1. Model relacyjnej bazy danych
1.1. Wprowadzenie
Bazy danych zaliczają się obecnie do najważniejszych i najliczniejszych
aplikacji komputerowych. Znajdują bowiem zastosowanie w bardzo szerokim
zakresie od domowych spisów płyt kompaktowych, poprzez księgowość małych i
średnich przedsiębiorstw do źródeł wiedzy o klientach dużych korporacji, bądź
obywatelach danego państwa.
W zamierzchłej przeszłości, gdy na świecie nie było jeszcze komputerów,
bądź ich użycie ograniczało się tylko do instytucji naukowych, przechowywanie
informacji stanowiło nie lada problem. Głównym nośnikiem informacji był
wówczas papier. Papierowe bazy danych istniejące również w dzisiejszych
czasach w postaci tzw. archiwów z wieloma teczkami i dokumentami niosą za
sobą różnorakie problemy. Podstawowe z nich związane są z rozmiarem,
odpornością na zniszczenie i upływ czasu, problemami z kopiowaniem,
udostępnianiem, a także wyszukiwaniem i prezentacją informacji. Te ostatnie są
wyjątkowo uciążliwe w przypadku gdy w archiwum panuje bałagan.
Najważniejszy jest zatem system użyty przy rozmieszczaniu informacji wewnątrz
archiwum – im bardziej spójny i jednoznaczny – tym łatwiej wydobyć informacje.
System taki, w oparciu o matematyczne teorie opracował w latach 1969 – 1970
matematyk dr E. F. Codd w pracy „Relacyjny model danych dla dużych banków
danych”. O ile stosowanie się do ścisłych reguł matematycznych przez ludzi
pracujących w archiwum nie zawsze dawało oczekiwane rezultaty, o tyle
odpowiednio zaprogramowane komputery potrafiły bez problemu zastosować
teorię w praktyce.
1.2. Tabele, wiersze, kolumny, pola
Model relacyjny stanowi podstawę większości z dzisiejszych baz danych. Jego
zasadniczą cechą jest to, że informacje przechowywane są w tabelach (w pracy
dr Codd’a zwanych relacjami), a każda tabela zbudowana jest z wierszy i
kolumn. Wiersz tabeli nazywany jest rekordem na który składają się osobne pola
– czyli elementy znajdujące się na przecięciu kolumny i wiersza. Pole, zwane
również komórką zawiera najmniejszą, niepodzielną wartość, czyli taką porcję
informacji, której nie można już dalej podzielić ze względu na spójność logiczną.
Przykładową tabelę przechowującą informację o autach pozostawionych w
komisie samochodowym przedstawia Rysunek 1.
Pomimo iż z założeń relacyjnego modelu bazy danych wynika aby
zgromadzone w bazie informacje prezentowane były w postaci tabel, to w
rzeczywistości mogą być one przechowywane w sposób dowolny. Tabela jest
bowiem pojęciem abstrakcyjnym, które ma za zadanie rozdzielić warstwę
prezentacji i zarządzania danymi od sposobu ich przechowywania w systemie
komputerowym (który może opierać się np. na pojedynczym pliku binarnym).
kolumna
pole
wiersz
Rysunek 1: Schemat tabeli
1.2.1.
Kolumny i typy danych
Z każdą kolumną związany jest określony typ przechowywanych w niej
danych. W zależności od konkretnego systemu rozróżniamy typy numeryczne,
tekstowe, daty / czasu, a nawet binarne. Typ danych przechowywanych w
kolumnie określamy na etapie projektowania tabeli. W przeciwieństwie do
sposobu umieszczania danych znanego z arkuszy kalkulacyjnych takich jak MS
Excel, gdzie w obrębie danej kolumny w poszczególnych jej polach mogą
znajdować się dane różnego typu, w bazie danych wartości znajdujące się w
jednej kolumnie muszą być dokładnie tego typu, jaki został określony dla tej
kolumny.
Przykładowe typy danych z jakimi można się zetknąć podczas pracy z
systemami MS Access lub MySQL zgromadzone zostały Tabela 1.
Tabela 1: Przykładowe typy kolumn w systemach MS Access i MySQL
System bazodanowy
MS Access
MySQL
Opis
Typy tekstowe
TEXT(n)
BYTE
SMALLINT
INTEGER
SINGLE
2
CHAR(n)
VARCHAR(n)
Pole tekstowe o stałej szerokości n znaków
(n <= 255)
Pole tekstowe o zmiennej szerokości – maksymalnie
n znaków (n <= 255)
Typy numeryczne
TINYINT
Liczba całkowita o rozmiarze jednego bajta
SMALLINT
Liczba całkowita
INTEGER
Liczba całkowita długa
FLOAT
Liczba zmiennopozycyjna o pojedynczej precyzji
1. Model relacyjnej bazy danych
DOUBLE
DOUBLE
Liczba zmiennopozycyjna o podwójnej precyzji
Pozostałe typy
YESNO
BOOL
DATETIME
DATETIME
AUTOINCREMENT
----
NOTE
----
OLEOBJECT
----
----
BLOB
1.2.2.
Typ przechowujące tylko dwie wartości logiczne:
TRUE/FALSE (Prawda/Fałsz)
Data / Czas
Liczba całkowita – automatycznie zwiększana w
trakcie dodawania nowego rekordu
Nota
Typ przechowujący dowolny dokument typu OLE.
Może to być plik MS Word, Excel, plik muzyczny,
obraz lub nawet film
(ang. Binary Large Object) Duży obiekt zapisany w
postaci binarnej – może to być dowolny duży plik lub
tekst
Wartości domyślne i wartości NULL
Dla każdego wiersza (rekordu) możemy określić pola, które nie mogą
pozostawać puste (tzn. dodając nowy rekord musimy wpisać do nich jakieś
wartości). Pozostałe pola dla których jawnie nie podamy wartości mogą albo
przyjąć pewną wartość domyślną (określaną w trakcie projektowania tabeli) albo
przyjąć wartość NULL, która oznacza że pole jest puste. Wartość NULL jest
specjalnym rodzajem wartości i nie należy jej mylić z liczbą 0, pustym łańcuchem
znakowym, lub logicznym fałszem. W systemie MS Access pola przechowujące
wartość NULL są wyświetlane jako puste komórki.
1.2.3.
Klucze podstawowe, kandydujące i obce
Każdy wiersz tabeli powinien posiadać wartość (lub grupę wartości), która go
jednoznacznie identyfikuje. Kolumna (bądź też kolumny) przechowujące te
wartości noszą nazwę klucza podstawowego (ang. primary key). Oprócz
klucza podstawowego w tabeli mogą znajdować się inne grupy kolumn z
wartościami jednoznacznie identyfikującymi dany rekord - są to tzw. klucze
zastępcze. Klucz podstawowy wraz z kluczami zastępczymi tworzą w tabeli
grupę kluczy kandydujących. Aby dana kolumna (bądź ich grupa) mogła
zostać uznana za klucz kandydujący muszą zostać spełnione następujące
warunki:
-
W żadnych dwóch rekordach z tabeli nie mogą się pojawić te same
kombinacje wartości w kolumnach wybranych na klucz kandydujący.
Wewnątrz klucza kandydującego nie można wybrać podgrupy kolumn
również zapewniającej unikatowość rekordu.
Czasami niemożliwe jest wyodrębnienie przynajmniej jednego klucza
kandydującego, a co za tym idzie i klucza podstawowego. W takim przypadku do
tabeli dodaje się dodatkową kolumnę w której przechowywane dane są
unikatowe (np. z kolejno numerowanymi liczbami całkowitymi). Przykładem
takiego rozwiązania jest kolumna ID w tabeli Auta z Rysunek 1.
3
W modelu relacyjnym zawartość dwóch tabel można powiązać ze sobą
tworząc w jednej tabeli kolumnę (lub kolumny) zawierającą odnośniki do
rekordów z drugiej tabeli. Odnośniki te muszą jednoznacznie identyfikować
rekordy znajdujące się w drugiej tabeli, a zatem w jej obrębie muszą pełnić rolę
kluczy podstawowych lub kandydujących. Utworzone w jednej tabeli kolumny
(lub grupy kolumn) przechowującej wartości klucza podstawowego z tabeli
drugiej noszą nazwę klucza obcego (ang. foreign key).
1.3. Relacje
W przeciętnej komercyjnej bazie danych mamy do czynienia z informacją
rozłożoną na kilkadziesiąt tabel. Oczywistym jest zatem fakt, że potrzebny jest
mechanizm pozwalający na powiązanie danych z poszczególnych tabel w pełną
informację, którą chcemy wydobyć z bazy w danym zapytaniu. W tym celu
projektujemy bazę tak aby pomiędzy poszczególnymi danymi występowały tzw.
relacje (nie mylić z „relacjami” w sensie tabel pochodzącymi z nomenklatury
nazewnictwa przyjętej przed Codd’a – patrz punkt 1.2). Relacja opisuje w jaki
sposób dane łączą się ze sobą. Zasadniczo rozróżniamy trzy typy relacji: jedendo-jeden, jeden-do-wiele i wiele-do-wiele.
1.3.1.
Relacja jeden-do-jeden
Pomiędzy dwiema grupami wartości (niekoniecznie tabelami) zachodzi relacja
jeden-do-jeden, jeżeli do każdego zespołu wartości z grupy pierwszej jest
przyporządkowany jeden i tylko jeden zespół wartości z grupy drugiej, czyli
występuje pomiędzy nimi tzw. zależność funkcyjna.
Rozważmy następujący przykład - w tabeli Klienci przechowywane są
informacje na temat klientów (np. komisu samochodowego). Każdy klient z racji
swej pełnoletności posiada dowód osobisty. Informację zawartą w dowodzie
(seria, PESEL) można przechowywać w osobnej tabeli Dowody_Osobiste.
Pomimo iż każdy wpis w tej tabeli jest jednoznacznie identyfikowany poprzez
PESEL lub serię, można również utworzyć dodatkowy, sztuczny identyfikator i
uczynić go kluczem podstawowym w tabeli Dowody_Osobiste a następnie jego
wartość umieścić również w kolumnie ID_Dowodu, w tabeli Klienci w celu
powiązania obu grup wartości(patrz Rysunek 2). ID_Dowodu pełni rolę klucza
obcego. W opisanej sytuacji pomiędzy tabelami Klienci a Dowody_Osobiste
zachodzi relacja jeden-do-jeden ponieważ każdemu klientowi przypisany jest
dokładnie jeden dowód osobisty i odwrotnie.
Rysunek 2: Relacja jeden-do-jeden
4
1. Model relacyjnej bazy danych
W przypadku wystąpienia tej relacji między danymi czasami można umieścić
je również w jednej tabeli, dodając odpowiednie kolumny (patrz Rysunek 3):
Rysunek 3: Tabela Klienci rozszerzona o PESEL i serię dowodu osobistego
Wybór rozwiązania zależy od konkretnego przypadku. Jeżeli dodatkowych
danych (w przykładzie jedynie PESEL i seria) jest dużo (dużo dodatkowych
kolumn) i nie będą używane zbyt często w zapytaniach, to ze względów
optymalizacyjnych można przenieść je do osobnej tabeli powiązanej z wyjściową
tabelą relacją jeden-do-jeden. W przypadku gdy są one wykorzystywane częściej
lub (i) nierozsądnie byłoby je rozdzielać (np. Imię i Nazwisko) to umieszczamy je
w jednej tabeli.
Innym przykładem mogą być relacje zachodzące pomiędzy ofertami a
transakcjami w komisie samochodowym. Załóżmy, że w tabeli Oferty
przechowywane są dane na temat wszystkich ofert jakie kiedykolwiek pojawiły
się w komisie. Poprzez ofertę rozumieć będziemy dane dotyczące klienta
chcącego sprzedać auto, samego auta, jego stanu technicznego, ceny za którą
klient chciałby auto sprzedać, a także daty wstawienia auta do komisu. Oferta
może następnie zostać zrealizowana w transakcji, bądź też wycofana przez
klienta (znudzonego np. długim oczekiwaniem na sprzedaż auta). W pierwszym
przypadku (udanej sprzedaży) odnośnik do oferty zostanie zapamiętany jako
klucz obcy ID_Oferty w tabeli Transakcje, przechowującej dodatkowo
informacje na temat wartości transakcji, kupującego i daty sprzedaży. W
przypadku wycofania auta z komisu, odnośnik do oferty zostanie zapisany w
tabeli Oferty_Wycofane, która dodatkowo może przechowywać informacje na
temat daty i powodu wycofania. Jako że dokładnie jednej ofercie odpowiada
dokładnie jedna transakcja albo dokładnie jedno wycofanie, pomiędzy tabelami
Oferty i Transakcje, a także Oferty i Oferty_Wycofane zachodzą relacje
jeden-do-jeden (patrz Rysunek 4). W tym przypadku umieszczanie danych w
jednej tabeli byłoby wysoce nieoptymalnym oraz nielogicznym rozwiązaniem,
gdyż jedna oferta może albo zostać zrealizowana poprzez transakcje, albo
zostać wycofana, ale nigdy jedno i drugie. Chcąc umieścić w jednej tabeli
wszystkie dane trzeba by było ją rozszerzyć o kolumny dotyczące zarówno np.
daty transakcji i daty wycofania, przy czym jedno z pól w danym wierszu
musiałoby pozostawać puste (albo data transakcji, albo data wycofania).
Podobna sytuacja zachodziła by z resztą kolumn specyficznych tylko dla
transakcji lub tylko dla wycofania.
5
Rysunek 4: Oferty, Transakcje, Oferty_Wycofane – przykład relacji jeden-do-jeden
1.3.2.
Relacja jeden-do-wiele
Relacja jeden-do-wiele zachodzi, gdy jedna grupa wartości jest powiązana z
kilkoma innymi.
Kontynuując przykład komisu samochodowego, taka relacja może zachodzić
pomiędzy transakcjami a klientami kupującymi (ten sam klient może dokonywać
zakupu w wielu różnych transakcjach) lub transakcjami a pośredniczącymi w
nich sprzedawcami – jeden sprzedawca może pośredniczyć w wielu
transakcjach. W pierwszym przypadku klucz obcy w tabeli Transakcje stanowi
ID_Kupujacego, a w drugim ID_Sprzedawcy – patrz Rysunek 5.
Rysunek 5: Relacja jeden-do-wiele
6
1. Model relacyjnej bazy danych
1.3.3.
Relacja wiele-do-wiele
Relacja wiele-do-wiele jest najbardziej skomplikowanym typem relacji. Do jej
zdefiniowania nie wystarczy już jedynie utworzenie w jednej tabeli klucza obcego
wskazującego na tabelę drugą. Aby pomiędzy dwoma tabelami utworzyć relację
wiele-do-wiele należy użyć trzeciej tabeli – tzw. tabeli łączącej.
Ten typ relacji wystąpiłby gdyby dopuścić do sytuacji w której więcej niż jeden
sprzedawca może pośredniczyć w jednej transakcji. Wówczas klucz obcy
ID_Sprzedawcy zostałby usunięty z tabeli Transakcje a w jego miejsce
utworzona
zostałaby
tabela
złączająca
Transakcje_Sprzedawcy,
przechowująca identyfikatory transakcji i odpowiadające im identyfikatory
sprzedawców – patrz Rysunek 6. Załóżmy w transakcji o numerze
identyfikacyjnym 3, pośredniczyliby sprzedawcy o numerach identyfikacyjnych 1 i
2. Wówczas w tabeli Transakcje_Sprzedawcy znalazłyby się dwa rekordy:
(ID_Transakcji = 3, ID_Sprzedawcy =1), oraz (ID_Transakcji =
3, ID_Sprzedawcy = 2). Tabela ta gromadziłaby zatem wszystkie pary
transakcja – sprzedawca, które zaistniały w trakcie pracy komisu, czyli pełniłaby
ona rolę łącznika pomiędzy transakcjami a sprzedawcami i na odwrót.
Rysunek 6: Relacja wiele-do-wiele - Transakcje - Sprzedawcy
Przykład z wieloma sprzedawcami pośredniczącymi w jednej transakcji
wprowadzony był aby zademonstrować ideę relacji wiele-do-wiele i tabel
złączających i w dalszych rozważaniach będzie pominięty w naszej przykładowej
bazie danych komisu samochodowego. Relacja wiele-do-wiele wystąpi jednak w
niej w sposób naturalny, w innym miejscu – pomiędzy autami, a klientami je
sprzedającymi. Wiele klientów może sprzedawać w odrębnych transakcjach, to
samo auto. I odwrotnie jeden klient może sprzedawać wiele różnych aut.
Naturalnym wnioskiem jest zatem że pomiędzy tabelami (zbiorami wartości)
Auta i Klienci zachodzi relacja wiele-do-wiele. Rolę tabeli złączającej pełni
znana nam już skądinąd tabela Oferty, która oprócz pól ID_Sprzedajacego i
ID_Auta wiążących klienta będącego sprzedawcą ze sprzedawanym
samochodem i vice versa, zawiera również dodatkowe informacje (cena,
przebieg auta, itd.) – patrz Rysunek 7.
7
Rysunek 7: Relacja wiele-do-wiele: Auta - Klienci (Sprzedający)
1.4. Operacje relacyjne
Na tabelach znajdujących się w bazie danych możemy wykonywać różne
operacje mające na celu wydobycie interesującej nas informacji. Operacje te
naszą miano zapytań (bądź w systemie MS Access – kwerend). Wynikiem
wszystkich zapytań są nowe, tymczasowe, utworzone w pamięci komputera
tabele, prezentujące otrzymane z bazy dane. Zasadniczo rozróżniamy 3
podstawowe typy operacji występujących we wszystkich relacyjnych bazach
danych:
1.4.1.
Selekcja
Wynikiem działania operacji selekcji są wybrane rekordy z tabeli. Tymczasowa
tabela będąca wynikiem takiego zapytania zawiera wszystkie kolumny z tabeli
źródłowej. Rekordy z tabeli źródłowej wybierane są według pewnych, określonych
kryteriów. W szczególności kryteria wyboru mogą zostać pominięte, a wynikiem
operacji będą wszystkie rekordy z tabeli.
1.4.2.
Projekcja
W przypadku projekcji zwracane są zawsze wszystkie rekordy z tabeli
źródłowej. Operacja ta pozwala jednak ograniczyć ilość kolumn znajdujących się
w tabeli wynikowej. Może być to bardzo istotne w przypadku gdy tabela źródłowa
zawiera bardzo wiele kolumn, a nas interesuje informacja zawarta w zaledwie
kilku z nich.
1.4.3.
Złączenie
Operacja złączenia (ang. join) polega na użyciu wielu tabel jako źródła danych
dla zapytania. W najprostszym przypadku kiedy nie określimy tzw. warunków na
podstawie których łączymy tabele źródłowe – wynikiem operacji będzie iloczyn
kartezjański wszystkich tabel źródłowych. W zależności od typu relacji pomiędzy
tabelami mechanizm łączenia oraz warunki złączeń mogą być różne.
W praktyce operacje selekcji, projekcji i złączenia miesza się i stosuje
równocześnie – dzięki czemu otrzymywany w ich rezultacie wynik końcowy
przyjmuje jak najbardziej przejrzystą i czytelną postać.
8
1. Model relacyjnej bazy danych
1.5. Normalizacja
Celem rozdzielania informacji, którą chcemy przechowywać w bazie na
odrębne tabele, powiązane ze sobą grupą relacji, jest przede wszystkim
wyeliminowanie
wielokrotnego
zapisywania
tych
samych
informacji.
Normalizacja polega na wykryciu w obiektach bazy nadmiarowych danych i
usunięcie ich poprzez zmianę struktury bazy. Najczęściej dokonuje się tego za
pomocą tzw. dekompozycji polegającej na dzieleniu tabeli na kilka tabel w taki
sposób, by żadne dane zgromadzone w tabeli źródłowej nie zostały utracone.
Dekompozycja musi być procesem odwracalnym – tzn. w wyniku ponownego
połączenia tabel otrzymanych w jej wyniku powinniśmy otrzymać tabelę
wyjściową. Nowa struktura bazy otrzymywana w wyniku normalizacji przyjmuje
jedną z tzw. postaci normalnych (ang. Normal Form, w skrócie NF).
1.5.1.
Pierwsza postać normalna 1NF
Tabela jest pierwszej postaci normalnej, jeśli wszystkie jej pola zawierają
jedynie wartości niepodzielne już na mniejszą porcję informacji (pola skalarne).
Gdyby wszystkie tabele bazy danych spełniały pierwszą postać normalną, to
relacje typu jeden-do-wiele nie mogły by występować w obrębie jednego wiersza
w tabeli (rekordu).
Rozważmy następujący przykład, w którym klient kupujący mógł zakupić wiele
aut w komisie. Gdyby do tabeli Klienci dodać kolumnę ID_Transakcji, w
której przechowywane by były oddzielone przecinkami identyfikatory transakcji,
w których klient brał udział (patrz Rysunek 8) to tabela ta łamałaby 1NF bowiem
ID_Transakcji zawierałoby dane podzielne na mniejsze elementy
(identyfikatory poszczególnych transakcji). W dodatku wewnątrz tabeli, w obrębie
pojedynczego wiersza, zachodziła by relacja jeden-do-wiele pomiędzy
ID_Transakcji a kluczem podstawowym oraz kluczami kandydującymi. Na
szczęście w naszej przykładowej bazie to ID_Kupujacego (czyli ID klienta) jest
przechowywane w tabeli Transakcje a nie na odwrót, co nie łamie 1NF. Dzieje
się tak dlatego, że jednej transakcji przyporządkowany jest tylko jeden klient
poprzez pole ID_Kupujacego, które w takim przypadku zawiera wartości
niepodzielne. Dodatkowo relacja jeden-do-wiele zachodzi pomiędzy dwoma
różnymi tabelami (Transakcje – Klienci – patrz Rysunek 5) a nie w
obrębie jednej tabeli.
O ile większość dobrze zaprojektowanych relacyjnych baz danych spełnia 1NF
w naturalny sposób i celowa normalizacja jest już nie potrzebna, o tyle uzyskanie
i utrzymanie bazy danych w wyższych postaciach normalnych bywa już nieco
trudniejsze.
Rysunek 8: Łamanie 1NF ze względu na ID_Transakcji
9
1.5.2.
Druga postać normalna 2NF
Tabela odpowiada drugiej postaci normalnej, jeżeli jest pierwszej postaci
normalnej oraz kolumny nie wchodzące w skład klucza są zależne od całego
klucza (nie od jego części).
Do zilustrowania idei 2NF posłużymy się ponownie błędem, który mógłby
zostać popełniony w trakcie projektowania naszej przykładowej bazy.
Zakładając, że jeden klient nie może sprzedawać tego samego auta więcej niż
raz, klucz podstawowy w tabeli Oferty może składać się z dwóch kolumn:
Auto - określającej auto wystawione na sprzedaż, oraz kolumny Sprzedajacy
– określającej klienta sprzedającego to auto. Gdyby w kolejnej kolumnie chcieć
umieścić PESEL sprzedającego wówczas zależałby on tylko on części klucza
głównego, dotyczącej sprzedającego, a tym samym łamałby on 2NF. W
przeciwieństwie do ceny auta, która jest specyficzna dla konkretnej oferty i
zależy jednocześnie od sprzedawanego auta, jak i sprzedającego, który za swój
samochód żąda określonej kwoty. Rysunek 9 przedstawia sytuację w której
jeden z klientów sprzedaje więcej niż jedno auto. Jego PESEL umieszczany jest
w tabeli dwukrotnie. Aby zapobiec tej sytuacji informację o PESEL-u wystarczy
przenieść do tabeli Klienci gdzie przechowywane są szczegółowe informacje
na temat klientów, zarówno tych sprzedających, jak i kupujących.
Rysunek 9: Łamanie 2NF ze względu na PESEL
1.5.3.
Trzecia postać normalna 3NF i postacie wyższe
Istnieją jeszcze wyższe postacie normalne, których nie będziemy szczegółowo
omawiać w ramach tego kursu. Na przykład trzecia postać normalna (3NF), która
w porównaniu z 2NF, wymaga dodatkowo, aby wszystkie kolumny nie należące
do klucza podstawowego, zależały funkcyjnie również od klucza zastępczego.
Nie są wymagane zależności pomiędzy kolumnami poza kluczem.
Rozszerzeniem 3NF jest postać normalna Boyce-Codd’a (BCNF), która jest
jeszcze bardziej restrykcyjna i w przypadku istnienia większej ilości kluczy
zastępczych nakłada konieczność istnienia zależności funkcyjnych pomiędzy
kolumnami wchodzącymi w skład jednego z kluczy, a pozostałymi kluczami.
Czwarta postać normalna (4NF) wyklucza relacje typu jeden-do-wiele
zachodzące pomiędzy niezależnymi kolumnami, a piąta (5NF) wykonuje
dekompozycję tabeli źródłowej na taką ilość tabel, która zapewnia całkowity brak
nadmiarowości danych.
10
1. Model relacyjnej bazy danych
Najczęściej normalizacja baz danych kończy się na postaciach 3NF i BCNF.
Dalsza normalizacja zazwyczaj jest niepotrzebna. Mimo że nadmiarowość
danych jest złym zjawiskiem, prowadzącym do szeregu problemów związanych
m.in. z konserwacją bazy i aktualizacją danych, to zbyt wysoka normalizacja
prowadzi do znacznego spadku wydajności. Albowiem każde, nawet najprostsze
zapytanie na bazie spełniającej wymagania wysokich postaci normalnych,
wymaga dużej ilości złączeń i podzapytań.
W praktyce projektant bazy musi znaleźć kompromis pomiędzy wydajnością a
normalizacją, specyficzny dla konkretnej bazy i obsługiwanego przez nią
problemu (zagadnienia). W przypadku projektowania prostych, nie komercyjnych
baz zazwyczaj nie myśli się o stosowaniu konkretnych postaci normalnych, a
raczej o tym jak rozsądnie uniknąć powielania tych samych danych w różnych
miejscach. Gdy zrobimy to dobrze, a następnie przyjrzymy się strukturze naszej
bazy, to zazwyczaj zobaczymy, że w naturalny sposób spełnia ona 1NF lub 2NF.
1.6. Indeksy
Jednym ze znaczących elementów poprawiających szybkość wykonywania
zapytań na bazie jest stosowanie indeksów. W przypadku baz danych indeks
spełnia podobną rolę jak skorowidz na końcu książki tzn. przechowuje odnośniki
do pewnego zbioru wartości – danych z tabeli (nie mylić z kluczami obcymi).
Zakładając indeks na kolumnie klucza podstawowego, system bazy tworzy listę
przechowującą wartości klucza i odnośniki do odpowiadających im rekordów.
Założenie indeksu spowalnia nieco operacje dodawania i aktualizacji rekordów,
jednakże może wydatnie przyspieszyć szybkość zapytań. Zasadniczo indeksy
można podzielić na unikalne i nieunikalne. W pierwszym przypadku wyklucza się
możliwość powtarzania wartości w indeksowanej kolumnie, dlatego nadaje się on
do indeksowania kolumn będących kluczem podstawowym.
1.7. Język SQL
W dzisiejszych czasach istnieje bardzo wiele systemów bazodanowych, czyli
takich, w których możemy utworzyć, a następnie posługiwać się naszą bazą
danych. Systemy te zasadniczo różnią się od siebie pod względem sposobu
zarządzania i przechowywania danych. Gdyby każdy z nich porozumiewał się z
programistą czy też użytkownikiem jedynie przy pomocy specyficznego dla siebie
interfejsu, to za każdym razem, chcąc zmienić system na inny musielibyśmy się
uczyć od nowa jak w danym systemie można zrealizować poszczególne operacje
na bazie. Aby uniknąć tego typu problemów zdefiniowano specjalny język SQL
(ang. Structured Query Language), który jest językiem umożliwiającym
pobieranie i zapisywanie danych oraz zarządzanie większością relacyjnych baz
danych. Mimo że istnieją pewne różnice w sposobie obsługiwania SQL-a przez
różne systemy baz danych, język ten jest na tyle ustandaryzowany, iż
opanowanie go dla jednego systemu, pozwoli aby wprawnie posługiwać się
innymi systemami obsługującymi SQL.
Język SQL składa się zaledwie z kilku typów wyrażeń, na tyle prostych że
nauczenie się ich składni zazwyczaj nie sprawia wielu kłopotów. W zamian
dostajemy potężne, uniwersalne narzędzie do komunikacji z relacyjnymi bazami
11
danych. W zależności od roli jaką odgrywamy w pracy z bazą, SQL dostarcza
nam wyrażeń służących do budowania struktury bazy (tabel, kolumn, indeksów),
wprowadzania danych, czy też wykonywania mniej lub bardziej skomplikowanych
zapytań w celu wydobycia interesujących nas danych a także obliczenia pewnych
statystyk i podsumowań.
Mimo że obecnie przyzwyczajeni jesteśmy do pracy z programami
komputerowymi, w których pewne informacje można wydobywać przy pomocy
klikania myszką, to praca z poważnymi bazami danych bez posługiwania się
językiem SQL jest raczej skomplikowana i uciążliwa (o ile w ogóle jest możliwa).
Dlatego znajomość SQL jest podstawą dla każdego szanującego się operatora
relacyjnej bazy danych.
Obecnie występują dwa najczęściej spotykane standardy języka: SQL-89 i
SQL-92. Specyfikacje te są na tyle obszerne, że praktycznie żadna z dostępnych
na rynku komercyjnych baz danych w pełni nie spełnia (nie implementuje) ani
standardu SQL-89 ani SQL-92. Standardem, który będzie preferowany w
niniejszym podręczniku będzie SQL-92.
1.8. Przykładowe systemy bazodanowe
1.8.1.
Definicja bazy i klienta
Pod pojęciem systemu bazodanowego rozumiemy zazwyczaj układ złożony z
bazy i klienta. Baza jest miejscem faktycznego przechowywania danych
podzielonych na tabele. To do bazy wysyłamy polecenia w języku SQL w celu
wykonania na niej jakiś operacji, bądź też wydobycia danych. Podsystem
wykonujący w bazie polecenia języka SQL będziemy nazywać aparatem bazy
danych.
Klient jest zazwyczaj programem umożliwiającym wpisywanie komend SQL i
przeglądanie wyników zapytań. W profesjonalnych systemach baza
umiejscowiona jest zazwyczaj na serwerze po to aby wielu użytkowników, przy
pomocy klientów zainstalowanych na ich lokalnych komputerach mogło
korzystać z tej samej bazy jednocześnie, poprzez zdalne połączenie z
serwerem. Rozwiązanie takie zapewnia integralność danych z którymi pracuje
wiele użytkowników. Gdyby bowiem każda osoba korzystała z własnej kopii tej
samej bazy i wykonywała modyfikacje zawartych w niej danych, to późniejsza
synchronizacja wielu takich kopii byłaby bardzo trudna do wykonania.
Obecnie dostępnych jest wiele profesjonalnych platform na których zakłada
się bazy danych. Zazwyczaj systemy te są uniwersalne – gotowe do użycia
przez każdą firmę czy użytkownika do zbudowania własnej, charakterystycznej
dla danego problemu bazy danych. Systemy te posiadają również szereg
ogólnych klientów umożliwiających zarządzanie bazą i przeglądanie wyników
zapytań. Jakkolwiek dzięki pewnym otwartym interfejsom programistycznym dla
każdej bazy można utworzyć własnego – wysoce wyspecjalizowanego dla
danego zagadnienia klienta. Przykładem tego może być na przykład duża firma,
chcąca dla swojego działu HR stworzyć bazę informacji o pracownikach. Kupuje
ona w tym celu licencję na profesjonalny komercyjny system (np. Oracle) i
zakłada na nim bazę. Używanie tej bazy bezpośrednio przy pomocy języka SQL
przez osoby nie mające pojęcia relacyjnych bazach danych (lecz może znające
12
1. Model relacyjnej bazy danych
się świetnie na zarządzaniu pracownikami) mogło by być dla nich mało
intuicyjne. Dlatego firma zleca zespołowi programistów przygotowanie
specjalnego klienta dostosowanego do struktury danej bazy i specyfiki problemu.
W ten sposób przeciętny pracownik działu HR, pracuje używając wewnętrznego
firmowego oprogramowania, nie mając nawet pojęcia, że dane do których ma
dostęp, znajdują się w bazie danych, zrealizowanej na ogólnej, komercyjnej
platformie, zainstalowanej gdzieś na serwerze. Oczywiście pracownik taki nie
może potem w CV pochwalić znajomością, czy też umiejętnością pracy z bazami
danych, a do wydobywania danych nie objętych zakresem funkcji klienta, musi
prosić kolegów znających SQL i strukturę bazy. W ogólności język SQL
zawdzięcza swą prostotę właśnie temu, że w „dawnych” czasach jedynymi
dostępnymi klientami bazy były terminale tekstowe, w których można było
wprowadzać zapytanie i przeglądać wyniki. A zatem język komunikacji z bazą
musiał być na tyle prosty, aby zwykły pracownik nie będący programistą, mógł
go opanować i sprawnie się nim posługiwać.
1.8.2.
Oracle
Bardzo popularna, komercyjna, profesjonalna baza danych. Bazy Oracle
użytkowane są na wszelkiego rodzaju sprzęcie: Unix, Solaris, Windows, Linux
itp. Mimo możliwości pracy pod wieloma niekiedy znacznie różniącymi się od
siebie platformami, Oracle na każdej z nich działa tak samo. Oznacza to że raz
stworzona baza dla Oracle pod systemem Unix, może być wykorzystana w
instalacji pod Windows. Bardzo wiele z dzisiejszych profesjonalnych aplikacji,
tworzonych na potrzeby dużych korporacji jest opartych właśnie o bazę Oracle.
1.8.3.
Microsoft SQL Server
Microsoft SQL Server jest odpowiedzią firmy Microsoft na zapotrzebowanie
rynku na duże, profesjonalne bazy danych. Stanowi on konkurencję dla baz
Oracle, jednakże jego główną platformą docelową jest oczywiście Windows. O
jego pozycji na rynku decyduje również umiarkowana, w porównaniu z Oracle
cena.
1.8.4.
MySQL
MySQL jest szybkim, wielowątkowym i wieloużytkownikowym serwerem baz
danych obsługującym język SQL. Do celów niekomercyjnych można go używać
w charakterze oprogramowania Open Source / Free Software dzięki licencji GNU
(General Public License). Istnieje również możliwość wykupienia licencji
komercyjnej. MySQL jako taki sam w sobie nie posiada klienta innego niż
konsolowy (wyświetlanego w trybie tekstowym, pozwalającego jedynie na
logowanie się do serwera, wybranie określonej bazy, a następnie wysyłanie do
niej zapytań SQL i przeglądanie wyników w postaci linii tekstu na ekranie).
Jakkolwiek w Internecie można odnaleźć szereg zewnętrznych klientów
posiadających intuicyjny i przyjazny interfejs użytkownika. MySQL jest idealny do
tworzenia systemów bazodanowych w Internecie z klientem opartym o strony
www i skrypty php. Mimo iż posiada ograniczenia stanowi doskonałą opcję w
przypadku gdy potrzebujemy efektywnego a zarazem taniego rozwiązania.
13
1.8.5.
MS Access
Wchodzący w skład pakietu MS Office, Microsoft Access łączy w sobie
jednocześnie rolę bazy jak i klienta. Ponadto istnieje możliwość podłączenia się
do jego bazy również za pomocą zewnętrznych klientów. Aparatem bazy MS
Access jest system MS Jet. Całość projektu, zawierająca dane z bazy, a także
poszczególne elementy związane z warstwą klienta przechowywane są w
pojedynczym pliku o rozszerzeniu .mdb. Można powiedzieć, że plik ten jest
„dokumentem” Accessa, podobnie jak *.doc są dokumentami Worda, czy .xls
dokumentami Excela. Pliki *.mdb można dowolnie kopiować i przenosić na
różnych nośnikach i dzięki temu z danej bazy można korzystać na wielu różnych
komputerach z zainstalowanym MS Access. Oczywiście w porównaniu Microsoft
SQL Server czy Oracle, Access jest raczej prostą zabawką znajdującą
zastosowanie w przypadku małych i średnich bazy danych, niekoniecznie
zorientowanych na setki użytkowników, ogromne ilości danych i wysoką
wydajność. Jakkolwiek jest on idealny do zastosowań domowo – biurowych, a
dzięki swojej stosunkowej prostocie i szeregu kreatorów może być on używany
również przez osoby nie będące profesjonalnymi administratorami baz danych.
1.8.5.1.
Struktura projektu MS Access
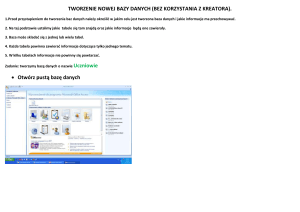
Po uruchomieniu środowiska Access, a następnie utworzeniu nowego pliku
lub otwarciu już istniejącego (menu Plik) pojawia się okno bazy danych (patrz
Rysunek 10). MS Access obsługuje tzw. interfejs wielodokumentowy MDI (ang.
Multiple Document Interface) znany z pozostałych programów wchodzących w
skład pakietu MS Office. Oznacza to, że w jednej sesji MS Access możemy
otworzyć wiele baz danych jednocześnie.
Rysunek 10: Widok Projektu MS Access
14
1. Model relacyjnej bazy danych
Na strukturę projektu składają się następujące elementy:
1. Tabele – są to obiekty służące do faktycznego przechowywania danych.
2. Kwerendy – są to zapytania, które możemy wykonać na tabelach aby
uzyskać bardziej szczegółowe informacje pochodzące z jednej lub
większej ilości tabel jednocześnie. Dane będące wynikiem działania
kwerendy mogą być prezentowane również w formie tabelarycznej.
Kwerendy mogą również służyć do wprowadzania, aktualizowania i
usuwania danych.
3. Formularze – bardzo przydatny element klienta MS Access, służący do
bardziej przejrzystej prezentacji i edycji danych zawartych w bazie.
4. Raporty – kolejny element klienta, służący do tworzenia raportów z
różnorakiego rodzaju podsumowaniami. Raport może zostać potem
wydrukowany.
5. Strony – interfejs do uzyskania dostępu do bazy poprzez Internet za
pomocą strony WWW
6. Makra – pomocnicze funkcje napisane w języku VBA (Visual Basic for
Applications)
7. Moduły - zbiory makr, zmiennych i funkcji języka VBA
1.8.5.2.
Widok relacji
Widok relacji wywoływany jest poprzez kliknięcie na przycisk
z głównego
paska narzędzi (dla komisu samochodowego przedstawiony został na Rysunek
11). Pozwala on na podgląd i edycję relacji zachodzących pomiędzy
poszczególnymi tabelami. Aby dodać tabelę do widoku należy z menu
podręcznego (dostępnego po kliknięciu prawym przyciskiem myszy) wybrać
opcję Pokaż tabelę lub Pokaż wszystko by wyświetlić wszystkie tabele
dostępne w bazie. Aby utworzyć nową relację wystarczy kliknąć lewym
przyciskiem myszy w kolumnę wybraną jako kolumna łącząca w jednej tabeli i
przeciągnąć je nad kolumnę łączącą z drugiej tabeli. Typ relacji jest na ogól
automatycznie wykrywany przez Accessa, jakkolwiek należy określić
dodatkowe opcje, takie jak:
-
-
Wymuszanie więzów integralności: czyli system zasad, które w
programie Microsoft Access są stosowane aby zapewnić, że relacje
pomiędzy powiązanymi tabelami są prawidłowe i że powiązane
rekordy nie zostaną przypadkowo usunięte lub zmienione. Należy
zaznaczyć to pole wyboru, aby wymusić więzy integralności dla
relacji, ale tylko w przypadku, gdy spełnione są wszystkie
następujące warunki: pasujące pole z tabeli podstawowej jest
kluczem podstawowym lub ma unikatowy indeks, powiązane pola
zawierają ten sam typ danych, obie tabele są przechowywane w tej
samej bazie danych programu Access.
Kaskadowa aktualizacja pól pokrewnych: należy zaznaczyć to
pole
aby
dokonywana
była
automatyczna
aktualizacja
odpowiadających sobie wartości w powiązanej tabeli po każdej
zmianie wartości klucza podstawowego w tabeli podstawowej. Po
15
wyłączeniu tej opcji, przy jednoczesnym zaznaczeniu pola wyboru
‘Wymuszaj więzy integralności’ następuje zablokowanie możliwości
zmian wartości klucza podstawowego w tabeli podstawowej, jeżeli
występują w tabeli powiązanej powiązane rekordy.
-
Kaskadowe usuwanie pól pokrewnych: należy zaznaczyć pole
wyboru Wymuszaj więzy integralności, a następnie pole wyboru
Kaskadowe usuwanie powiązanych rekordów, aby automatycznie
usuwane były powiązane rekordy w tabeli powiązanej po każdym
usunięciu rekordu w tabeli podstawowej. Należy zaznaczyć pole
wyboru Wymuszaj więzy integralności, a następnie wyczyścić pole
wyboru Kaskadowe usuwanie powiązanych rekordów, aby
zablokować możliwość usunięcia rekordów z tabeli podstawowej,
jeżeli w tabeli powiązanej występują rekordy powiązane.
Aby edytować opcje istniejącej relacji, należy dwukrotnie kliknąć na
symbolizującą ją linie łączącą dwie tabele. Aby usunąć relację, linię tę należy
zaznaczyć pojedynczym kliknięciem, a następnie usunąć przyciskiem ‘del’ lub
wybierając odpowiednią opcję z menu podręcznego pod prawym przyciskiem
myszy.
16
1. Model relacyjnej bazy danych
Rysunek 11: Widok relacji w MS Access dla bazy komisu samochodowego
Z widoku relacji warto jest korzystać nie tylko na etapie projektowania tabel,
ale także podczas pisania zapytań w języku SQL. Oprócz relacji zachodzących
pomiędzy tabelami zawiera on bowiem informację na temat struktury całej bazy,
w tym nazw tabel, kolumn a także kluczy podstawowych – oznaczanych
pogrubioną czcionką.
17
1.8.5.3.
Tworzenie tabel przy użyciu widoku projektu
Rysunek 12: Tabela - Widok Projekt
Widok projektu tabeli (Rysunek 12) jest wygodnym narzędziem służącym do
definiowania tabel w projekcie MS Access. Aby stworzyć w ten sposób nową
tabelę należy:
1. Przejść na zakładkę Tabele w głównym oknie projektu bazy danych.
2. Kliknąć pozycję Utwórz tabelę w widoku projektu
3. Po pojawieniu się okna projektu tabeli należy wpisać nazwy kolumn,
wybrać dla nich typy danych i (opcjonalnie) dodać komentarz do każdego
pola.
4. Po wpisaniu wszystkich kolumn i nadaniu im odpowiednich typów danych
można utworzyć tabelę wybierając przycisk Zapisz z paska narzędzi.
Program poprosi o wpisanie nazwy tabeli (proponując jednocześnie nazwę
domyślną), po czym utworzy nową tabelę bazy danych.
Każde z pól posiada zbiór specyficznych opcji, które można ustawić w widoku
projektu. Niektóre z nich nie należą do standardu relacyjnych baz danych.
Zestaw opcji zależy od typu danych pola.
18