Wprowadzenie do baz NoSQL
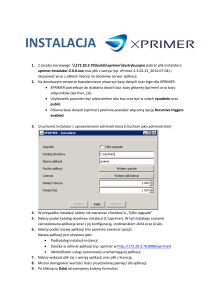
Technologie zarządzania treścią
dr inż. Robert Perliński
[email protected]
Politechnika Częstochowska
Instytut Informatyki Teoretycznej i Stosowanej
13 października 2016
Kwestie organizacyjne
Kontakt:
mail: [email protected]
strona: http://icis.pcz.pl/~rperlinski
konsultacje: wtorek 16:00 - 17:30, piątek 14:00 - 15:30
(najlepiej po wcześniejszym umówieniu drogą mailową)
Wprowadzenie do baz NoSQL
2/68
Plan przedmiotu
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
MEAN stack - krótkie wprowadzenie w Node.js
Wprowadzenie do baz danych NoSLQ
Bazy danych klucz-wartość
Redis
Bazy danych dokumentów
MongoDB - wprowadzenie, JSON
MongoDB - grupowanie, operatory agregacji
MongoDB - indeksy
Bazy rodziny kolumn
Cassandra - część 1
Cassandra - część 2
Bazy grafowe
Neo4j - część 1
Neo4j - część 2
XML i technologie pochodne
Wprowadzenie do baz NoSQL
3/68
Literatura
Pramod J. Sadlage, Martin Folwer, NoSQL Kompendium wiedzy,
Helion, 2015
Dan Sulivan, NoSQL Przyjazny przewodnik, Helion 2016
Karl Seguin, The Little Redis Book, 2012,
http://openmymind.net/redis.pdf
Karl Seguin, The Little MongoDB Book, 2011,
http://openmymind.net/mongodb.pdf
P. Kazienko, K. Gwiazda, XML na poważnie, Helion 2002
Dokumentacja online:
http://redis.io/documentation
https://docs.mongodb.com/manual/
http://cassandra.apache.org/doc/latest/
https://neo4j.com/developer/
Wprowadzenie do baz NoSQL
4/68
Plan wykładu
1
Bazy NoSQL
Ranking baz NoSQL, podział na modele danych
Termin NoSQL
Przyczyny powstania baz NoSQL
Spójność, teoria CAP
Modele dystrybucyjne
2
Porównanie do baz relacyjnych
3
Model danych
NoSQL a model relacyjny
Model danych zorientowany na agregacje
4
Inne modele danych
Bazy grafowe
Bazy danych bez schematu
5
Źródła
Wprowadzenie do baz NoSQL
5/68
Najpopularniejsze bazy NoSQL
Wprowadzenie do baz NoSQL
6/68
Najnowszy ranking systemów baz danych
http://db-engines.com/en/ranking
36 spośród 100 najważniejszych SZBD obecnych na rynku, to bazy NoSQL.
Bardzo dynamiczna branża przemysłu informatycznego:
nowe bazy NoSQL powstają co roku,
powstają też nowe funkcjonalności.
Wprowadzenie do baz NoSQL
7/68
Różne modele baz danych
Liczba systemów w każdej kategorii:
Wprowadzenie do baz NoSQL
http://db-engines.com/en/ranking_categories
8/68
Różne modele baz danych
Popularność różnych modeli daz danych:
Wprowadzenie do baz NoSQL
http://db-engines.com/en/ranking_categories
9/68
Różne modele baz danych
Zmany popularności od stycznia 2013 roku:
Wprowadzenie do baz NoSQL
http://db-engines.com/en/ranking_categories
10/68
Pojawienie się terminu NoSQL
Prawdziwy początek
Johan Oskarsson chciał zorganizowanie spotkania o „nowych” bazach
- czerwiec 2009.
Potrzebne było dobre hasło do Twittera, chwytliwe, mające mało
wynikow w Google.
Po sugestiach z kanału IRC #cassandra wybrał NoSQL.
Nazwa była negatywna i nie do końca pasowała do opisywanych
systemów - przyjeła się jednak. Przyjęła się nie tylko na to jedno
spotkanie ale na cały trend projektowania baz danych innego typu.
Spotkanie organizowane pod tym hasłem dotyczyło otwartych,
rozproszonych, nierelacyjnych baz danych.
Wprowadzenie do baz NoSQL
11/68
Termin NoSQL
Dwa znacznia:
nie SQL - średnio dobry termin - bazy NoSQL mobłyby z powodzeniem
używać SQLa; niektore posiadają języki zapytań, np. QCL z Cassandry,
nie tylko SQL - oznaczałoby też bazy relacyjne, takie do NoSQL nie należą.
Termin NoSQL:
przyjął się, ale wprowadza w błąd,
nic konkretnego nie definiuje, jest taką nie-definicją,
odnosi się do niedawno powstałych baz nierelacyjnych.
Wprowadzenie do baz NoSQL
12/68
Termin NoSQL
Termin NoSQL odnosi się:
do niezidentyfikowanego zestawu baz danych,
przeważnie typu open source,
przeważnie stworzonych w XXI wieku,
przeważnie nie wykorzystujących języka SQL.
Wprowadzenie do baz NoSQL
13/68
Dwa rodzaje skalowania
Ciągle zwiększające się zapotrzebowanie na dane i zasoby
(np. poprzez portale społecznościowe).
skalowanie w górę (pionowe) - większa wydajność i pojemność serwera, dużo
większa cena,
skalowanie w bok (poziome) - wykorzystanie wielu słabszych maszyn w
klastrze, mniejsza cena.
Wprowadzenie do baz NoSQL
14/68
Przyczyny powstania baz NoSQL
(Bardzo) duża liczba użytkowników - trudność w wykorzystaniu baz relacyjnych.
Właściwości SZBD ważne przy wykonywaniu zadań na dużą skalę:
skalowalność - zdolność do efektywnego radzenia sobie ze zmiennym
obciążeniem; skalowanie w poziomie bardziej elastyczne niż skalowanie
pionowe (w górę), bazy NoSQL lepiej przystosowane do skalowania
poziomego, nie potrzeba wymieniać serwera,
koszt - wysokie koszty i trudności w określeniu potrzebnej licencji; darmowe
i otwarte oprogramowanie NoSQL zachęca do użycia go,
elastyczność odpowiednie bazy do odpowiednich potrzeb, bazy NoSQL są
dobre dla danych niehomogenicznych (zróżnicowanych), np. różne atrybuty
produktów w aplikacji e-commerce,
dostępność - wysokie oczekiwania w stosunku do dostępności aplikacji;
wiele serwerów działających w klastrze pozwala na dostępność, nawet przy
awarii któregoś z tych serwerów.
Zapotrzebowanie na systemy skalowalne, tanie, elastyczne, o wysokiej dostępności.
Wprowadzenie do baz NoSQL
15/68
Bazy NoSQL - open source i do pracy w klastrach
Bazy relacyjne nie są zaprojektowane do pracy w klastrach.
Podział bazy relacyjnej na klastry jest możliwy ale bardzo dużo się
traci, są to „nienaturalne działania”.
Google Bigtable i Amazon Dynamo - pierwsze udane na masową skalę
wdrożenia innego sposobu przechowywania danych. Ogromny wpływ
na powstanie NoSQL.
NoSQL mocno zakorzeniony w ruchu open source.
Wprowadzenie do baz NoSQL
16/68
Bazy NoSQL
Bazy NoSQL:
pozwalają na przechowywanie danych bez schematu,
zwiększają produktywność tworzenia aplikacji - udostępniają model
danych lepiej pasujący do potrzeb aplikacji, nie potrzeba poświęcać
czasu na mapowanie danych,
zamiast tradycyjnej spójności udostępniają szereg innych
wartościowych właściwości,
są łatwiejsze w skalowaniu i programowaniu.
Wprowadzenie do baz NoSQL
17/68
Wymagania wobec systemu baz danych, spójność
Wymagania:
przechowywanie danych w sposób trwały,
utrzymywanie spójności danych,
zapewnianie dostępności danych.
Wymagania wobec spójności (dwa jej rodzaje):
pełna spójność,
dotyczy transakcji bazodanowych w bazach relacyjnych,
utrzymanie jednego, logicznie spójnego widoku danych,
np. przelewy na kontach bankowych,
możliwa chwilowa niespójność, ostatecznie wszystkie dane będą takie same,
dotyczy stanu kopii danych w systemach rozproszonych,
serwery są spójne, jeśli zgromadzone na nich dane są takie same,
implementowana przez bazy NoSQL,
np. towary w koszyku sklepowym
(jest mało prawdopodobne, że ktoś inny będzie patrzył na nasz koszyk).
Wprowadzenie do baz NoSQL
18/68
ACID i BASE
ACID - akronim czterech właściwości baz relacyjnych:
atomowość (ang. atomicity ), niepodzielność transakcji,
spójność (ang. consistency ), rygorystyczna spójność, po transakcji
wszystkie dane są integralne,
izolacja (ang. isolation), transakcje są izolowane, nie są widoczne dla
innych,
trwałość (ang. durability ), zakończona transakcja oznacza utrwalenie
danych na dysku.
Bazy NoSQL nie wspierają własności ACID, co najwyżej niektóre z nich.
Wspierają natomiast właściwości BASE.
Wprowadzenie do baz NoSQL
19/68
ACID i BASE
Właśności BASE baz NoSQL:
zasadnicza dostępność (ang. basically available) - w pewnych
częściach systemu mogą występować awarie, ale reszta systemu
kontynuuje działanie,
mięki stan (ang. soft state) - stan systemu może się zmieniać w
czasie nawet bez zmiany danych, które mogą zostać nadpisane
nowszymi danymi, ma to związek z ostateczną spójnością,
ostateczna spójność (ang. eventually consistent) - wkońcu wszystkie
dane w klastrze będą spójne, ale będą chwile, że dane nie będą spójne.
Wprowadzenie do baz NoSQL
20/68
Teoria CAP
Każdy klient może zawsze
odczytywać i zapisywać dane.
Bazy relacyjne
Klucz-wartość
Rodzina kolumn
Dokumentów
Availability (dostępność)
Cassandra
Dynamo
Voldemort
SimpleDB
CouchDB
Riak
RDBMS
(Oracle,
MySQL,
Postgre, ...)
Consistency (spójność)
Wszyscy klienci mają zawsze ten sam
obraz danych (dane są zawsze spójne).
BigTable, HBase,
Hypertable
MemcacheDB,
Redis, BerkeleyDB
MongoDB, Terrastore
Partition tolerance
(odporność na partycjonowanie)
System działa bezbłędnie niezależnie od
fizycznego podziału sieci (brak łączności
między węzłami klastra).
Teoria CAP - bazy danych nie mogą jednocześnie zapewniać spójności (ang. consistency ),
dostępności (ang. availability ) i ochrony przed partycjonowaniem (ang. partition tolerance).
Wprowadzenie do baz NoSQL
21/68
Replikacja i współdzielenie
Tło:
działanie baz NoSQL w dużych klastrach,
agregacje są idealnymi jednostkami do dystrybucji,
różne modele dystrybucyjne - różne opcje:
obsługa większych ilości danych,
możliwość przetworzenia większego ruchu odczytu i zapisu,
większa niezawodność w dostępnie do danych.
Dwie główne ścieżki dystrybucji:
replikacja - te same dane kopiowane są na wiele serwerów,
współdzielenie - umieszczanie różnych danych na różnych serwerach.
Replikacja i współdzielenie są do siebie ortogonalne - można je stosować
jednocześnie. Dwie formy replikacji: master-slave, peer-to-peer.
Wprowadzenie do baz NoSQL
22/68
Replikacja i współdzielenie
Replikacja
Wprowadzenie do baz NoSQL
Współdzielenie
23/68
Modele dystrybucyjne I
Najważniejsze modele dystrybucyjne:
pojedynczy serwer - baza działa na jednej maszynie obsługującej wszystkie
odczyty i zapisy,
współdzielenie (ang. sharding )
różne części danych na różnych serwerach; 10 serwerów, każdy
obsługuje 10% zapytań (np. podział na kraje, dni tygodnia...),
zwiększa szybkość zapisu i odczytu,
nie poprawia niezawodności i bezpieczeństwa danych,
replikacja master-slave - kopie danych na wielu serwerach,
replikacja synchronizuje podległe serwery z tym nadrzędnym,
dobrze się nadaje do systemów gdzie głównie odczytuje się dane,
zapis tylko na serwer główny,
zapewnia niezawodność odczytu,
serwery podrzędne mogą służyć też tylko jako kopia zapasowa,
różne połączenia z bazą (różne ścieżki) do zapisu i odczytu,
brak spójności.
Wprowadzenie do baz NoSQL
24/68
Modele dystrybucyjne II
Najważniejsze modele dystrybucyjne:
replikacja peer-to-peer
brak serwera głównego (nie ma serwera podatnego na awarię),
wszystkie repliki mają równe prawa, wszystkie wykonują zapis,
jest problem ze spójnością
chwilowa niespójność przy odczycie,
konflikt zapis-zapis w różnych miejscach - trwała niespójność,
dwa sposoby reagowania przy zapisie:
pilnowanie spójności i mniejsza dostępność,
większa dostępność ale zgoda na niespójność,
łączenie współdzielenia i replikacji
replikacja master-slave i współdzielenie
wiele serwerów głównych (każda część ma jeden serwer główny),
serwer może być głównym dla jednych danych i podrzędnym dla innych,
replikacja peer-to-peer i współdzielenie
częste dla baz rodziny kolumn - dziesiątki lub setki serwerów w klastrze,
współczynnik przetworzenia równy np. 3 - każda część danych jest na 3
serwerach.
Wprowadzenie do baz NoSQL
25/68
Zarządzanie danymi w systemach rozproszonych
Bazy NoSQL to zazwyczaj bazy rozproszone - prowadzi to do pewnych
problemów z zarządzaniem danymi.
Jeden serwer - łatwo o przerwy w dostępności.
Możliwa większa dostępność dzięki zapasowemu serwerowi.
Wykorzystanie zapasowego serwera zwiększa czas zapisu ale zwiększa
dostępność.
Wprowadzenie do baz NoSQL
26/68
Odczyt i zapis - kworum
Kworum - liczba serwerów, które muszą odpowiedzieć na operację
odczytu czy zapisu, aby operacja została uznana za zakończoną.
Wymaganą liczbę serwerów określa próg.
Przykład:
z 5 serwerów 2 mają chwilowo niespójne dane, próg odczytu wynosi 3,
baza odpytuje wszystkie 5 serwerów i zlicza ile razy pojawiły się
poszczególne wartości,
zwraca jest ta wartość, której liczba wystąpień wyniesie lub
przekroczy 3.
Wprowadzenie do baz NoSQL
27/68
Równoważenie czasów reakcji i spójności
Różnie określając wartość progu odczytu można równoważyć czas reakcji i
spójność:
próg ustawiony na 1 - minimalny czas reakcji, najszybsza odpowiedź, większe
ryzyko niespójności,
próg ustawiony na 5 - gwarancja spójnego odczytu, wyniki zwracane dopiero
po zaktualizowaniu wszystkich replik, możliwy długi czas odczytu.
Wprowadzenie do baz NoSQL
28/68
Równoważenie czasów reakcji i trwałości
Trwałość oznacza zdolność zachowania danych przez dłuższy czas.
Operacja zapisywania jest zakończona, kiedy dane zostaną zapisane w minimalnej
liczbie replik.
Różnie określając wartość progu zapisu można równoważyć czas odpowiedzi i
trwałość:
próg ustawiony na 1 - zapis uznany za komplenty przy zapisaniu danych już
na jednym serwerze (szybka odpowiedź ale łatwiej o utratę takich danych),
próg ustawiony na 5 - maksymalna trwałość ale długi czas reakcji.
W praktyce próg zapisu równy przynajmniej 2 zapewnia trwałość i nie wydłuża
czasu zapisu. Liczba replik powinna być większa niż próg.
Wprowadzenie do baz NoSQL
29/68
Bazy relacyjne a NoSQL
Niezmienne królowanie baz relacyjnych przez ostatnie 20 lat.
Lata 90 - chwilowa moda na bazy obiektowe.
Czy bazy NoSQL zajmą stałe miejsce w środowisku?
Plusy na korzyść baz relacyjnych:
dane w organizacji mają znacznie dłuższy czas niż same aplikacje,
stabilny magazyn danych, który jest zrozumiały i dostępny z poziomu
wielu platform programistycznych.
Wprowadzenie do baz NoSQL
30/68
Zalety i wartość baz relacyjnych
Zalety i wartość baz relacyjnych:
trwałe przechowywanie dużych ilości danych,
SZBD zawiera dużo narzędzi wspierających dostęp, manipulowanie i
wyszukiwanie danych,
współbieżność - jednoczesna praca wielu użytkowników, czasem nawet
na tym samym fragmencie danych - transakcje,
integracja - współpraca różnych aplikacji i zespołów pracowników
przez współdzieloną bazę danych,
ustandaryzowany model - każdy specjalista może z łatwością
pracować na różnych bazach relacyjnych,
ustandaryzowany język SQL.
Wprowadzenie do baz NoSQL
31/68
Wady baz relacyjnych
Wady baz relacyjnych:
dane przechowywane w tabelach i wierszach (relacje i krotki),
krotki zawierają tylko proste dane, żadnych zagnieżdżonych struktur,
dane przechowywane w sposób znormalizowany (wada ale i zaleta),
niezgodność impedancji - inny model danych w bazie, a inne dane w
programie czy w ogóle w strukturze pamięci.
Wprowadzenie do baz NoSQL
32/68
Wady baz relacyjnych
Niezgodność impedancji złagodzona dzięki mapowaniu obiektowo
relacyjnemu. Nie jest to rozwiązanie doskonałe...
Po roku 2000 bazy relacyjne nadal królują ... ale zaczęły się pojawiąc nowe
technologie - NoSQL.
Wprowadzenie do baz NoSQL
33/68
Bazy integracji i aplikacji
Relacyjne bazy danych jako bazy integracji:
integracja różnych aplikacji i zespołu pracowników,
jedna baza - dane przetwarzane przez wiele aplikacji,
zapewnienie spójnego zestawu trwałych danych,
skomplikowana struktura bazy, wymaga koordynacji większości zmian.
Baza danych jako baza aplikacji:
dostęp tylko jednej aplikacji, zarządzanej przez specjalny zespół,
tylko zespół zna strukturę bazy - łatwość i bezpieczeństwo zmian,
odpowiedzialność za integralność danych w kodzie aplikacji,
współpraca między aplikacjami - Web Services,
komunikacja za pośrednictwem http,
dane agregacyjne w formacie XML czy JSON.
Wprowadzenie do baz NoSQL
34/68
Bazy integracji i aplikacji
Baza aplikacji:
może działać z dowolnym silnikiem bazy danych (baza NoSQL albo
relacyjna),
na zewnątrz udostępnia tylko usługi, interfejs,
nie jest bezpośrednio dostępna na zewnątrz - większe bezpieczeństwo.
Mimo takiej swobody większoś baz aplikacyjnych działa na bazach
relacyjnych.
Wprowadzenie do baz NoSQL
35/68
Termin NoSQL a rzeczywistość
Od pojawienia się baz NoSQL bazy relacyjne są jedną z opcji do wyboru,
nie są jedynym wyborem.
Bazy NoSQL najlepiej nadają się jako bazy aplikacji - enkapsulacja baz
danych w usługi.
Transakcje ACID z baz relacyjnych przeszkadzają w działaniu na
klastrze.
Bazy NoSQL nie zapewniają transakcji, udostępniają inne sposoby
zachowania spójności i dystrybucji.
Bazy grafowe nie są projektowane do działania na klastrach, są
zbliżone do baz relacynych, mają jednak zupełnie inny model danych.
Działają bez schematu danych, można dowolnie dodawać pola do
rekordów w bazie. Nie wymaga to zmiany struktury bazy.
Wprowadzenie do baz NoSQL
36/68
Skutki upowszechnienia baz NoSQL
Zmiany na rynku baz danych:
Bazy relacyjne nadal będą najważniejsze ale nie będą już jedynymi.
Początek poliglotycznego przechowywania danych,
dane przechowywane w różnych modelach
Przedsiębiorcy i pojedyncze aplikacje korzystający z wielu technologii
przechowywania danych.
Projektanci i programiści baz danych:
musza znać bazy post-relacyjne ale też bazy NoSQL,
potrafić ocenić, który model jest bardziej odpowiedni do danego
zadania.
Podjęcie właściwej decyzji wymaga dostatecznego poziomu wiedzy o obu
modelach danych.
Wprowadzenie do baz NoSQL
37/68
Model danych
Model danych to model za pomocą którego przeglądamy dane i
manipulujemy nimi.
Model przechowywania opisuje, w jaki sposób dane są przechowywane
i manipulowane wewnętrznie.
Model danych:
konkretny model danych aplikacji, np. konkretny diagram encji,
przede wszystkim model, zgodnie z którym baza organizuje dane metamodel.
Wprowadzenie do baz NoSQL
38/68
Model danych NoSQL a model relacyjny
Dominujący model relacyjny:
zestaw tabel (relacji),
wiersze odpowiadają encji,
encja to zestaw kolumn, każda ma wartość i określony typ,
związki między tabelami (klucze główne i obce) - relacje
NoSQL:
wprowadza odejście do modelu relacyjnego,
każdy model NoSQL jest inny, wyróżniamy cztery kategorie,
3 podobne modele (zorientowane na agregacje): klucz-wartość,
dokument i rodzina kolumn.
Wprowadzenie do baz NoSQL
39/68
Podział baz NoSQL ze względu na model danych
Model danych
Klucz - wartość
Dokument
Przykładowe bazy
BerkeleyDB
Memcached
Project Voldemort
Redis
Riak
CouchDB
MongoDB
OrientDB
RavenDB
Terrastore
Model danych
Rodzina kolumn
Przykładowe bazy
Amazon SimpleDB
Cassandra
HBase
Hypertable
Bazy grafowe
FlockDB
HyperGraphDB
Infinite Graph
Neo4J
OrientDB
Niektóre bazy danych pasują do więcej niż jednej kategorii. Inne są na
granicy kategorii.
Pełana lista baz NoSQL (i nie tylko) na stronach:
http://nosql-database.org/
http://nosql.mypopescu.com/kb/nosql
Wprowadzenie do baz NoSQL
40/68
Dane w modelu zorientowanym na agregacje
Ograniczenia krotek w modelu relacyjnym:
są tylko prostym zestawem wartości, nie można ich zagnieżdżać.
Model zorientowany na agregacje:
operujemy na na złożonych strukturach,
takie złożone struktury nazwiemy agregacją,
Agregacje:
można myśleć jako o rekordach, które zawierają inne rekordy czy listy,
kolekcja obiektów traktowana jako jednostka,
taką jednostkę, agregację przechowujemy, przesyłamy i poprzez nią
manipulujemy na danych.
ułatwiają pracę w klastrach - są naturalną jednostką do replikacji i
współdzielenia.
Wprowadzenie do baz NoSQL
41/68
Relacyjny model danych
Przykład ze sprzedażą towarów użytkownikowi:
Wprowadzenie do baz NoSQL
42/68
Relacyjny model danych
Dane w bazie relacyjnej po normalizacji:
Żadne dane się nie powtarzają, jest integralność referencyjna.
Wprowadzenie do baz NoSQL
43/68
Model danych zorientowany na agregacje
w klientach
{
"id":28,
"nazwa":"Jan Kowalski",
"adresPlatnika": [{"miejscowosc":"Częstochowa"}]
}
w zamówieniach
{
"id":99,
"klientId":28,
"pozycjeZamowienia": [
{
"produktId":25,
"cena": 32.45,
"produktNazwa": "NoSQL Databases"
}
],
"adresWysylki": [{"miejscowosc":"Częstochowa"}],
"zamowieniePlatnosc": [
{
"numerKarty":"1500-1200",
"NIP": "2345678901",
"adresPlatnika": {"miejscowosc":"Częstochowa"}
}
]
}
Wprowadzenie do baz NoSQL
44/68
Model danych oparty o agregacje
Przykład ze sprzedażą towarów użytkownikowi:
Wprowadzenie do baz NoSQL
45/68
Model danych oparty o agregacje
Przykład ze sprzedażą towarów użytkownikowi
Dwie podstawowe agregacje: klient i zamówienie.
Lista adresów w kliencie, adres ustalony na dzień zakupów.
Zamówienie zawiera listę pozycji zamówienia, płatności oraz adres
wysyłki.
Płatność zawiera wykorzystany adres płatnika.
Pojedynczy adres pojawia się trzy razy! Nie potrzebne jest ID adresu.
Adres płatności i wysyłki nie ulegają zmianie.
Połączenie między klienetem a zamówieniami poprzez ID klienta należy odczytać z relacji między agregacjami.
Wprowadzenie do baz NoSQL
46/68
Wszystkie zamówienia w agregacji klienta
w klientach
{
"id": 28,
"nazwa": "Jan Kowalski",
"adresPlatnika": [{"miejscowosc": "Częstochowa"}],
"zamowienia": [
{
"id": 99,
"klientId": 28,
"pozycjeZamowienia": [
{
"produktId": 25,
"cena": 32.45,
"produktNazwa": "NoSQL Databases"
}
],
"adresWysylki": [
{"miejscowosc": "Częstochowa"}
],
"zamowieniePlatnosc": [
{
"numerKarty": "1500-1200",
"NIP": "2345678901",
"adresPlatnika": {"miejscowosc": "Częstochowa"}
}
]
}
]
}
Wprowadzenie do baz NoSQL
47/68
Inne wyznaczenie granic agregacji
Przykład ze sprzedażą towarów użytkownikowi:
Wprowadzenie do baz NoSQL
48/68
Wybór sposobu podziału na agregacje
Podział modelu danych na agregacje:
zależy od sposobu, w jaki będziemy na nich manipulowali,
pierwszy model - pobieranie osobno każdego zamówienia,
drugi model - pobieranie klientów ze wszystkimi ich zamówieniami.
Wprowadzenie do baz NoSQL
49/68
Konsekwencje orientacji na agregacje
Model relacyjny - agregacje realizowane przez klucze obce.
Relacje agregacji nie różną się od pozostałych relacji.
Model relacyjny ignoruje agregacje.
Bazy zorientowane na agregacje:
znacznie prostsza semantyka danych,
semantyka zależy od sposobu wykorzystania danych przez aplikację,
skupiamy się na interakcji z magazynem danych.
Agregacje również są ignorowane przez bazy grafowe.
Model ignorujący agregacje pozwala na łatwe przeglądanie danych w
dowolny sposób.
Wprowadzenie do baz NoSQL
50/68
Model agregacyjny i transakcje
Bazy relacyjne:
zapewniają obsługę transakcji (ACID),
można manipulować dowolnymi wierszami w różnych tabelach bez
obawy uzyskania niespójności.
Bazy NoSQL:
nie wspierają transakcji ACID obejmujących kilka agregacji,
wspierają atomowe operacje w ramach jednej agregacji,
jednoczesna manipulacja na wielu agregacjach wymaga zapewnienia
atomowiści w kodzie aplikacji,
należy tak projektować, aby utrzymać potrzeby atomowoego dostępu
do danych w ramach jednej agregacji.
Wprowadzenie do baz NoSQL
51/68
Modele klucz-wartość i dokumentów - cechy wspólne
Bazy klucz-wartość i dokumentów:
w głównej mierze oparte na agregacjach, zawierają dużą ich liczbę,
dostęp do każdej agregacji odbywa się za pomocą
klucza/identyfikatora, który ją wskazuje.
Wprowadzenie do baz NoSQL
52/68
Modele klucz-wartość i dokumentów - różnice
Bazy klucz-wartość:
dane są przezroczyste dla bazy - są nic nie znaczącym zbiorem bitów,
pozwalają przechowywać co tylko się chce,
jedynym ograniczeniem jest rozmiar,
dostęp do danych tylko za pośrednictwem klucza.
Bazy dokumentów:
rozumieją struktury przechowywanych agregacji,
ograniczają to, co można w nich przechowywać, poprzez definicję
dopuszczalnych struktur i typów,
większa elastyczność w dostępnie do danych:
wysyłanie zapytań w oparciu o pola agregacji,
pobieranie tylko części agregacji,
tworzenie indeksów na podstawie zawartości agregacji.
Wprowadzenie do baz NoSQL
53/68
Modele klucz-wartość i dokumentów
W paktycye różnice między bazami klucz-wartość i dokumentów częściowo
się zacierają:
pole z identyfikatorem w bazie dokumentów jako dostęp typu
klucz-wartość,
niektóre bazy klucz-wartość pozwalają:
dodawać metadane do przechowywanych wartości na potrzeby
indeksowania i relacji między agregacjami (Riak),
rozbijanie agregacji do poziomu list czy zestawów (Redis),
dodawanie wsparcia dla wykonywania zapytań.
W bazach danych klucz-wartość spodziewamy się pobierania danych
przede wszystkim za pomocą klucza.
W bazach dokumentów wykonujemy najczęściej pewnego rodzaju
zapytanie na bazie wewnętrznej struktury dokumentu.
Wprowadzenie do baz NoSQL
54/68
Model rodziny kolumn
Jednostka przechowywania to:
wiersz - najczęstszy przypadek,
grupa kolumn - kiedy rzadko występuje zapis, a często odczytujemy
kilka kolumn z wielu wierszy.
Najlepiej patrzeć na model rodzina kolumn jako:
dwuwymiarową mapę,
tabelę z luźnym schematem kolumn.
Bazy przechowujące grupy kolumn (rodziny kolumn) nazywamy bazami
rodziny kolumn.
Wprowadzenie do baz NoSQL
55/68
Model rodziny kolumn - przykład
Dwupoziomowa struktura agregująca
Pierwszy klucz - wiersz, wybór agregacji (mapa bardziej szczegółowych wartości).
Drugi klucz - kolumna.
Pobieranie
cały wiersz: get(’1234’)
Wprowadzenie do baz NoSQL
wybrana kolumna: get(’1234’, ’nazwa’)
56/68
Model rodziny kolumn
Myślenie o strukturze baz rodziny kolumn przez pryzmat wiersza:
patrzymy na całą agregację, jeden wiersz - jedna agregacja, np. klient
o id 1234,
rodziny kolum w danym wierszu reprezentują użyteczne części danych
wewnątrz tej agregacji, np. profil klienta, historia zamówień,
Myślenie o strukturze baz rodziny kolumn przez pryzmat kolumn:
każda rodzina kolumn definiuje typ rekordu, np. profil klienta, z
wierszami dla każdego z rekordów,
wiersz funkcjonuje jako połączenie rekordów ze wszystkich kolumn.
Wprowadzenie do baz NoSQL
57/68
Model rodziny kolumn
Bazy rodziny kolumn:
kolumny są organizowane w rodziny,
każda kolumna musi być częścią pojedynczej rodziny,
rodzina kolumn funkcjonuje jako jednostka dostępu,
dana rodzina kolumn jest za zwyczaj pobierana razem.
Rodzina kolumn:
pozwala dodawać dowolne kolumny do wierszy,
wiersze mogą mieć bardzo różne zestawy kolumn,
nowe kolumny można dodawać do wierszy w trybie normalnego
dostępu do danych,
zdefiniowanie nowej rodziny kolumn może wymagać zatrzymania bazy
danych.
Wprowadzenie do baz NoSQL
58/68
Podsumowanie modeli zorientowanych na agregacje
Cechy wspólne trzech modeli (klucz-wartość, dokument, rodzina kolumn):
Agregacje indeksowane za pomocą klucza, pozwalającego na jej
pobranie.
Cała agregacja jest przechowywana na jednym serwerze - podstawa
działania modeli tego typu w klastrach.
Agragacja jako jednostka atomowa podczas aktualizacji danych użyteczna choć ograniczona kontrola transakcyjna.
W ramach pojęcia agregacji uwidaczniają się różnice pomiędzy
omówionymi trzema typami danych.
Wprowadzenie do baz NoSQL
59/68
Podsumowanie modeli zorientowanych na agregacje
Najważniejsze kwestie:
Agregacja jest zestawem danych, które funkcjonują w bazie jako
jednostka.
Bazy klucz-wartość, dokumentów i rodzyny kolumn to bazy
zorientowane na agregacje.
Dzięki agregacjom przechowywanie danych w klastrach jest łatwiejsze.
Bazy zrorientowane na agregacje najlepiej działają, kiedy interakcje z
danymi są podejmowane w ramach jednej agregacji.
Wprowadzenie do baz NoSQL
60/68
Inne aspekty modelowania danych
Dane w bazie połączone relacjami
W wielu przypadkach dobrze jest, żeby baza danych wiedziała o
połączeniach między danymi.
W bazach klucz-wartość są mechanizmy, które pozwalają na
definiowanie takich relacji.
Przy dużej liczbie połączeń wybieramy zazwyczaj model relacyjny, ale
on też nie jest tutaj dostatecznie dobry.
Bazy grafowe są wyspecjalizowane w dużej liczbie relacji.
Bazy grafowe to też NoSQL.
Wprowadzenie do baz NoSQL
61/68
Bazy grafowe
Wprowadzenie do baz NoSQL
62/68
Bazy grafowe
Powstały „dzięki” kiepskiej obsłudze rozbudowanych relacji w modelu
relacyjnym.
Dane w bazie grafowej to węzły połączone krawędziami.
W bazach grafowych mamy do czynienia z niewielkimi rekordami i
rozbudowanymi połączeniami między nimi.
Węzły zawierają mało informacji, jest bardzo rozbudowana sieć
połączeń.
Zbudowany graf (węzły i krawędzie) można odpytywać.
Możliwe zapytania: znajdź książki z kategori „bazy danych” napisane
przez kogoś, kogo lubi ktoś z moich znajomych.
Idealna struktura do przechowywania danych zawierających
skomplikowane powiązania (np. sieci społecznościowe).
Wprowadzenie do baz NoSQL
63/68
Bazy grafowe
Kosztowne złączenia w bazach relacyjnych - tanie w bazach
grafowych (zysk trafersowania po grafie kosztem wolniejszego
wstawiania danych).
Nadanie indeksów niektórym węzłom pozwala na określenie miejsca
początkowego (zaytanie „sprawdź osoby o imionach Anna i Barbara”).
Zapytania przechodzące po krawędziach, np. „pokaż mi wszystkie
rzeczy, które lubią Anna i Barbara”.
Duży nacisk na relacje powoduje dużą odmienność od baz
zrorientowanych na agregacje.
Częściej działają na pojedynczym serwerze niż na klastrze.
Udostępniają transakcje ACID.
Cechy wspólne z bazami NoSLQ:
odrzucenie modelu relacyjnego,
wzrost polularności w tym samym czasie co inne bazy NoSQL.
Wprowadzenie do baz NoSQL
64/68
Bazy bez schematu - plusy
Plusy baz danych bez schematu
Bazy relacyjne muszą mieć schemat żeby działać (tabele, kolumny, typy
danych ...). Bazy NoSQL najcześciej nie.
W każdym z modeli baz NoSQL można przechowywać dowolne dane
w dowolnym miejscu. Jest duża elastyczność i wolność.
Zmiana schematu w bazie relacyjnej przy istniejących danych nie jest
taka prosta.
Baza może się zmieniać w miarę rozwoju aplikacji czy działania usługi.
W każdej chwili można łatwo dodać nowe pola, kolumny, czy też
usuną już nie potrzebne. Nie ma schematu...
Łatwiej przechowywać też dane niestandardowe, np. różne liczby
kolumn w różnych rekordach.
Nie trzeba tworzyć na zapas pustych fikcyjnych kolumn, np.
dodatkowa1.
Wprowadzenie do baz NoSQL
65/68
Bazy bez schematu - minusy
Problemy przy bazach danych bez schematu
Program korzystający z naszej bazy musi znać nazwy kolum czy kluczy. Musi
znać typy danych.
Pola: osobaTelefon i telefonOsoby to nie to samo.
Trzeba wiedzieć czy po kluczem licznik znajdują się liczby czy może znaki
alfabetu...?
Wniosek: prawie zawsze korzystamy z jakiegoś domniemanego schematu choć
może on być tylko w aplikacji.
Posiadanie domniemanego schematu w kodzie aplikajci - trzeba przeglądać
kod żeby poznać strukturę bazy.
Bardzo dużo zależy od jakości kodu - czasem może być ciężko coś odczytać.
Baza danych nie uznaje schematu - nie da się walidować danych.
Dla kilku różnych aplikacji ta sama baza może zupełnie inaczej
funkcjonować.
Brak schematu nie pozwala określić jak lepiej przechowywać i pobierać dane.
Wprowadzenie do baz NoSQL
66/68
Bazy bez schematu
Schematy są wartościowe.
Odrzucenie schematów przez NoSQL jest dużą nowością.
Jeśli mamy dane nieposiadające jasno określonego schematu - warto
wykorzystać NoSQL.
Jeśli z bazy NoSQL korzysta kilka aplikacji każda z nich może mieć w
kodzie inny domnienamy schemat. Rozwiązania:
Bazę NoSQL możana „opakować” (enkapsulacja) przez jedną
aplikację, która udostepni dane wszystkim innym - usługi sieciowe.
Różne wydzielone obszary bazy/agragacji dla różnych aplikacji z niej
korzystających.
Brak schematu w NoSQL występuje tylko w granicy agregacji. Zmiana
granic agregacji jest tak skomplikowana jak zmiana schematu w bazach
relacyjnych.
Wprowadzenie do baz NoSQL
67/68
Źródła
W wykładzie wykorzystano materiały:
Pramod J. Sadlage, Martin Folwer, NoSQL Kompendium wiedzy,
Helion, 2015
Dan Sulivan, NoSQL Przyjazny przewodnik, Helion 2016
https://dzone.com/articles/better-explaining-cap-theorem
Wprowadzenie do baz NoSQL
68/68