Bazy danych_wstęp_oprac.Ewa A.Paulo
Baza danych to zbiór informacji zapisanych w ściśle określony sposób w
strukturach odpowiadających założonemu modelowi danych. W potocznym ujęciu
obejmuje dane oraz program komputerowy wyspecjalizowany do gromadzenia i
przetwarzania tych danych.
Program taki (często zestaw programów) nazywany jest „Systemem Zarządzania Bazą
Danych” (ang. DataBase Management System - DBMS). W ścisłej nomenklaturze baza
danych oznacza zbiór danych, który zarządzany jest przez system DBMS.
System Zarządzania Bazą Danych, SZBD (ang. DataBase Management System DBMS) nazywany też Serwerem Baz Danych lub Systemem Baz Danych - SBD – to
oprogramowanie bądź system informatyczny służący do zarządzania komputerowymi bazami
danych. Systemy baz danych mogą być sieciowymi serwerami baz danych lub udostępniać
bazę danych lokalnie.
Bazy danych operują głównie na danych tekstowych i liczbowych, lecz większość
współczesnych baz umożliwia przechowywanie danych binarnych typu: grafika, muzyka
itp.
SQL (ang. Structured Query Language) to strukturalny język (informatyka) zapytań używany
do tworzenia, modyfikowania baz danych oraz do umieszczania i pobierania danych z baz
danych.Język SQL jest językiem deklaratywnym. Decyzję o sposobie przechowywania i
pobrania danych pozostawia się systemowi zarządzania bazą danych DBMS.
Jest to język zapytań opracowany w latach siedemdziesiątych w firmie IBM. Stał się on
standardem w komunikacji z serwerami relacyjnych baz danych. Wiele współczesnych
systemów relacyjnych baz danych używa do komunikacji z użytkownikiem SQL, dlatego mówi
się, że korzystanie z relacyjnych baz danych, to korzystanie z SQL-a. Pierwszą firmą, która
włączyła SQL do swojego produktu komercyjnego, był Oracle. Dalsze wprowadzanie SQL-a, w
produktach innych firm, wiązało się nierozłącznie z wprowadzaniem modyfikacji pierwotnego
języka.
Rodzaje baz danych
Bazy danych można podzielić według struktur danych, których używają:
I. Bazy proste:
1. Kartotekowe
2. Sieciowe
3. Hierarchiczne
II. Bazy złożone:
1. Relacyjne
2. Obiektowe
3. Relacyjno-obiektowe
4. Strumieniowe
5. Temporalne
6. Zaopatrzeniowe
Bazy kartotekowe - każda tablica danych jest samodzielnym dokumentem i nie może
współpracować z innymi tablicami. Z baz tego typu korzystają liczne programy typu: książka
telefoniczna, książka kucharska, spisy książek, kaset i inne. Wspólną cechą tych baz jest ich
zastosowanie w jednym wybranym celu.
Sieciowe bazy danych - charakteryzują się największą dowolnością powiązań; nie
opierają się praktycznie na żadnych regułach - każda jednostka informacji może być
powiązana z dowolną liczbą pozostałych.
1
Bazy danych_wstęp_oprac.Ewa A.Paulo
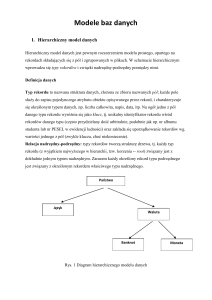
Hierarchiczne bazy danych - to struktury danych złożone z relacji, w których istnieje
pojedyncza jednostka macierzysta i wiele jej podległych. Przeszukiwanie takich zbiorów
informacji polega na schodzeniu po drzewie zależności, a następnie przeszukiwaniu go wszerz
na poszczególnych poziomach. Przykładem hierarchicznej bazy danych jest opracowana przez
IBM baza IMS (ang. Information Management System).
Bazy relacyjne - w bazach relacyjnych wiele tablic danych może współpracować ze sobą (są
między sobą powiązane). Bazy relacyjne posiadają wewnętrzne języki programowania,
wykorzystujące zwykle SQL do operowania na danych, za pomocą, których tworzone są
zaawansowane funkcje obsługi danych. Relacyjne bazy danych (jak również przeznaczony dla
nich standard SQL) oparte są na kilku prostych zasadach:
1. Wszystkie wartości danych oparte są na prostych typach danych.
2. Wszystkie dane w bazie relacyjnej przedstawiane są w formie dwuwymiarowych tabel
(w matematycznym żargonie noszących nazwę „relacji”). Każda tabela zawiera zero lub
więcej wierszy (w tymże żargonie – „krotki”) i jedną lub więcej kolumn („atrybutów”). Na
każdy wiersz składają się jednakowo ułożone kolumny wypełnione wartościami, które z
kolei w każdym wierszu mogą być inne.
3. Po wprowadzeniu danych do bazy, możliwe jest porównywanie wartości z różnych
kolumn, zazwyczaj również z różnych tabel, i scalanie wierszy, gdy pochodzące z nich
wartości są zgodne. Umożliwia to wiązanie danych i wykonywanie stosunkowo
złożonych operacji w granicach całej bazy danych.
4. Wszystkie operacje wykonywane są w oparciu o algebrę relacji, bez względu na
położenie wiersza tabeli. Nie można, więc zapytać o wiersze, gdzie (x=3) bez wiersza
pierwszego, trzeciego i piątego. Wiersze w relacyjnej bazie danych przechowywane są
w porządku zupełnie dowolnym - nie musi on odzwierciedlać ani kolejności ich
wprowadzania, ani kolejności ich przechowywania.
5. Z braku możliwości identyfikacji wiersza przez jego pozycję pojawia się potrzeba
obecności jednej lub więcej kolumn niepowtarzalnych w granicach całej tabeli,
pozwalających odnaleźć konkretny wiersz. Kolumny te określa się jako „Klucz
podstawowy” (ang. primary key) tabeli.
Bazy obiektowe - dane w nich są przechowywane w strukturach obiektowych
(zdefiniowanych jako klasy). Koncepcje akademickie dotyczące baz obiektowych były
popularne w latach 90., obecnie prace nad nimi są w zaniku.
Bazy relacyjno-obiektowe - pozwalają na manipulowanie danymi jako zestawem obiektów,
posiadają jednak bazę relacyjną jako wewnętrzny mechanizm przechowywania danych.
Strumieniowa baza danych - dane są przedstawione w postaci zbioru strumieni danych.
System zarządzania taką bazą nazywany jest strumieniowym systemem zarządzania danymi
(DSMS - ang. Data Stream Management System).
Większość strumieniowych baz danych w chwili obecnej (początek 2005r.) znajduje się w
fazach prototypowych i nie powstały dotychczas rozwiązania komercyjne.
Strumieniowe bazy danych z reguły implementują języki ciągłych zapytań opartych na SQL-u
(istnieją jednak wyjątki od tej reguły - np. rozwiązania graficzne).
Temporalna baza danych - jest odmianą bazy relacyjnej, w której każdy rekord posiada
stempel czasowy, określający czas, w jakim wartość jest prawdziwa. Posiada także operatory
algebry relacyjnej, które pozwalają operować na danych temporalnych (wyciągać historię).
2
Bazy danych_wstęp_oprac.Ewa A.Paulo
Niezbędne mechanizmy
Środki do gromadzenia, utrzymywania i administrowania trwałymi i masowymi zbiorami
danych,
Środki zapewniające spójność i bezpieczeństwo danych,
Sprawny dostęp do danych (zwykle poprzez język zapytań, np. SQL),
Środki programistyczne służące do aktualizacji/przetwarzania danych (API dla
popularnych języków programowania),
Jednoczesny dostęp do danych dla wielu użytkowników (z reguły realizowany poprzez
transakcje),
Środki pozwalające na regulację dostępu do danych (autoryzację),
Środki pozwalające na odtworzenie zawartości bazy danych po awarii,
Środki do zarządzania katalogami, schematami i innymi metadanymi,
Środki optymalizujące zajętość pamięci oraz czas dostępu (np. indeksy),
Środki do pracy lub współdziałania w środowiskach rozproszonych.
Dodatkowe mechanizmy:
Zarządzanie wersjami i danymi nietrwałymi,
Przechowywanie i udostępnianie danych multimedialnych,
Wygodne (wizyjne) środowiska do tworzenia aplikacji,
Pomosty do współpracy z innymi systemami,
Wspomaganie dla perspektyw, procedur składowanych i aktywnych reguł,
Pakiety statystyczne, pakiety dla przeprowadzania analiz (eksploracji danych),
Pakiety do tworzenia hurtowni danych,
Środki udostępniające bazę danych w sieci Internet, itd.
SZBD działające w architekturze klient-serwer
Większość obecnie spotykanych systemów działa w trybie klient-serwer, gdzie baza danych
jest udostępniana klientom przez SZBD będący serwerem. Serwer baz danych może
udostępniać dane klientom bezpośrednio lub przez inny serwer pośredniczący (np. serwer
WWW lub aplikacji).
Systemy bazy danych w architekturze klient-serwer to m.in.:
DB2
Informix Dynamic Server
Firebird
Microsoft SQL Server
MySQL
Oracle
PostgreSQL
Bezserwerowe SZBD
Czasem jednak stosowanie serwera nie jest konieczne. Istnieją bazy danych, które nie muszą
być współdzielone przez wielu użytkowników w tym samym czasie.
Do takich zastosowań używane są bezserwerowe bazy danych takie jak:
Access korzystająca z silnika Microsoft Jet
Kexi korzystająca z silnika SQLite
3
Bazy danych_wstęp_oprac.Ewa A.Paulo
RELACYJNA BAZA DANYCH
Poprzez RELACYJNĄ BAZĘ DANYCH rozumiemy uporządkowany zbiór danych
przechowywanych w pamięci komputera. Dane są wprowadzane i zapamiętywane w formie
strukturalnej. Oznacza to, że są one zgrupowane w pewne struktury.
Elementarna struktura w bazie danych nazywa się REKORDEM (ang. record) i może być
przedstawiona w postaci pełnego rzędu zawierającego wszystkie potrzebne informacje o
jednym podmiocie bazy danych (np. Janie Kowalskim).
Zbiór wielu rekordów nazywamy PLIKIEM. Każdy rekord składa się z szeregu pól
informacyjnych, które mogą przyjmować postać kolumny z rodzajem informacji wspólnym dla
każdego z podmiotów danych (np. data urodzenia, data zatrudnienia, zarobki itp.).
Nagłówek
pola
Nr ewidencyjny
Nazwisko
pacjenta
Imię
Data przyjęcia Rozpoznanie
11-04-2003
1
Kowalski
Jan
2
Nowak
Małgorzata 24-06-2003
3
Wiśniewska Teresa
30-06-2003
zapalenie płuc
4
Nowak
7-08-2003
odra
Grzegorz
grypa
żółtaczka
Rekord
Pole
Jednostką informacji są relacje.
Relacja zawiera może zawierać:
• Atrybuty (pola) danych
• Klucz podstawowy – jednoznacznie identyfikujący wpis w bazie
• Klucz obcy służący do tworzenia związku z inną relacją
Podstawowe pojęcia
1. Pole – podstawowy element bazy danych
2. Rekord – grupa pól
3. Plik – grupa rekordów zawierających podobne informacje
4. Encja – grupa danych o podobnych właściwościach (np.pacjenci, wyniki badań
laboratoryjnych)
5. Kwerenda – zapytanie do bazy danych
6. DBMS – system wspomagający użytkownika w operacjach zapamiętywania i
odzyskiwania danych
7. DBMS izoluje programy użytkownika od systemu plików
Zadania DBMS
1. Operacje zachowywania, modyfikacji, odzyskiwania danych
2. Przekształcanie zewnętrznego modelu danych do pojęciowego
3. Przekształcanie modelu pojęciowego do fizycznego
4. Sprawdzanie reguł integralności i spójności danych
5. Kontrola dostępu
6. Kontrola współbieżności
7. Zabezpieczanie danych (transaction logging)
4
Bazy danych_wstęp_oprac.Ewa A.Paulo
Kontrola danych
1. Kontrola współbieżności
2. Kontrola dostępu
3. Kontrola spójności i integralności danych
4. Przetwarzanie transakcji
5. Bezpieczeństwo danych
Moduły są to zbiory procedur i funkcji napisane w języku Access Basic.
KLUCZ PODSTAWOWY
Klucz podstawowy jest najważniejszym ze wszystkich kluczy. To on reprezentuje całą
tabelę w bazie danych. Musi też spełniać wszystkie te same kryteria, co klucz
kandydujący. Dzięki niemu możliwe jest tworzenie relacji pomiędzy tabelami. Klucz
podstawowy wybieramy spośród kluczy kandydujących.
Zasady definiowania klucza podstawowego:
1. Każda tabela powinna posiadać dokładnie jeden klucz podstawowy (kluczy kandydujących
może być kilka);
2. Wszystkie klucze podstawowe w bazie danych muszą się od siebie różnić - dwie tabele nie
mogą posiadać identycznego klucza podstawowego.
KLUCZ OBCY
Klucz obcy wykorzystywany jest do tworzenia relacji pomiędzy parą tabel. Jest on kombinacją
jednego lub więcej atrybutów przedstawionych w dwóch lub większej liczbie relacji.
Model relacyjny oparty jest na tylko jednej podstawowej strukturze danych -- relacji. Pojęcie
relacji można uważać za pewną abstrakcję intuicyjnego pojęcia tabeli, zbudowanej z wierszy i
kolumn, w której na przecięciu każdej kolumny z każdym wierszem występuje określona
wartość.
Baza danych jest zbiorem relacji, o następujących własnościach:
Każda relacja w bazie danych jest jednoznacznie określona przez swoją nazwę.
Każda kolumna w relacji ma jednoznaczną nazwę (w ramach tej relacji).
Kolumny relacji tworzą zbiór nieuporządkowany. Kolumny nazywane bywają również
atrybutami.
Wszystkie wartości w danej kolumnie muszą być tego samego typu. Zbiór możliwych
wartości elementów danej kolumny nazywany bywa też jej dziedziną.
Również wiersze relacji tworzą nieuporządkowany zbiór; w szczególności, nie ma
powtarzających się wierszy. Wiersze relacji nazywa się też encjami.
Każde pole (przecięcie wiersza z kolumną) zawiera wartość atomową z dziedziny
określonej przez kolumnę. Brakowi wartości odpowiada wartość specjalna NULL,
zgodna z każdym typem kolumny (chyba, że została jawnie wykluczona przez definicję
typu kolumny).
Każda relacja zawiera klucz główny -- kolumnę (lub kolumny), której wartości
jednoznacznie identyfikują wiersz (a więc w szczególności nie powtarzają się).
Wartością klucza głównego nie może być NULL.
Do wiązania ze sobą danych przechowywanych w różnych tabelach używa się kluczy
obcych.
Klucz obcy to kolumna lub grupa kolumn tabeli, o wartościach z tej samej dziedziny, co klucz
główny tabeli z nią powiązanej. Np. baza danych instytucji składającej się z wielu zakładów
może zawierać tabele zakłady i pracownicy: tabela zakłady zawiera m. in. kolumny
kod_zakladu (klucz główny), nazwa, adres, kierownik,...; a tabela pracownicy: kolumny nr_prac
(klucz główny), nazwisko, zakład, pokój, telefon, email,...; kolumna zakłady.kierownik może być
kluczem obcym odnoszącym się do kolumny pracownicy.nr_prac; zaś kolumna
5
Bazy danych_wstęp_oprac.Ewa A.Paulo
pracownicy.zakład - kluczem obcym odnoszącym się do zakłady.kod_zakładu, etc. Unika się w
ten sposób powielania tych samych danych w różnych tabelach, co m. in. ułatwia utrzymanie
zgodności pomiędzy zawartością bazy danych a stanem faktycznym.
Encja (entity) – to pewna rzecz; obiekt materialny lub niematerialny, pojęcie, fakt, zdarzenie itp,
o której chcemy przechowywać informacje. Encja posiada pewne charakterystyczne dla siebie
cechy.
Grupa danych o podobnych właściwościach (np. pacjenci, wyniki badań
laboratoryjnych.
Przykładem encji będącej obiektem materialnym może być np. samochód (wraz z cechami,
np.: model, nr fabryczny, kolor, zużycie paliwa), osoba (imię, nazwisko, adres, nr pesel), a
niematerialnym np. konto bankowe (numer, posiadacz, dopuszczalny debet, saldo),
zdarzeniem – wysłanie towaru (data wysłania, nazwa towaru, symbol, nazwa i adres
odbiorcy), faktem – znajomość języka (nazwa języka, czas nauki, stopień znajomości).
Atrybut (attribute) - sposób przypisania właściwości elementom w dokumencie. Atrybut
posiada nazwę oraz wartość. Definiując strukturę dokumentu przy pomocy DTD lub XML
Schema, określa się nazwy, typy oraz domyślne wartości atrybutów niezależnie dla
poszczególnych elementów.
Atrybut encyjny (entity attribute) - atrybut zadeklarowany przy pomocy słowa kluczowego
ENTITY, służący do umieszczania odwołań do encji nieprzetwarzanych. Deklaracja atrybutu
encyjnego określa notację, z którą zawartość encji nieprzetwarzanej powinna być zgodna.
Zgodność ta nie jest oczywiście weryfikowana przez procesor XML. Notacja określona w
deklaracji jest jedynie wskazówką dla aplikacji przetwarzającej, jakiego formatu zawartości
encji nieprzetwarzanej może oczekiwać.
Element (element) - podstawowa jednostka logicznej struktury dokumentu XML. Cały
dokument XML ma postać jednego elementu głównego (root element). Zawartością elementów
są: tekst oraz inne elementy. Struktura elementów jest kodowana w dokumencie przy pomocy
znaczników.
Encja (entity) – 1. Jednostka fizycznej budowy dokumentu, pozwalająca na jego elastyczną
organizację, np.: wielokrotne wykorzystywanie tych samych fragmentów tekstu, dołączanie
fragmentów dokumentu z zewnętrznych plików, itp. Encja posiada swoją nazwę oraz
zawartość. 2. Fizyczna reprezentacja obiektu informacyjnego przechowywanego w systemie
(np. jako plik lub pole w bazie danych), lub tworzonego w locie przez program. Uogólnienie
pojęcia plik.
Encja nieprzetwarzana (unparsed entity) - encja zewnętrzna, która nie jest przetwarzana
przez procesor XML. Encje nieprzetwarzane są zwykle używane do formułowania odwołań do
grafiki, dźwięku i innych obiektów binarnych, które nie mogą być bezpośrednio umieszczone w
dokumencie XML. Odwołania do encji nieprzetwarzanych koduje się przy pomocy atrybutów
encyjnych.
Encja ogólna (general entity) - każda encja, która nie jest encją parametryczną. Encje ogólne
są używane w treści dokumentów.
Encja parametryczna (parameter entity) - encja, zadeklarowana przy pomocy specjalnej
składni, która może być używana wyłącznie w DTD, najczęściej w celu wielokrotnego
wykorzystania tych samych fragmentów definicji w wielu miejscach.
6
Bazy danych_wstęp_oprac.Ewa A.Paulo
Encja predefiniowana (predefined entity) - encja, do której można się odwoływać bez jej
wcześniejszego zadeklarowania. Pięć encji predefiniowanych pozwala używać w dokumentach
XML znaków zastrzeżonych dla składni XML, np. encja &lt; reprezentuje znak <.
Encja przetwarzana (parsed entity) - encja (wewnętrzna lub zewnętrzna), której zawartość
jest przetwarzana przez procesor XML w miejscu wystąpienia odwołania do encji na równi z
pozostałą zawartością dokumentu. Interpretacja odwołania do encji przetwarzanej polega na
zastąpieniu odwołania przez zawartość encji.
Encja wewnętrzna (internal entity) - encja (ogólna lub parametryczna), której zawartość jest
podana w miejscu jej deklaracji.
Encja zewnętrzna (external entity) - encja (ogólna lub parametryczna, przetwarzana lub nie),
której wartość pobierana jest z systemu (np. z pliku, z Internetu), z miejsca określonego
identyfikatorem zewnętrznym.
Identyfikator publiczny (public identifier) - identyfikator zewnętrzny poprzedzony słowem
kluczowym PUBLIC, definiujący położenie obiektu przy pomocy ustalonego, unikatowego
ciągu znaków, który nie zależy od miejsca przechowywania obiektu w konkretnym systemie.
Aplikacje wspierające wykorzystanie identyfikatorów publicznych znajdują położenie obiektu
dzięki konfiguracji określającej położenie obiektów o danych identyfikatorach publicznych.
Identyfikator systemowy (system identifier) - identyfikator zewnętrzny poprzedzony słowem
kluczowym SYSTEM, definiujący położenie obiektu przy pomocy URI.
Identyfikator zewnętrzny (external identifier) - ciąg znaków definiujący odwołanie do obiektu
znajdującego się poza encją, w której występuje. Wyróżniamy identyfikatory systemowe oraz
publiczne.
Instrukcja przetwarzania (processing instruction) - konstrukcja składniowa niewchodząca w
skład struktury hierarchicznej dokumentu XML, niewymagająca deklarowania w DTD ani w
dokumencie, interpretowana w całości przez aplikację przetwarzającą dokument. Instrukcje
przetwarzania służą do kodowania - poza strukturą elementów - poleceń lub informacji
przeznaczonych dla konkretnej aplikacji. Składnia informacji zawartych w instrukcji
przetwarzania jest dowolna. Ich interpretacja zależy od aplikacji, dla której instrukcja jest
przeznaczona (identyfikowanej przy pomocy podmiotu instrukcji przetwarzania).
7