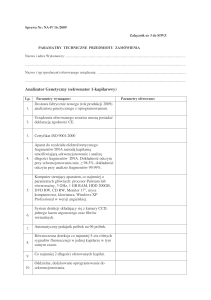
Implementacja sieci
neuronowych na karcie graficznej
Waldemar Pawlaszek
Motywacja
Czyli po co to wszystko?
Motywacja
Procesor graficzny
GPU (Graphics Processing Unit)
• Wydajność
• Elastyczność i precyzja
Motywacja
Wydajność
• 3 GHz Pentium 4
teoretycznie: 6 GFLOPs
• GeForce FX 5900
Zaobserwowano: 20 GFLOPs
• GeForce 6800 Ultra
Zaobserwowano: 40 GFLOPs
Motywacja
Wydajność
•
CPU
•
Roczny wzrost mocy ~1.5x / dziesięciolecie ~60x
(Prawo Moora)
•
GPU
•
Roczny wzrost mocy >2x / dziesięciolecie ~1000x
(Znacznie szybciej niż prawo Moora)
Motywacja
Wydajność
Dlaczego GPU jest wydajniejszy?
•
•
Specjalizacja
Ekonomia
Motywacja
Elastyczność
•
Potok graficzny jest wysoce
programowalny
•
Programowanie w językach wysokiego
poziomu
Motywacja
Precyzja
•
32-bitowe obliczenia
zmiennoprzecinkowe w całym potoku
Wady
•
•
•
Trudne w użyciu
GPU jest zaprojektowany do obliczeń
graficznych
Obliczenia są z natury równoległe
Kody z CPU nie można po prostu
„przeportować”
Wady
Trudne w użyciu
(częściowy ratunek)
BrookGPU
http://graphics.stanford.edu/projects/brookgpu/
Zapewnia abstrakcje od warstwy graficznej
Przykłady
GPGPU
Programowanie ogólnego przeznaczenia
wykorzystując sprzęt graficzny
http://www.gpgpu.org/
Architektura
Procesor graficzny służy do rysowania
prymitywów w prostokątnym obszarze
pamięci
•
•
•
Punkty
Proste
Trójkąty
Dwie jednostki
•
Jednostka wierzchołków
oblicza docelowe pozycje
i parametry prymitywów
•
Jednostka fragmentów
oblicza wartość
dla każdego elementu prymitywu
Przebieg rysowania
Wierzchołki po
transformacjach
Składanie
prymitywów
Rasteryzacja
Interpolacja
danych
wierzchołków
Program
wierzchołków
Przebieg rysowania
Wierzchołki po
transformacjach
Składanie
prymitywów
Wykonywany
raz na wierzchołek
Rasteryzacja
Program
fragmentów
Interpolacja
danych
wierzchołków
Wykonywany
raz na fragment
Schemat potoku rysującego
Interpolacja
danych
Aplikacja
Program
wierzchołków
Dane z bufora
wierzchołków
Program
fragmentów
Dane z tekstur
Bufor
docelowy
To tylko rysowanie.
Jak to może nam pomóc w obliczeniach?
Cała moc tkwi w procesorze fragmentów:
Możemy generować jedną macierz
(bufor docelowy)
na podstawie wielu macierzy wejściowych
(tekstur)
To tylko rysowanie.
Jak to może nam pomóc w obliczeniach?
Dla każdego pola macierzy docelowej
wywoływany jest osobny program
mogący zapisywać tylko do tego pola.
Jak to wygląda w praktyce?
Procesorem wierzchołków nie interesujemy
się za bardzo.
(0,1)
(1,1)
Konfigurujemy go, aby rysował
dwa trójkąty o takich
współrzędnych, aby zapełnić
cały bufor docelowy.
oraz
(0,0)
(1,0)
aby przekazywał na wejście
procesora fragmentów pozycję
obliczanego punktu
Przykład prostego kodu fragmentów
void main (float2 vPos
:TEXCOORD0,
out float4 oColor :COLOR0)
{
oColor = float4(vPos, 0, 0);
}
Przykład prostego kodu fragmentów
sampler s0;
void main (float2 vPos
:TEXCOORD0,
out float4 oColor :COLOR0)
{
oColor = tex2D(s0, vPos);
}
Przykład prostego kodu fragmentów
sampler s0;
void main (float2 vPos
:TEXCOORD0,
out float4 oColor :COLOR0)
{
oColor = 1 - tex2D(s0, vPos);
}
Przykład prostego kodu fragmentów
sampler s0;
void main (float2 vPos
:TEXCOORD0,
out float4 oColor :COLOR0)
{
oColor = tex2D(s0, vPos * 2);
}
Przykład prostego kodu fragmentów
sampler s0;
sampler s1;
void main (float2 vPos
out float4 oColor
{
if (vPos.x < 0.5)
oColor = tex2D(s0,
else
oColor = tex2D(s1,
}
:TEXCOORD0,
:COLOR0)
vPos);
vPos);
Przykład prostego kodu fragmentów
sampler s0;
sampler s1;
void main (float2 vPos
:TEXCOORD0,
out float4 oColor :COLOR0)
{
oColor = tex2D(s0, vPos)
+ tex2D(s1, vPos);
}
Co można obliczać?
• Kod procesora fragmentów może zawierać
praktycznie dowolne operacje
zmiennoprzecinkowe
• Na wejściu można ustawić do 16 tekstur
• Ograniczeniem jest limit instrukcji
W najnowszych kartach wynosi on 512 instrukcji. Można
jednak robić pętle i podprocedury. Limit instrukcji
wykonywanych dla jednego fragmentu to 65535
Co można obliczać?
Procesor fragmentów może operować na wielu
formatach danych:
• 8-bitowe liczby naturalne widziane jako liczby z
przedziału 0.0 – 1.0
• 16-bitowe liczby zmiennoprzecinkowe
• 32-bitowe liczny zmiennoprzecinkowe
A teraz sieci neuronowe
sumator
funkcja aktywacji
np. funkcja sigmoidalna
W sieciach jednokierunkowych
•
•
•
Wyjście każdego neuronu obliczane jest niezależnie
Obliczenia sprowadzają się do wymnożenia macierzy
przez wektor (i dodania biasu) oraz zaaplikowania do
wyniku nieliniowej funkcji aktywacji
Przy wielu danych wejściowych obliczenia możemy
złożyć do mnożenia macierzy
Wagi jako macierz
M – ilość wyjść (ilość neuronów w warstwie)
N – ilość wejść (wielkość danych wejściowych)
Dane wejściowe jako macierz
L – ilość danych wejściowych (wektorów wejściowych)
N – ilość wejść (wielkość danych wejściowych)
Bias jako macierz
M – ilość wyjść (ilość neuronów w warstwie)
Wynik sumatora
Ogólny przebieg mnożenia macierzy
Kod dla pojedynczego fragmentu
(w uproszczeniu)
sampler sX;
sampler sW;
sampler sB;
float N, beta;
void main (float2 vPos
: TEXCOORD0,
out float4 oColor : COLOR0)
{
float s = 0;
for (int i = 0; i < N; i++)
s += tex2D(sX, float2(vPos.x, i/N))
* tex2D(sW, float2(i/N, vPos.y));
s += tex1D(sB, pos.y);
oColor.x = 1/(1+exp(beta*s));
}
Co w przypadku wielu warstw?
• Wynikiem działania procesora fragmentów jest
bufor, który można użyć jako tekstury.
• Wystarczy zastosować kilka przebiegów.
Jakieś wyniki?
Kyoung-Su Oh i Keechul Jung
w pracy
„GPU implementation of neural networks”
podają, że karta
RADEON 9700 PRO
liczyła 20-razy szybciej niż procesor
(Ale nie podali jaki)
Jakieś wyniki?
Teoretyczne wyliczenia szybkości obliczeń nie
uwzględniają często ilości czytań z tekstury
(które jednak jest kosztowne) oraz czasu
potrzebnego na załadowanie danych do karty
graficznej oraz odebrania wyników (z tym jest
coraz lepiej: PCI-E).
Dla zainteresowanych
http://developer.nvidia.com
http://developer.ati.com
http://www.gpgpu.org
Inne ciekawe obliczenia na GPU
Symulacja płynów metodą
Naviera-Stokesa
~120 fps
przy rozmiarach 256x256
na GeForce 6800 Ultra
Inne ciekawe obliczenia na GPU
Symulacja oddziaływań
N-Ciał
Metoda Brute force
N = 4096 cząsteczek
N2 obliczeń grawitacji
16M obliczeń siły / ramke
~25 instrukcji
zminnoprzecinkowych na siłę
17 ramek na sekundę