozszerzony format plików wziął swój początek od formatu Ext2. Stworzył go w roku 1999
Stephen Tweedie pracując nad dystrybucją Red Hat. Podstawową cechą, która różni te dwa
systemy plików jest użyty mechanizm księgowania, zwany journalingiem. Wprowadzono go, aby
skrócić czas wstawania systemu po zaistniałej awarii. Oprócz tego wprowadzonych zostało kilka
istotnych usprawnień, które wcześniej były dostępne jako łaty przeznaczone dla systemu plików
Ext2. Mając na uwadze, że system ten zawiera prawie wszystkie cechy swojego poprzednika,
warto wyróżnić dodatkowe możliwości, jakie stwarza stosowanie Ext3:
Mechanizm journalingu, czyli mechanizmu księgowania, który zwiększa bezpieczeństwo całego systemu
dzięki niepodzielności informacji. Jego główną zaletą jest znaczne skrócenie czasu sprawdzania systemu
plików po niepoprawnym domontowaniu.
Indeksowanie katalogów, które w znaczny sposób zwiększa wydajność systemu plików przy dużej ich ilości.
Synchroniczny zapis, który działa w najnowszych wersjach systemu plików Ext3 nawet ponad 10 razy
szybciej, w stosunku do zapisu z systemu Ext2. Dotyczy to zapisu do plików zwykłych.
Celem przyświecającym autorowi systemu Ext3 było nie tworzenie go od nowa, tylko jak najlepsze
usprawnienie systemu plików Ext2. Dzięki takiemu potraktowaniu sprawy warto wymienić zalety,
jakie zyskali dzięki temu użytkownicy Linuxa:
Można montować system Ext3 jako system Ext2, o ile został one w poprawny sposób domontowany.
Na dzień dzisiejszy nie ma jeszcze możliwości montowania systemu Ext2 jako systemu Ext3, jednak opcja
ta ma być udostępniona w najbliższej przyszłości.
Można korzystać z dużej ilości programów narzędziowych sprawdzonych w przypadku systemu plików
Ext2, przykładem tutaj jest chociażby program fcsk.
Istnieje możliwość bezpiecznej oraz łatwej migracji z systemu plików Ext2 do systemu Ext3 przy pomocy
programu o nazwie tune. Operacja taka nie wymaga nawet odmontowania partycji z określonym systemem
plików na czas konwersji.
Stabilność, przewidywalność oraz uniknięcie wielu błędów.
Zaufanie szerokiego grona użytkowników.
Jeszcze do niedawna Ext2 był podstawowym systemem plików używanym w stacjach roboczych.
Wybierano go również jako system plików serwerowych, główne ze względu na jego wysoką
stabilność, odpowiedni pakiet narzędziowy oraz długą obecność na rynku. Był on z powodzeniem
wykorzystywany na bardzo dużych serwerach obsługujących w danej chwili ogromne ilości
informacji. Z biegiem czasu użytkownikom korzystającym z tego systemu plików zaczął doskwierać
brak journalingu a także niska wydajność w przypadku dużej ilości plików, których to wad
nie posiadały nowo powstałe systemy plików. Ext3 uznaje się za ewolucyjne rozwinięcie systemu
plików Ext2, które oferuje renomę oraz stabilność poprzednika a także garść cech dodatkowych,
pozwalających umieścić go w gronie nowoczesnych systemów plików. Ext3 na dzień dzisiejszy
wydaje się być idealnym systemem plików przeznaczonym dla stacji roboczych oraz domowych
komputerów. Opinię tę propaguje firma RedHat, która używa Ext3 jako domyślnego systemu plików
w swojej dystrybucji Linuxa. Gwarantem ciągłego wsparcia firmy RedHat dla systemu Ext3 jest fakt,
że sam autor tego systemu pracuje w tej firmie. Biorąc pod uwagę indeksowanie katalogów oraz
wydajny i stabilny mechanizm księgowania, system Ext3 poleca się również jako system plików
przeznaczony dla serwerów. Na dzień
dzisiejszy system
Ext3
nie jest wykorzystywany
w następujących zastosowaniach:
W serwerach
pocztowych,
ponieważ
wymagają
one bardzo
szybkiego
synchronicznego
zapisu
w odpowiednich strukturach katalogowych, którego mechanizmu system plików Ext3 jeszcze w pełni
nie wspiera.
W serwerach operujących na dużej ilości małych plików, w których wykorzystuje się systemy plików takie
jak reiserfs oraz xfs. Dzieje się tak dlatego, że cechują się one większą wydajnością oraz lepszym
wykorzystaniem przestrzeni dyskowej. Dzięki słabej skalowalności idealnie nadają się one jako systemy
plików do bardzo szybkich serwerów.
NFS
Skrót NFS wziął się od angielskiego terminu Network File System, co oznacza Sieciowy System
Plików. Umożliwia on współdzielenie katalogów oraz plików przez różnych użytkowników
znajdujących się w obrębie jednej sieci. Dzięki systemowi NFS mamy możliwość dostępu
do katalogów oraz plików znajdujących się w sieci na takich samych zasadach jakbyśmy pracowali
na systemie plików znajdującym się na dysku twardym naszego komputera. Do najważniejszych
zalet systemu NFS należą:
W przypadku, gdy współdzielone dane mogą być pobierane przez sieć z określonego serwera, stacje robocze
znacznie oszczędzają na zajętości swojej przestrzeni dyskowej.
Nie ma potrzeby, aby każdy z użytkowników miał osobny katalog domowy na każdej z maszyn znajdujących
się w sieci, jeśli zechce pracować na innej z nich. Katalog home może zostać ustawiony na serwerze
z systemem plików NFS, dzięki czemu stanie się on osiągalny przez sieć lokalną.
Również urządzenia służące do archiwizacji danych, jak pamięci typu FLASH, napędy CD-ROM oraz DVDROM, mogą być z powodzeniem współdzielone przez inne maszyny znajdujące się w sieci. Dzięki takiemu
rozwiązaniu możliwa jest redukcja wymiennych napędów znajdujących się w sieci.
System plików NFS składa się, co najmniej z dwóch części: jednej stacji klienckiej oraz serwera.
Poszczególni klienci mają swobodny dostęp do plików przechowywanych na serwerze. Aby było
to możliwe do wykonania w rzeczywistości niezbędnym staje się uruchomienie następujących
procesów:
nfsd - jest to demon, który obsługuje zapytania pochodzące od klientów systemu NFS.
mountd - jest to demon montujący system plików NFS, który troszczy się o przesyłane do niego zapytania.
portmap - demon mapujący porty, za pomocą którego klient NFS może sprawdzić, który port serwera
używany jest przez system plików NFS.
Klient również posiada możliwość uruchomienia demona związanego z system NFS. Nazywa
się on nfsiod i używany jest do obsługi zapytań przychodzących z serwera NFS. Chociaż
uruchomienie nfsiod nie jest konieczne, uzyskuje się przy nim lepsze osiągi.
System plików NFS posiada wiele praktycznych zastosowań. Niektóre z nich zostały opisanych
poniżej:
Można ustawić kilka maszyn tak, by współdzieliły się ze sobą napędem DVD lub innym nośnikiem
informacji. Jest to o wiele tańsza metoda od metod tradycyjnych. Pomaga ona zainstalować oprogramowanie
na większej ilości komputerów jednocześnie.
W przypadku dużych sieci, rozsądnym rozwiązaniem może stać się skonfigurowanie serwera NFS oraz
umieszczenie w nim katalogów /home. Dzięki temu poszczególni użytkownicy będą mieli cały czas ten sam
katalog /home, niezależnie od tego, z którego komputera zalogują się do systemu.
Większa ilość maszyn może posiadać współdzielony katalog /usr/ports/distfiles. Dzięki takiemu rozwiązaniu
nie trzeba wielokrotnie pobierać pliki z Internetu w momencie, gdy chcemy zainstalować to samo
oprogramowanie na większej ilości maszyn.
ISO 9660
ISO 9660 jest ogólnie przyjętym, międzynarodowym standardem zapisu danych cyfrowych
na płycie CD. Płyty nagrane przy użyciu tego systemu mogą być bez przeszkód odczytane
na każdej
platformie
sprzętowej.
Przykładowo,
aby sprawdzić
czy nasz
Mac obsługuje
ten standard wystarczy znaleźć w folderze System:Extensions, przy pomocy Command-I pozycję
ISO 9660 File Access. Jeżeli zobaczymy wersję 5.0 lub wyższą, nasz system powinien
bez problemu odczytać płytę nagraną w standardzie ISO 9660. Definicja opisywanego standardu
zawiera trzy różne metody zapisu danych na płytach CD. Są to tak zwane poziomy:
Poziom1, który w największym stopniu ogranicza dowolność zapisu informacji. Wymaga on, aby każdy plik
był zapisany jako ciąg bajtów bezpośrednio po sobie następujących. Żaden plik nie może zostać podzielony,
a nazwa pliku i katalogu może składać się maksymalnie z 8 znaków nazwy i 3 znaków rozszerzenia.
Maksymalna dopuszczalna głębokość katalogu wraz z podkatalogami wynosi 8.
Poziom 2, którego jedyne wymaganie dotyczy konieczności zapisu plików jako jednego ciągu bajtów
bezpośrednio po sobie następujących. Płyty, które są nagrane w standardzie drugiego poziomu mogą
być nieczytelne w niektórych systemach, na przykład w starszych wersjach systemu MS-DOS.
Poziom 3, z którym nie wiążą się żadne ograniczenia dotyczące dowolności zapisu fizycznego danych
na płycie. Jest on użyteczny w przypadku nagrywania pakietowego, głównie ze względu na brak
ograniczenia dotyczącego fragmentacji plików.
ReiserFS
ReiserFS to system plików tworzony na zasadzie open - source dla systemu operacyjnego Linux.
Nie byłby on w stanie rozwinąć się do takiego stopnia zaawansowania jak obecnie, gdyby
nie wsparcie wielu firm informatycznych. Przy tworzeniu tego systemu jego autorom towarzyszyło
założenie stworzenia systemu plików bardzo efektywnego, który można byłoby wykorzystywać,
tak w stacjach roboczych, jak i na serwerach.
Do podstawowych cech ReiserFS należą:
Fast journaling - dzięki czemu minimalizowany jest czas sprawdzania integralności dysku, który musi
być dokonany po każdym nieprawidłowym odmontowaniu danej partycji.
Użycie szybkich zbalansowanych drzew, dzięki czemu poprawiona jest efektywność korzystania
z katalogów zawierających bardzo duże ilości plików.
Efektywność w wykorzystaniu miejsca, polegająca na upchaniu dużej ilości małych plików w ramach
jednego bloku.
Kwestia wyrównania plików do granic poszczególnych bloków pociąga za sobą następujące efekty:
Minimalizacji ulega liczba bloków przeznaczona dla jednego pliku, co jest zaletą szczególnie docenianą, jeśli
chodzi o duże pliki, do których odwoływanie następuje w mało lokalny sposób.
Marnowaniu ulega przestrzeń bufora i dysku, ponieważ przechowywane są bloki całe, nawet te które nie są
do końca zapisane.
Marnowany jest czas operacji wejścia / wyjścia przeznaczony na ściąganie całych bloków, pomimo tego,
że nie muszą być one do końca zapisane.
Zwiększeniu ulega średnia ilość bloków, które są potrzebne do poszczególnych plików w danym katalogu.
Istotna staje się prostota kodu.
System ReiserFS przechowuje nazwy plików, jak i same pliki w zrównoważonym drzewie.
Niewielkie pliki, i-węzły, katalogi oraz końce plików dużych rozmiarów są upakowane w sposób
bardzo efektywny, co zapewnia odejście od wyrównywania każdego pliku do bloku oraz i-węzła
o stałym rozmiarze. Większe pliki są przechowywane w węzłach niesformatowanych, które
są przyłączone do drzewa, bez możliwości przeniesienia w algorytmach balansujących drzewo.
System ReiserFS używa drzew B+. Drzewa B+ różnią się od drzew B- tym, że dane, które są w
nich przechowywane umieszczone są na samym dole drzew, w pojedynczych liściach.
W implementacji tej niewielkie informacje, czyli katalogi, nazwy plików, pliki o małych rozmiarach
oraz ogony większych plików są przechowywane bezpośrednio w liściach, natomiast pliki większe
przechowywane są w gałęziach, znajdujących się pod liśćmi.
Do słabych stron pakowania plików do bloku należą:
W wypadku, gdy ogon pliku urośnie na tyle, aby zająć cały węzeł, zostanie on usunięty z węzła
sformatowanego, a następnie przeniesiony do węzła niesformatowanego. Należy zaznaczyć, że plik
mniejszy od 4 KB sam w sobie stanowi ogon.
Jeżeli ogon będzie mniejszy od całego węzła, to może on zostać podzielony pomiędzy dwa węzły,
co implikuje konieczność przeprowadzenia dwóch operacji dyskowych.
Na skutek separacji ogona od reszty pliku zmniejszeniu może ulec efektywność czytania danego pliku.
Na skutek dodania pojedynczego bajtu do ogona lub pliku, który nie znajduje się na końcu węzła możliwe
staje się przeniesienie w pamięci połowy wielkości węzła. Sytuacja tego typu może się zdarzyć w momencie
niebuforowanego i niestandardowego zapisu do pliku. Standardowe biblioteczne funkcje I-O zapewniają
dostęp buforowany do danych.
Zalety upakowania większej ilości plików w jednym bloku:
Brak jest znaczących różnic w szybkości działania dla bloków różnych rozmiarów.
Operacje wejścia / wyjścia są wykorzystywane z większą efektywnością.
Drzewa zapisane są w blokach, na które podzielony jest dysk. Każdy z bloków należących
do określonego drzewa zaczyna się od pola Block_head. Struktura drzewa zrównoważonego
systemu ReiserFS składa się dokładnie trzech rodzajów węzłów. Są to: formatted nodes - liście,
internal nodes - węzły wewnętrzne oraz unformatted nodes, czyli podliście - węzły występująca
bezpośrednio pod liśćmi. Internal nodes spełniają funkcję wewnętrznych węzłów B-drzewa.
Formatted nodes to liście B-drzewa. Składają się one z items. Wszystkie items zawierają
dodatkowe klucze przydatne do wyszukiwań i które mogą stanowić jeden z rodzajów opisanych
poniżej:
stat data - item zawierający dodatkowe dane dla katalogu lub pliku, które znajdują się zawsze na ich
początku,
direktory item - zawiera on klucz pierwszego directory entry oraz liczbę directory entries,
direct item - zawarte w nim są ogony plików,
indirect item - zawarte w nim są wskaźniki na unformatted nodes, które zawierają dane pliku, lecz poza jego
ogonem.
Aby wstawić nowy węzeł do drzewa należy znaleźć wśród wolnych bloków odpowiednią bitmapę,
począwszy od lewego sąsiada węzła ostatnio używanego, poruszając się w tym kierunku,
co ostatnio. Metoda ta jest o 10% szybsza od metody polegającej na zaczynaniu od aktualnego
węzła, nawet biorąc pod uwagę fakt, że zachodzi ryzyko sięgnięcia po ojca, jeśli okaże się, że nie
znaleziono lewego sąsiada. Testy pokazały, że opisywana metoda jest znacznie lepsza
od poniższych alternatyw:
Wyszukania w bitmapie pierwszego wolnego bloku.
Wzięcia pierwszego węzła znajdującego się za ostatnio przydzielonym oraz poruszanie się w kierunku
tym samym, co ostatnio. Działanie takie daje 3% zysku w przypadku zapisu, lecz 10 - 20% wolniejszy
odczyt.
Rozpoczynania od lewego sąsiada oraz poruszania się w kierunku wziętym od prawego sąsiada.
Porządek, który użyty jest w drzewie ma niezwykle duże znaczenie na wydajność naszego
systemu. Wpływa on w dużym stopniu na lokalność czytania danych oraz na efektywność
w upakowaniu ogonów. Struktura każdego klucza składa się z następujących pól: offset,
uniqueness, locality_id oraz object_id. Pole locality_id wskazuje standardowo na object_id
nadrzędnego katalogu, zapewniając przy tym lokalność. Każdy z katalogów i plików posiada
unikatowy object_id.
Priorytety w optymalizacji zbalansowania drzewa:
minimalizacja liczby węzłów, które poddają się operacji zbalansowania,
minimalizacja liczby użytych węzłów,
jeżeli niezbędne jest przeniesienie do innego formatted node, to priorytetem staje się optymalizacja danych
przenoszonych, ponieważ istnieje dużą szansa na to, że następne operacje dyskowe będą miały miejsce
w tym samym rejonie, robione jest więc miejsce na operacje dyskowe,
minimalizacja liczby węzłów uncached, które poddają się operacji balansowania.
Reiser 4
Nowa wersja systemu, która jest w jeszcze w fazie projektowania będzie zawierać dużą ilość
udoskonaleń, takich jak:
większe bezpieczeństwo,
lepsza wydajność,
system transakcji rozszerzający jeszcze bardziej pojęcie journalingu,
zmiana architektury systemu w kierunku większej obiektowości,
możliwość dołączenia własnych plug - inów, dzięki którym każdy użytkownik będzie w stanie stworzyć,
na przykład abstrakcję katalogu,
wprowadzenie struktury drzew tańczących, która polega na tym, że w trakcie działania systemu dana
struktura drzewa jest zmieniana dopiero przy operacjach commit lub flush, natomiast nie dla każdej
dyskowej operacji,
użycie repackera, czyli specjalnego programu pakującego ogony, dzięki czemu można zaoszczędzić jeszcze
więcej miejsca.
FAT
Skrót FAT pochodzi od File Allocation Table. System plików FAT jest oparty na tablicy, która
opisuje, w którym klastru dysku twardego lub magnetycznej dyskietki system operacyjny powinien
szukać zapisanego na nim pliku. Tablica ta tworzona jest w czasie formatowania danego nośnika
danych. Pierwsze z dwóch rekordów tej tablicy to dane opisujące FAT oraz jego kopię. Kolejne
rekordy odpowiadają za sprecyzowanie położenia danych plików. Każdy z rekordów struktury
odpowiada za prawidłowe opisanie pojedynczego klastra z danymi. W przypadku, gdy dany plik
przekracza rozmiar pojedynczej jednostki alokacji, w polu FAT znajdzie się adres kolejnego
zajętego klastra. Dane, które dotyczą zbiorów umieszczonych w poszczególnych katalogach
są przechowywane w katalogu głównym. Każde pole, które opisuje plik, posiada rozmiar 32 bajtów
i możliwe jest umieszczenie w nim takich informacji jak nazwa pliku, jego atrybuty, rozmiar, data
ostatniej modyfikacji oraz pierwszy klaster. W miarę postępu technologicznego FAT wielokrotnie
unowocześniano, aby osiągnąć możliwie najbardziej efektywną pracę z dyskami o dużych
pojemnościach oraz z bardzo szybkimi komputerami osobistymi.
FAT32
FAT32 jest odmianą systemu plików FAT, z którego korzystają systemy operacyjne takie jak:
Windows 95, Windows 98, a nawet nowsze systemy jak Windows XP. FAT32 umożliwia
prawidłowe rozpoznanie 2 do potęgi 32, czyli 4 294 967 296 adresów jednostek alokacji,
co umożliwia obsługę dysków twardych o pojemności nawet 2 terabajtów. Podczas zapisu plików
na dysk często mamy do czynienia ze stratami pojemności. Dzieje się tak w przypadku zapisu pliku
o pojemności 6kB na dysku o klastrze 32kB, jak w systemie FAT. Strata miejsca wynosi więc
aż 26kB. Na pojedynczy klaster w systemie FAT32 przypada dokładnie 8 sektorów, których łączna
pojemność wynosi 4kB, dla dysków 8GB. Dzięki takiemu rozwiązaniu straty pojemności nie są
duże, przy zapisie pliku 6kB strata pojemności wynosi zaledwie 2kB. Stosując system FAT32
w przypadku dysków o większych pojemnościach nie zachodzi konieczność dzielenia dysku
na mniejsze partycje, jak miało to miejsce w przypadku systemu FAT. Poniższa tabelka
przedstawia zależność wielkości klastra od pojemności dysku używającego systemu plików
FAT32.
Pojemność dysku [GB] Wielkość klastra [KB]
0,5 - 1
4
1-2
4
2-4
4
4-8
4
8-16
8
16-32
16
>32
32
HPFS
Skrót HPFS oznacza High Performance File System i jest systemem plików systemu operacyjnego
OS/2. HPFS zaprojektowały pod koniec lat osiemdziesiątych ubiegłego wieku przez firmy Microsoft
oraz
IBM,
na potrzeby
operacyjnego.
System
powstającego
OS/2
w ówczesnych
początkowo
był tworzony
czasach
przez
nowoczesnego
obie
firmy,
systemu
na początku
lat dziewięćdziesiątych firma Microsoft zdecydowała się porzucić prace nad tym projektem i od
tej pory rozwijaniem systemu zajmuje się IBM. W przeciwieństwie do systemu plików FAT, który
w roku 1977 wymyślono do obsługi dyskietek, system plików HPFS od samego początku
był tworzony z myślą o efektywnej obsłudze dużych dysków twardych. Teoretyczna graniczna
pojemność woluminu obsługiwana przez ten system wynosiła na początku 2199 GB, podzielonych
na 2^32 sektorów 512 bajtowych. Graniczną pojemność w nowszych wersjach tego systemu
jeszcze zwiększono. System ten dzieli przestrzeń dysku twardego na pasma zajmujące po 8
MB, co odpowiada 16384 sektorom 512 bajtowym. Pasma te zawierają bitową mapę zajętości
poszczególnych sektorów w paśmie - 32 sektory. Za sprawą naprzemiennego ułożenia map w
kolejnych pasmach są tworzone odcinki o rozmiarach 16 MB, które rozdziela się mapami dwóch
kolejnych pasm. Jedno z pasm, które położone jest najbliżej geometrycznego środka dysku jest
zarezerwowane na przechowywanie informacji o katalogach, w tym także o katalogu głównym.
Jeżeli pasmo to ulegnie wypełnieniu, nowe katalogi mogą być zakładane w innych miejscach dysku
twardego. Kluczowa dla systemu HPFS struktura danych to Fnode, czyli rekord położony możliwie
jak najbliżej samego pliku, który opisuje jego położenie oraz parametry. Jeżeli nie wystarcza on do
pełnego opisu położenia lub atrybutów rozszerzonych, na dysku są tworzone dodatkowe
pomocnicze struktury. Zawartość poszczególnych katalogów jest odpowiednio posortowana oraz
zapisana w blokach o wielkości 2kB każdy. Tworzą one strukturę sterty, czyli odpowiednio
posortowanego, zrównoważonego drzewa binarnego. Zapewnia to znaczne przyspieszenie
wyszukiwania oraz dostępu do pliku, natomiast spowalnia kasowanie, tworzenie oraz zmianę
nazwy poszczególnych plików, ponieważ wymuszają one niekiedy reorganizację całej struktury
danego katalogu. HPFS pozwala na operowanie długimi nazwami plików, sięgających nawet
256 znaków. Mamy również informację o datach utworzenia danego pliku, ostatniej jego
modyfikacji oraz o ostatnim dostępie do niego. Posiadamy wgląd w prawa dostępu oraz atrybuty
rozszerzone, które umożliwiają przechowanie dowolnej wykorzystywanej przez system plików
informacji, czy też aplikacji. Przykładem takich atrybutów rozszerzonych jest ikona oraz położenie
danego okna na pulpicie. Gromadzone są również informacje statystyczne, które pozwalają
na optymalizację pracy pamięci podręcznej dysku twardego. Przeciwnie do FAT, system plików
HPFS definiuje nie tylko położenie danych na dysku twardym, ale również sposób korzystania
z niego. Zawiera w sobie optymalizację wykorzystania pamięci podręcznej, mechanizmów
minimalizacji fragmentacji plików i tym podobne. Zdefiniowano również liczne mechanizmy, które
chronią przed uszkodzeniami, takie jak: wbudowany CHKDSK, weryfikacja zapisu, automatyczna
kontrola struktury plików na dysku w wypadku wykrycia błędnego zakończenia ostatniej sesji pracy
systemu operacyjnego oraz hotfix, czyli przeniesienie w czasie pracy systemu zawartości sektorów
uszkodzonych do obszaru rezerwowego. Dzięki specjalnym identyfikatorom kluczowych struktur
wewnętrznych danych oraz dzięki dublowaniu wybranych informacji w różnych katalogach, takich
jak początkowe fragmenty nazw plików umieszczonych w katalogu oraz Fnode, możemy
automatycznie odtworzyć strukturę dysku nawet w wypadku ciężkich awarii.