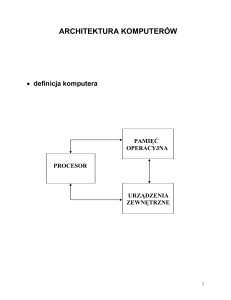
ARCHITEKTURA KOMPUTERÓW
definicja komputera
PAMIĘĆ
OPERACYJNA
PROCESOR
URZĄDZENIA
ZEWNĘTRZNE
PAMIĘĆ OPERACYJNA (PAO)
bezpośrednio dostępna dla procesora
zestaw ponumerowanych komórek
do przechowywania ciągów binarnych
m
0
1
0
. . . .
.
.
.
.
n
. . . .
PROCESOR
procesor : układ, który samoczynnie
realizuje program
program : ciąg poleceń,
które może wykonywać procesor
polecenie → rozkaz, zapisany jako ciąg binarny
program → sekwencja (ciąg) rozkazów
lista rozkazów ( charakteryzuje procesor )
lokalizacja programu : PAO ( von Neumann 1946 )
podstawowy cykl pracy procesora
POBIERZ ROZKAZ
Z PAMIĘCI OPERACYJNEJ
WYKONAJ ROZKAZ
wskazanie rozkazu do wykonania :
licznik rozkazów, wskaźnik rozkazu ( rejestr )
POBIERZ ROZKAZ
Z PAMIĘCI OPERACYJNEJ
WSKAZANY PRZEZ
LICZNIK ROZKAZÓW
ZMIEŃ ZAWARTOŚĆ
LICZNIKA ROZKAZÓW
WYKONAJ ROZKAZ
LR ← LR + 1
LR ← LR + N
Budowa rozkazu
bezargumentowy
KodOp
KodOp
Arg
KodOp
Arg1
1 - argumentowy
Arg2
2 - argumentowy
Arg : liczba, adres PAO, ozn. rejestru procesora
Prosty procesor
Rejestr Rozkazu
KodOp
R
Arg
RR
ARYTMOMETR
Rejestr A
RA
+
-
Rejestr B
RB
Licznik Rozkazów
LR
Wskaźnik Stosu
WS
STEROWANIE
Rejestr Rozkazu
KodOp
R
Arg
• pole KodOp : kod ( numer ) rozkazu
• pole R
: wskazuje RA ( 0 ) albo RB ( 1 )
• pole Arg
: liczba NN albo
adres komórki pamięci AP
Lista rozkazów, mnemoniczne kody rozkazów
rozkazy przesyłania danych
SET
R, NN
MOV R, AP
MOV AP, R
rozkazy arytmetyczne
ADD R, AP
SUB R, AP
INC
R
DEC R
rozkazy skoków
JMP AP
JZ
R, AP
rozkazy wprowadzania - wyprowadzania danych
IN
R, NN
OUT NN, R
postać binarna rozkazu
SET RA, 45H
SET
R
NN
1001
0
0000100 0101
realizacja rozkazu
RR
SET RA, 45H
1. RR ← PAO ( LR )
2. LR ← LR + 1
3. dekodowanie KodOP
4. RA ← RR.Arg
postać binarna rozkazu
ADD
1100
R
1
ADD RB, 5AEH
AP
10110101110
RR
realizacja rozkazu ADD RB, 5AEH
1. RR ← PAO ( LR )
2. LR ← LR + 1
3. dekodowanie KodOP
4. RT ← PAO ( RR.Arg )
5. Arytmometr ← RB, RT, PLUS
6. RB ← Arytmometr
zmiana sekwencji rozkazów
skok bezwarunkowy JMP
85
86
+1
.
.
.
LR
+1
+1
+1
JMP
JMP
370
250
251
252
85
370
371
wykonanie rozkazu JMP 370
1. RR ← PAO ( LR )
2. LR ← LR + 1
3. dekodowanie KodOP
4. LR ← RR.Arg
skok warunkowy JZ RA, 3223
1. RR ← PAO ( LR )
2. LR ← LR + 1
3. dekodowanie KodOP
4. jeżeli RA == 0 to LR ← RR.Arg
prosty program
S = Σ ai
1≤i ≤n
n, a1, a2, ... , an
100 : SET RA, 0
; zeruj sumę S
101 : MOV 200, RA
; zapamiętaj S
102 : IN
RB, 1
; czytaj n
103 : IN
RA, 1
; czytaj a
104 : ADD RA, 200
; a + S
105 : MOV 200, RA
; zapamiętaj S
106 : DEC RB
; n – 1
107 : JZ
; skocz gdy n = 0
RB, 109
108 : JMP 103
; skocz gdy n ≠ 0
109 : OUT 2, RA
; wyprowadź wynik
modyfikacja argumentu rozkazu
adresowanie bezwzględne :
adres PAO = argument
adresowanie względne :
adres PAO = argument + zawartość rejestru
dodatkowe pole w rozkazie
KodOP R M
RA
RB
Arg
0
0
1
1
bez modyfikacji
modyfikacja przez RA
MOV RB, RA + 500
RA
Adres
0
500
1
501
2
502
150
650
151
651
3265
3765
zerowanie obszaru pamięci o długości
2038 bajtów począwszy od adresu 1033
300 : SET
RB, 2038
; długość
301 : MOV
150, RB
; pamiętaj
302 : MOV
RA, 0
; modyfikator
303 : MOV
RB, 0
; wartość
304 : MOV
RA + 1033, RB ; zeruj
305 : INC
RA
; modyfikator+1
306 : MOV
RB, 150
; odczytaj
307 : DEC
RB
; długość-1
308 : MOV
150, RB
; pamiętaj
309 : JZ
RB, 311
; gdy koniec
310 : JMP
303
; powrót
311 :
; koniec
•
stos – zapis / odczyt
0
1
wzrost
stosu
skracanie
stosu
szczyt stosu
WS
szczyt stosu
N
D
D
WS
PUSH R
POP R
↓
↓
PAO ( WS ) ← R
WS ← WS + 1
WS ← WS – 1
R ← PAO ( WS )
istnieją inne realizacje
•
stos – wywoływanie podprogramów
X
X+1
CALL Y
Y
.
.
.
RET
WS
WS
X+1
CALL AP
↓
RET
↓
PAO ( WS ) ← LR
WS ← WS + 1
WS ← WS – 1
LR ← PAO ( WS )
LR ← AP
ADRESACJA PAMIĘCI
adres
k bitów
n = 2k
2k adresów
k = log2 n
0
k-1
0
2k - 1
1 MB
k = 20
4 GB
k = 32
RAM, ROM, PROM, EPROM, EEPROM, flash ROM
czas zapisu / odczytu : od 10 ns
pojemność (PC) : od 1GB
•
segmentacja pamięci
0
k-1
0
RPS
0
n-1
0
RAD
k-1
2n - 1
0
RKS
n<<k
k = 32 4 GB
n = 16 16 kB
2k - 1
•
przeadresator układowy
k-1
0
n-1
0
RPS
RAD
+
k-1
0
RAF
k-1
RKS
0
>
DOBRZE
1 program
BŁĄD
1 segment
1 program wiele
segmentów
19
16 15
0
NrSeg
NrBajtu
Adres 32 bity
Adres pierwotny
Długość 32 bity
błąd
31
0
Adres fizyczny
• pamięć wirtualna
Czas dostępu
Pojemność
Pamięć RAM
100 ns
2 GB
Pamięć dyskowa
10 ms
500 GB
100 000 x
250 x
pamięć wirtualna:
● z punktu widzenia programu pamięć adresowana
liniowo o dużej pojemności ( np. 40GB )
● realizowana za pomocą pamięci dwupoziomowej :
stronicowanie
PAO
PZ
4kB
4kB
4kB
4kB
4kB
4kB
.
.
.
.
.
.
NrStrony
NrBajtu
Adres pierwotny
Tabela Stron
0
Adres strony
P
1
• gdy P = 0
system operacyjny
sprowadza stronę
• 80 90 % trafień
Adres fizyczny
pamięć notatnikowa ( cache )
Procesor 2 GHZ 0,5 ns
RAM
100 ns
200 x
• szybka pamięć pomiędzy procesorem a RAM (10 ns)
Adres fizyczny RAM
NrWiersza
NrBajtu
Pamięć Asocjacyjna
Pamięć Danych
NrW
0
128 B
NrW
1
128 B
.
.
.
NrW
.
.
.
128 B
255
32 kB
tak
nie
● pamięć hierarchiczna
Pamięć
notatnikowa
I rzędu
Pamięć
notatnikowa
II rzędu
Pamięć
RAM/ROM
Pamięć
wirtualna
Pamięć
dyskowa
Pamięć
operacyjna
System przerwań
IN R, NN
; odczyt znaku z klawiatury
Procesor : 1 rozkaz
1 μs * 1000000 = 1 s
Człowiek : 1 znak
1s
* 1000000 = 1000000 s
(ok. 12 dni)
procesor wykonuje inne rozkazy do czasu otrzymania
sygnału gotowości urządzenia :
sygnał przerwania
reakcja na sygnał przerwania
składowanie stanu procesora
zawsze w tym samym miejscu
stos systemu operacyjnego
stos programu użytkowego
ustalenie adresu podprogramu obsługi przerwania
adres zawsze taki sam
adres obliczany na postawie numeru przerwania
(wektoryzacja)
wykonanie programu obsługi przerwania
na końcu podprogramu obsługi przerwania rozkaz
powrotu do przerwanego programu (RETI)
POBRANIE
ROZKAZU
POWIĘKSZENIE
LR
WYKONANIE
ROZKAZU
TAK
NIE
PRZERWANIE ?
ZAPAMIĘTAJ
LR
DO LR
WPISZ ADRES
PODPROGRAMU
OBSŁUGI
PRZERWANIA
realizacja procesora
– RISC : dla każdego rozkazu
zestaw układów cyfrowych
– CISC : wewnętrzny mikroprocesor,
rozkaz mikroprogram
• kanały danych ( DMA )
DMA
INTR
Adres PAO
Licznik bajtów
HOLD
HLDA
Procesor
READ WRITE
ACK
WRITE
READ
READ
WRITE
PAO
UZ
• architektura PC
Procesor
RAM
CD
ROM
P. Notat.
Monitor
HD
Ster. Graf.
Ster. Dysk
MAGISTRALA
Sterownik
Sterownik
Magistrali
Klawiat.
Zegar
Analizator
Przerwań
CHIPSET
DMA
Sterownik
USB
udoskonalenia podstawowej pętli pracy procesora
– przetwarzanie potokowe
pobieranie
rozkazu
przygotowanie
argumentów
RK3
RK2
wykonanie
rozkazu
RK1
– kilka arytmometrów ( stało i zmiennopozycyjnych )
– wykonanie kilku rozkazów równocześnie
ADD RA, 5
ADD RA, 25
ADD RB, 27
MOV 100, RA
– predykcja skoków
• komputery wektorowe i macierzowe
. . .
A
A
. . .
. . .
RWA
A
RWB
• komputery wieloprocesorowe, wielordzeniowe
PAO
P1
P2
. . .
Pn
Połączenia
P1
P2
PAO
1
PAO
2
. . .
. . .
Pn
PAO
n
•
superkomputery
www.top500.org
(11.2011)
1. K computer, RIKEN Advanced Institute for
Computational Science (AICS), Japan, SPARC64
VIIIfx 2.0GHz, Tofu interconnect, 10.5 PFlop/s,
Fujitsu
2. NUDT YH MPP, National Supercomputing Center
in Tianjin, China, Xeon X5670 6C,
2.93 GHz, NVIDIA 2050, 2.5 PFlop/s, NUDT
3. Cray XT5-HE, DOE/SC/Oak Ridge National Laboratory,
United States, Opteron 6-core, 2.6 GHz, 2.3 PFlop/s,
Cray Inc.
ad 1.
– SPARC64 VIIIfx, 2.0GHz, 8 rdzeni, 45 nm CMOS
– 88128 procesorów, 705024 rdzeni
– 864 obudowy, w obudowie:
102 procesory SPARC,
6 procesorów I/O,
– dla każdego procesora SPARC 16GB PAO,
razem 1,4 PB
– pobór mocy elektrycznej 12.7 MW
– układ połączeń : 6-wymiarowy torus
– system operacyjny : Linux
– moc obliczeniowa 10.5 PFlop/s
(sprawność 93,2%)
Sieci Komputerowe
K
K
K
• sieć rozległa ARPA od 1957, uruchomienie 1969
• ok. 20 komputerów
• Interface Message Processor
IMP
K
K
IMP
IMP
K
• sieci lokalne, lata 70-te
SERWER
K
K
K
K
Internet (1983) : globalna sieć komputerowa powstała
z połączenia wielu sieci lokalnych
za pomocą sieci rozległych (szkieletowych)
wspólna metoda przesyłania danych :
protokół TCP/IP
rozproszona struktura własności
Komisja Standaryzacyjna
Komisja Przydzielająca Adresy
•
Protokół IP : ramki danych , adresy IP
NAGŁÓWEK
adres IP odbiorcy
DANE UŻYTKOWE
adresy IP : 32 bity (4 bajty)
0.0.0.0
255 . 255 . 255 . 255
ponad
4,2
mld
adres
ów
grupy adresów nr_sieci | nr_komputera
– A:
1 126 |
ok. 17 mln komputerów
126 sieci
– B:
128 191 |
ok. 65 tys. komputerów
ok. 16 tys. sieci
– C:
192 223 |
ok. 2 mln sieci
254 komputery
adres sieci Komisja
adres komputera administrator sieci :
ustawić w systemie operacyjnym
sieci prywatne 192.168.x.x
dynamiczny przydział adresu IP : DHCP
IPv4
IPv6 : adres 128 bitów
numery portów 150.254.56.12:3422
•
przełącznik trasujący (router)
tablice trasowania (routing)
R
R
R
R
R
R
R
K
K
K
K
K
K
Usługi Internetu
przesyłanie plików : ftp ftp.man.poznan.pl
poczta elektroniczna
zdalna praca : telnet, putty, ssh
strony WWW
WWW
Timothy B. Lee, CERN, 1991
– plik powitanie/info
– automatyczne sprowadzanie/wyświetlanie
– stała nazwa : index.html
– strona WWW plik danych
podział na
– serwery
WWW
przechowują
strony (pliki)
i
udostępniają
– terminale WWW sprowadzają i wyświetlają
strony (pliki)
oprogramowanie
– serwer WWW Apache, IIS
– przeglądarka WWW Internet Explorer, Chrome
Netscape, Mozilla, Opera, Firefox
nazwy serwerów WWW
www.wp.pl
URL
www.microsoft.com
domena
kraj
rodzaj
podstawowe domeny
.com
.edu .net
.gov
.org .......
główna
nazwy stron WWW URL
www.news.info/info5-html
zamiana URL IP : serwery DNS
DNS
IPDNS | URLS
IPK | IPS
IPS | URLS
S
K
IPK | plik
rezerwacja domen
–
Polska NASK, ...
domena regionalna
.poznan.pl : 50 zł/rok
domena funkcjonalna
.com.pl
: 150 zł/rok
domena ogólnopolska .onet.pl
: 200 zł/rok
– USA BetterWhois.com lista firm, $20/rok
• dostęp do Internetu
– modem analogowy 56 kb/s ~ 5 kB/s
komputer
modem
modem
komputer
l. telef.
"0"
500
"1"
700
f [Hz]
– modem cyfrowy ADSL wiele kanałów
częstotliwościowych
– max 6144 kb/s ~600 kB/s
ok. 4 km
– Neostrada 1024/256 , ... , 4096/1024kb/s
– częstotliwości ortogonalne
f1
f2
f3
f4
f247
KLIENT
N1
N2
O3
N4
N247
O1
f1
O2
f2
N3
f3
O4
f4
O247
f247
SIEĆ
– łącze kablowe
skrętka
do 1Gb/s
światłowód do 10 Gb/s
–
łącza radiowe
Bluetooth 1 Mb/s
2.4 GHz 10 m
WiFi 802.11b 11 Mb/s 2.4 Ghz 30 m Hot Spot
GSM :
GPRS ok. 50 kbit/s,
EDGE do 240 kbit/s
UMTS do 14,4 Mbit/s.
LTE do 300 Mbit/s
Sieć naukowa PIONIER (10 GB/s)
•
struktura warstwowa sieci komputerowej
–
model warstwowy
Prezes
Prezes
Tłumacz
a w
Tłumacz
b a
Sekretarka
Sekretarka
Mejl
Mejl
WĘGRY
BIRMA
•
struktura warstwowa sieci komputerowej
– model warstwowy OSI
aplikacji
aplikacji
prezentacji
prezentacji
sesji
sesji
transport.
transport.
sieciowa
sieciowa
łącza
danych
łącza
danych
fizyczna
fizyczna
–
fizyczna : transmisja bitów
–
łącza danych : ramki, poprawność, potwierdzenia
retransmisje
–
sieciowa : trasa transmisji ramki
–
transportowa : podział danych na bloki,
przesył w odpowiedniej kolejności, szyfrowanie
–
sesji : sterowanie dialogiem partnerów
–
prezentacji : definicja formatu danych
i ich transformacja dla aplikacji
– aplikacji : dostęp do sieci dla aplikacji partnerów
transmisja danych do/z urządzeń zewnętrznych
łącze równoległe
–
25-pin, DATA[ 8 ] , STROBE/, ACK/ , BUSY
– "1" +5V , "0" 0V
–
prędkość dla trybu Centronics ok. 50 - 150 kB/s
–
ECP, EPP prędkość 0.5 - 115 MB/s
łącze szeregowe RS232C
–
asynchroniczna transmisja szeregowa
S
0
1
0
1
0
1
1
0
P
K
K1
TxD
TxD
RxD
RxD
GND
GND
K2
–
"1" -3 ÷ -25V , "0" +3 ÷ +25V
–
prędkości 150, 300, 600, 1200, 2400, 4800
9600, 19200, 38400, 115200 b/s
łącze PS2
– klawiatura i myszka
6-pin Mini-DIN (PS/2):
1 – Data
2 - Nothing
3 - Ground
4 - Vcc (+5V)
5 - Clock
6 - Nothing
port USB
–
szybkie łącze szeregowe
– "1" D+ != D-
–
; "0" D+ == D-
USB 1.0 12 Mb/s ; USB 2.0 480 Mb/s
łącze ThunderBolt
–
bardzo szybkie łącze szeregowe
10 Gbit/s – kabel miedziany do 100 m
100 Gbit/s – kabel światłowodowy