Programowanie obiektowe
Nazwa zadania
Projekt pełen - implementacja
“Drzewa”
Dzień, godzina
środa, 12:15
Imię i Nazwisko
Paweł Tarasiuk
Rok akademicki
2009/2010
Imię i Nazwisko
Grzegorz Graczyk
Opis programu
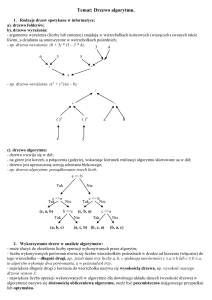
Projekt składa się z implementacji przydatnych struktur danych – grafów które nie mają cykli, czyli drzew. Istotą projektu jest
wykorzystanie polimorfizmu w celu zaimplementowania wielu drzew przy minimalnej koniecznej do tego liczbie kodu –
implementując kolejne drzewo zajmujemy się tylko tym, co jest dla niego specyficzne. Zaimplementowana została w ten sposób
np. lista “DendroList”, która dziedziczy po uniwersalnej klasie “Tree” (należy zauważyć, że lista dwukierunkowa jest po prostu
drzewem, w którym każdy wierzchołek ma dokładnie jednego syna). Bardziej praktyczne są przygotowane implementacje drzew
binarnych: kopca oraz drzew binarnych wyszukiwań. Poza zwykłym drzewem wyszukiwań binarnych przygotowane zostały
dziedziczące po nim szczególne implementacje dbające o zachowanie zrównoważenia drzewa – drzewa AVL oraz czerwono-czarne.
Poza samymi klasami drzew, oczywiście zaimplementowane zostały specjalne klasy do przechowywania wierzchołków oraz ich
własności. Każdy wierzchołek posiada wskaźnik na rodzica listę wskaźników dzieci, natomiast każde drzewo przechowuje wskaźnik
na swój korzeń.
Każde drzewo umożliwia dodawanie elementów na podstawie wartości (funkcja dodająca zwraca wskaźnik utworzonego elementu,
który można przechowywać), usuwanie na podstawie wskaźnika oraz “przeglądanie” drzewa – czyli wykonywanie zdefiniowanej
przez programistę funkcji dla każdego wierzchołka w kolejności inorder, preorder bądź postorder (wykonywany jest algorytm DFS).
Projekt zawiera także przykład użycia tej funkcji, dzięki któremu można obserwować drzewo, dodawać/usuwać elementy i
analizować wynikające z tego zmiany.
Przygotowana funkcja main stanowi prosty wiersz polecenia, służący do tworzenia drzew, dodawania/usuwania elementów,
sprawdzania czy element o danej wartości istnieje, wyświetlania bieżącego stanu drzewa oraz wykonywania funkcji specyficznych
dla drzewa danego typu (takich, jak “pop” dla kopca).
Przygotowane klasy oczywiście dają możliwości większe, niż te użyte w pliku wykonywalnym projektu. Prawdziwym zastosowaniem
jest stosowanie elementów tego projektu jako biblioteki, z której na pewno wiele razy skorzystamy. Posiadania własnej
implementacji pewnych struktur danych może okazać się dla nas pomocne podczas udziału w konkursach algorytmicznych, na
których można mieć przy sobie wydruki własnych kodów źródłowych przygotowanych wcześniej. Największe znaczenie będzie
jednak dla nas miała wiedza zdobyta podczas tworzenia projektu – implementacja drzew czerwono-czarnych oraz AVL była dla nas
interesującym doświadczeniem.
Dokumentacja techniczna - diagram klas
Dokumentacja techniczna - wybrane scenariusze działania
•
Przygotowany program stanowi prosty wiersz polecenia – istnieje kilka zdefiniowanych przez nas poleceń, które pozwala
utworzyć drzewo wybranego typu, zarządzać nim oraz obserwować powstające zmiany. Możliwe zmiany to dodanie oraz
usunięcie elementu o zadanej wartości. W przypadku kopca – dostępne są polecenia “pop” oraz “push”. W dowolnej chwili
można wyświetlić zawartość drzewa w elegancki sposób, albo po prostu wypisać wartości elementów w kolejności inorder. W
momencie utworzenia nowego drzewa, stare zostaje zwolnione z pamięci, a dalsze operacje przeprowadzane są na nowym
drzewie. W dowolnym momencie można także opuścić program.
Programowanie obiektowe
•
Projekt pełen - implementacja
Klasy przygotowane w ramach projektu mogą zostać wykorzystane poza nim – projekt stanowi tak naprawdę bibliotekę z
bardzo uniwersalnymi klasami. Można np. wykorzystać naszą implementację kopca w celu przeprowadzenia sortowania przez
kopcowanie, stworzyć słownik wykorzystujący nasze drzewo AVL, albo wykorzystać nasze drzewo czerwono-czarne zamiast
szablonu “set” z biblioteki STL. Praktycznie wszędzie, gdzie potrzebna jest zaimplementowana przez nas struktura danych,
można wykorzystać właśnie naszą, zawartą w projekcie implementację.
Dokumentacja techniczna - inne elementy nie opisane powyżej
Niektóre klasy zawierają specyficzne dla nich metody, pozwalające używać ich w sposób bardziej intuicyjny oraz zgodny ze
szczególnym przeznaczeniem. Dla elementu zaimplementowanej przez nas listy istnieją metody getNext, getPrev, setNext oraz
setPrev. Kopiec posiada natomiast metody “pop” i “push”.
Zaletą pisanego przez nas kodu jest także brak polonizacji nazw – dzięki temu przygotowane przez nas klasy mogłyby się stać
elementem jakiegoś innego projektu, rozwijanego przez osoby nie znające języka polskiego.
Zmiany w stosunku do implementacji projektu uproszczonego
Zdecydowaliśmy się na to, aby niektóre szczególne drzewa binarnych wyszukiwań korzystały po prostu z generycznych klas
opisujących element drzewa binarnego, zamiast wprowadzać dziedziczące po nich własne klasy wierzchołków drzew. Po prostu
okazało się to niepotrzebne, a dzięki uniknięciu tego projekt jest odrobinę lżejszy.
Zmiany w odniesieniu do projektu pełnego
Do projektu zostało dodane nowe drzewo: kopiec dwumianowy. Posiada on interfejs identyczny ze zwykłym kopcem, choć nie
dziedziczy z niego.
Ponadto wprowadzono nowe klasy abstrakcyjne: Searchable oraz Popable. Klasy te nie posiadają żadnych pól i posiadają po jednej
metodzie czysto wirtualnej – odpowiednio: TreeElement* findElement(int) oraz int pop(). Ich wykorzystanie za pomocą
wielodziedziczenia pozwala stwierdzić czy dany obiekt oferuje odpowiednie metody.
Dokumentacja użytkownika
Osoba uruchamiająca przygotowany przez nas projekt może:
•
Przeczytać początkowe wskazówki, które dadzą duże szanse na to, że użytkownik po prostu poradzi sobie ze wszystkim kierując
się intuicją.
•
Utworzyć nowe drzewo za pomocą polecenia “tree NUMER”, według początkowej wskazówki. Od tej pory dotychczasowe drzewo
(o ile istniało) zostanie zwolnione z pamięci, a nowo utworzone drzewo stanie sie aktwyne.
•
Dodać element do drzewa poleceniem “add element”.
•
Wyświetlić stan drzewa poleceniem “ls”.
•
Wypisać wartości elementów w kolejności inorder poleceniem “inorder”.
•
Dla drzew wyszukiwań binarnych (czyli także czerwono-czarnych i AVL) – rozstrzygnąć, czy element o danej wartości znajduje
się w drzewie poleceniem “find WARTOŚĆ” oraz usunąć pierwszy znaleziony element o danej wartości poleceniem “rm
WARTOŚĆ”.
•
Dla kopca: poznać wartość największego elementu a zarazem usunąć go za pomocą polecenia “pop” oraz dodawać elementy
intuicyjnym w przypadku kopca poleceniem “push”.
•
Opuścić program wpisując “quit”.
Miejsce na uwagi prowadzącego