Wstęp do Baz Danych
Rodzaje baz danych
Obecnie na rynku istnieje wiele baz danych
produkowanych w oparciu o różne technologie i często
zupełnie różnie konstruowanych. Z najbardziej
popularnych można wymienić następujące:
dBase
FilePro (tylko do odczytu)
Informix
InterBase
FrontBase
mSQL
Direct MS-SQL
MySQL
ODBC
PostgreSQL
Co to są bazy danych?
Baza danych to po prostu logicznie poukładane dane.
Bazą danych jest na przykład
System plików na komputerze.
książka adresowa w programie pocztowym.
Bazy danych używane są w bankach i większych przedsiębiorstwach do
przechowywania informacji o kontach czy też danych personalnych.
Ze względu na rozwój komputeryzacji dość profesjonalne i
niekoniecznie małe, bazy danych są obecne również u przeciętnego
użytkownika komputera. Przechowywanie danych w bazach odbywa
się w określony, logiczny sposób. Dzięki temu zaspokojony jest
jeden z podstawowych celów tworzenia bazy danych, a mianowicie
logiczny i szybki dostęp do danych.
Modele systemów baz danych
W latach sześćdziesiątych i siedemdziesiątych XX wieku ujrzało światło
dzienne wiele pomysłów na rozwiązanie problemu powtarzających się
danych. W wyniku różnych eksperymentów powstało kilka modeli systemów
baz danych. Większość z nich zrodziła się w firmie IBM. Jednak sam
problem magazynowania danych i szybkiego do niego dostępu istniał już
znacznie wcześniej, jednak rozwiązywany był przy pomocy bardzo
prymitywnych pomysłów. Podstawowe modele systemów baz danych
można podzielić następująco:
modele proste, gdzie dane są zorganizowane np. w postaci systemu plików.
modele klasyczne: hierarchiczny, sieciowy i relacyjny. Ten ostatni jest obecnie
najbardziej popularną podstawą obecnych systemów baz danych.
modele semantyczne czyli znaczeniowe. Klasyczne modele danych nie
dostarczają łatwego sposobu odczytania informacji o semantyce danych, stąd
podejmuje się próby stworzenia innych modeli, uzupełniających ten brak.
Przykładem częściowej realizacji tego programu są obiektowe modele danych.
Model prosty
Model prosty odpowiada strukturze katalogów w
systemie operacyjnym. Dlatego też, taki system plików
można uważać za prostą bazę danych.
Poniższy przykład prezentuje płaską bazę danych, gdzie
kluczem podziału jest znak średnika:
1;Noc na ziemi;Jim Jarmush
2;Psy;Władysław Pasikowski
3;Ptaki;Alfred Hitchcock
4;Siedem;David Fincher
5;Człowiek z Żelaza;Andrzej Wajda
6;Arizona Dream;Emir Kusturica
7;Chata wuja Toma;Stan Lathan
8;Pulp Fiction;Quentin Tarantino
Płaskie bazy danych mają bardzo
wiele wad:
Jeśli separatorem pól danych są znaki
specjalne, to oznacza to, że w zawartości pól nie
może wystąpić taka sekwencja znaków, która
normalnie rozdziela pola rekordów. Wybrnąć z
tego można tylko w jeden sposób: należy
zdefiniować naprawdę unikalny ciąg znaków,
który rozdziela pola rekordów. Jednak taka
definicja w dalszej perspektywie jest mało
prawdopodobna, gdyż i tak może się zdarzyć, że
w przyszłości ktoś wprowadzi do takiej bazy
dane, które normalnie dzielą dane na pola.
Wady baz płaskich
Jeśli kluczem do podziału pól danych jest ściśle zdefiniowana
długość pól danych, to istnieje dość ograniczony zasięg do definicji
danych, gdyż pole o ograniczonej długości może pomieścić tylko
dane o ograniczonej długości. Takie ograniczenie może w
przyszłości spowodować obcinanie danych do określonej w
programie długości danych, w przypadku, kiedy do bazy zostaną
wprowadzone dane o długości większej niż przewidziane wcześniej
przy projektowaniu bazy danych. Jedynym rozwiązaniem jest tutaj
zdefiniowanie wcześniej odpowiednio długiego pola, tak, aby w
przyszłości nie było możliwe nigdy przekroczenie wymaganej
długości. Jednak takie postępowanie powoduje, że dane, które
normalnie zajmują bardzo niewiele miejsca (gdyż są to krótkie ciągi
tekstowe) w takiej bazie danych, w której na zapas zdefiniowano dla
danych więcej miejsca, mogą zajmować kilkakrotnie więcej miejsca
niż by musiały zajmować ze względu na swoją długość.
Wady baz płaskich
Dane w bazach płaskich mogą być wyłącznie
ciągiem znaków. Co prawda dla niektórych
języków programowania nie stwarza to żadnego
problemu (patrz język Perl czy PHP), jednak dla
jęzków niższego poziomu oznacza to częste
wywoływanie funkcji konwertujących napisy do
liczb, czy dat i odwrotnie
Wady baz płaskich
Ponieważ dane są zapisywane w postaci
tekstowej, zatem zajmują dość sporo miejsca.
Nie ma tutaj żadnej kompresji ani szybkiego
dostępu do danych już skompresowanych
Dane w bazach są zorganizowane
sekwencyjnie. Oznacza to konieczność dostępu
sekwencyjnego, czyli bardzo powolnego i
zasobożernego. Każde nowe rekordy są
natomiast dopisywane na koniec danych.
Wady baz płaskich
Nie ma praktycznie żadnego ograniczenia
dostępu do danych takiej bazy danych. Każda
tablica jest po prostu jednym plikiem tekstowym.
Ograniczać dostęp można więc tylko z poziomu
systemu operacyjnego, co przy niektórych
zabezpieczeniach systemów operacyjnych budzi
poważne wątpliwości dotyczące bezpieczeństwa
danych.
Wady baz płaskich
Nie ma żadnego ograniczenia w kolejności dostępu do
takiej bazy danych. Można sobie wyobrazić, że jeśli do
takiej bazy danych dostęp miałaby więcej niż jedna
osoba, wtedy istnieje duże prawdopodobieństwo
niekonsystencji danych, gdyż podczas gdy jedna osoba
chciałaby czytać pewne dane, inna może chcieć je w tym
momencie usunąć. Jest to dość niebezpieczna sytuacja;
nie ma określonych priorytetów i tzw. zamykania na jakiś
czas dostępu do danych.
Nie ma zdefiniowanych relacji między danymi, zatem
dane mogą się niepotrzebnie wielokrotnie powtarzać.
Relacyjne Bazy Danych
Relacyjna baza danych jest to zbiór dwuwymiarowych
tabel. Z modelem relacyjnym powiązane są następujące
pojęcia:
tabela,
kolumna,
wiersz,
pole.
Model relacyjny opiera się na pojęciach zaczerpniętych z
algebry. Pojęcia te to:
relacja,
operator działający na relacjach i dający w wyniku relacje.
Relacje przedstawiane są w postaci tabel, zaś
wybieranie danych z tabel to wynik działania operatorów
relacyjnych na tych tabelach.
Tabela
ID_K
Autor_n
Autor_i
Tytuł
ISBN
Opis_A
Stan
1
Mickiewicz
Adam
Pan
Tadeusz
123465
Jeden
z…..
W
2
Sienkiewicz
Henryk
Ogniem i
Mieczem
124512
…..
W
3
Sienkiewicz
Henryk
Krzyżacy
124512
…….
N
Tabela - książki
ID_K
ID_A
Tytuł
ISBN
Opis_K
Stan
1
1
Pan Tadeusz
123465
……..
W
2
2
Ogniem i Mieczem
124512
………
W
3
2
Krzyżacy
124512
…….
N
4
5
Tabela - Autor
ID_A
Autor_I
Autor_N
Opis_A
1
Adam
Mickiewicz
……..
2
Henryk
Sienkiewicz
………
3
4
5
Operatory relacyjne
SELEKCJA
pobieranie danych z relacji, w wyniku otrzymujemy
wszystkie wiersze, które spełniają zadany warunek
PROJEKCJA
operacja pobrania wszystkich wierszy, ale tylko
wskazanych kolumn z tych wierszy
ILOCZYN
KARTEZJAŃSKI
wynik połączenia każdy z każdym wierszy z dwóch
relacji
ZŁĄCZENIE
połączenie dwóch relacji poprzez pewne kryterium
łączące niektóre wiersze z obu relacji
SUMA ZBIOROWA
wszystkie wiersze z obu relacji
CZĘŚĆ WSPÓLNA
wiersze wspólne dla obu relacji
RÓŻNICA ZBIOROWA
wiersze, które występują w jednej, a nie występują w
drugiej relacji
Własności relacyjnej bazy danych
Relacyjna baza danych ma następujące
własności:
baza jest widziana przez użytkownika jako zbiór tabel,
nazwy tabel w bazie muszą być unikalne,
tabele składają się wierszy i kolumn,
językiem służącym do operowania na bazie danych
jest język nieproceduralny oparty na algebrze relacji.
Obecnie standardem jest SQL lub jego modyfikacje
Np. MySQL.
Własności tabel w relacyjnej bazie
danych
wiersze w tabeli muszą być różne,
w tabeli nie ma kolumn o tej samej nazwie,
kolejność wierszy jest nieokreślona,
kolejność kolumn jest nieokreślona,
wartości pól powinny być elementarne np., pole
Adres: 35-111 Rzeszów, ul Asnyka 23 powinno
być rozbite na trzy pola:
KOD,
UL,
NR_DOMU
SQL
SQL – Structured Query Language
Język komunikacji użytkownika z oprogramowaniem
zarządzającym relacyjnymi bazami danych
Ujęty w normie ANSI/ISO w roku 1986
Aktualizacje: SQL-89, SQL-92
SQL
SQL jest oparty na wyrażeniach języka angielskiego.
Jest językiem deklaratywnym —podajemy tylko, co
należy wykonać, ale nie specyfikujemy w jaki sposób.
Język SQL służy do następujących celów:
specyfikowania zapytań,
operowania danymi — wstawiania, modyfikowania i usuwania
danych z bazy danych,
definiowania danych — dodawania do bazy nowych obiektów,
(tabele, kolumny)
sterowania danymi — określania praw dostępu do danych.
SQL
Zapisywanie poleceń SQL
Polecenia SQL mogą być rozmieszczone w kilku
liniach. Koniec polecenia SQL zaznacza się
średnikiem.
Zaleca się umieszczanie klauzul (nowe polecenie) od
nowej linii.
Można używać tabulacji (w celu poprawienia
czytelności zapisu).
Nie wolno dzielić słowa pomiędzy linie.
Obojętne, czy używamy małych czy wielkich liter,
chyba że sprawdzamy zawartość bazy danych
(operatory porównania)
SQL - odmiany
Język SQL danej bazy, np. mySQL, zawiera:
polecenia SQL ujęte w standardzie
rozszerzenia standardu – polecenia specyficzne dla
konkretnego systemu baz danych
Rodzaje poleceń SQL
Polecenia SQL dotyczą:
tworzenia i usuwania baz danych, tabel, kluczy
wprowadzania, uaktualniania i usuwania danych
wyszukiwania danych
ustawiania praw dostępu do danych
administracji bazą danych
zarządzania transakcjami
Instalowanie bazy danych
Najwygodniej zainstalować jeden z dostępnych
pakietów zawierających
Serwer www np. Apache
Język skryptowy PHP
Bazę danych Mysql
Kryterium to spełnia np. pakiet „wampserver”
Wprowadzanie komend SQL
Sposób wprowadzania do bazy poleceń SQL:
w programie działającym z linii poleceń
(np. MySQL monitor)
w programie z graficznym interfejsem użytkownika
(np. MySQL Navigator)
w skryptach i programach komunikujących się z bazą
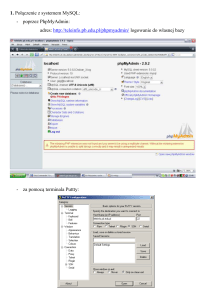
danych (np. skrypty PHP - np. phpmyadmin)
pośrednio, przy użyciu graficznego interfejsu
użytkownika (np. Access)
Tworzenie bazy danych –
MySQL
Sposób utworzenia bazy danych w MySQL:
uruchomienie programu: mysql
utworzenie bazy:
CREATE DATABASE nazwa;
przełączenie się do bazy:
USE nazwa;
teraz można utworzyć tabele – utworzenie tabeli wymaga
podania nazw pól (kolumn) oraz ich typów.
Najważniejsze polecenia SQL
Zestaw najważniejszych poleceń SQL to
CREATE - utwórz
SELECT – wybierz dane wg kryteriów
INSERT – wstaw dane
DELETE – usuń dane
UPDATE – uaktualnij dane
SQL – liczby i napisy
Łańcuchy znaków (string): 'napis' lub "napis"
użycie backslasha (\): 'napis \'03'
Liczby całkowite: 1221; 0; -32
Liczby zmiennoprzecinkowe: 294.42;
-32032.6809e+10
Liczby szesnastkowe: np. 1000 = 3E8
Każda liczba jest mnożnikiem kolejnej potęgi liczby stanowiącej podstawę
systemu, np. 1000, w hex przybiera postać 3E8, gdyż:
3×162 + 14×161 + 8×160 = 768 + 224 + 8 = 1000.
Wartość pusta:
NULL
Typy danych
Typy danych MySQL – liczby całkowite:
TINYINT (1 bajt) (liczby od -128 .. 127 lub 0..256 „unsigned”)
SMALLINT (2 bajty) (liczby od -32768 .. 32767)
MEDIUMINT (3 bajty) (-8388608 .. 8388607)
INT (4 bajty) (-2147483648 .. 2147483647)
BIGINT (8 bajtów) (-9223372036854775808 .. 9223372036854775807)
Dodatkowe atrybuty:
UNSIGNED – liczba bez znaku
ZEROFILL – dopełnienie zerami
(M) – wyświetlenie M cyfr
Typy danych
Typy danych MySQL – liczby
zmiennoprzecinkowe:
FLOAT (n) – pojedyncza precyzja, n liczb
DOUBLE (M,D) – podwójna precyzja
DECIMAL (M,D) – liczba zapisywana jako tekst
Dodatkowe atrybuty:
UNSIGNED – liczba bez znaku
ZEROFILL – dopełnienie zerami
(M) – wyświetlenie M cyfr
(M,D) – wyświetlenie M cyfr, D cyfr po przecinku
Typy danych
Typy danych MySQL – data i czas:
DATETIME – data + czas (2003-10-15 15:00:12)
DATE – data (2003-10-15)
TIME – czas (15:00:12)
YEAR – rok (2003 lub 03)
TIMESTAMP (n) – znacznik czasu (n – liczba znaków); data
wstawiana do bazy danych w momencie wykonywania jakiejś
operacji
Typy danych
Typy danych MySQL – łańcuchy tekstowe:
CHAR (n) – stała długość n (max. 255)
VARCHAR (n) – zmienna długość, max. n (do 255)
TINYTEXT, TEXT, MEDIUMTEXT, LONGTEXT
– dane tekstowe ASCII
Inne typy danych:
TINYBLOB, BLOB, MEDIUMBLOB, LONGBLOB
– dane binarne
ENUM – typ wyliczeniowy (tylko jedna z wartości dopuszczonych)
SET – zbiór wartości (w kolumnie może znajdować się podzbiór
wartości dopuszczonych tzn. kilka wartości.)
Tworzenie tabel
Utworzenie tabeli wymaga podania nazw pól
(kolumn) oraz ich typów.
CREATE TABLE albumy2 (
id
INT NOT NULL,
wykonawca
VARCHAR(30),
tytuł
VARCHAR(30),
rok
YEAR,
liczba_utw SMALLINT,
opis
TEXT
);
Wstawianie danych do tabeli
Wstawianie danych z podaniem wszystkich
kolumn tabeli (należy zachować kolejność!)
INSERT INTO albumy
VALUES (1, ‘Pink Floyd’, ‘The Division Bell’,
1994, 11, ‘Ostatni studyjny album’);
Wstawianie danych do wybranych kolumn tabeli
INSERT INTO albumy (id, album, wykonawca)
VALUES (2, ‘The Wall’, ‘Pink Floyd’);
Wyszukiwanie danych
Wyszukiwanie danych w tabeli – instrukcja
SELECT
Ogólna postać instrukcji SELECT:
SELECT które_kolumny
FROM z_której_tabeli
WHERE które_rekordy;
Wyrażenie logiczne po instrukcji WHERE
zawiera kryteria, które musi spełnić rekord, aby
znaleźć się w wynikach wyszukiwania.
Wyszukiwanie danych
Najprostsza postać instrukcji SELECT
SELECT * FROM albumy;
Wyszukiwanie:
w tabeli albumy
wszystkich pól (kolumn) – „*”
wszystkich rekordów (wierszy) – brak warunku
WHERE
Wyszukiwanie – wybór kolumn
Wyszukiwanie danych – wyświetlenie wybranych kolumn
SELECT rok, tytuł, wykonawca FROM albumy;
W ten sposób można uzyskać powtarzające się wyniki:
SELECT wykonawca FROM albumy;
Eliminacja powtórzeń wyników:
SELECT DISTINCT wykonawca FROM albumy;
Wyszukiwanie – wybór wierszy
Wyszukiwanie rekordów spełniających zadany
warunek - instrukcja WHERE
SELECT tytuł FROM albumy
WHERE wykonawca = 'Pink Floyd';
SELECT wykonawca, rok FROM albumy
WHERE tytuł = 'The Best Of' AND rok <
1970;
Operatory
Operatory używane w instrukcji SELECT ...
WHERE:
porównania: = < > <= >=
logiczne: NOT ! AND && OR ||
XOR
!= oznacza różny – nie równy
IS NULL, IS NOT NULL
expr BETWEEN min AND max
(NOT BETWEEN)
expr IN (lista) (NOT IN) (Np. IN(‘Warszawa’, ‘Lublin’)
SELECT * FROM albumy
WHERE wykonawca IN ('Pink Floyd', ‘Dire Straits')
AND (rok < 1975 OR rok BETWEEN 1979 AND 1983);
Symbole wieloznaczne
Symbole wieloznaczne używane w instrukcji WHERE:
%
_
zastępuje dowolny ciąg znaków
zastępuje jeden znak
Operator symboli wieloznacznych: LIKE, NOT LIKE
Wyrażenia regularne – operator REGEXP (MySQL)
SELECT * FROM albumy
WHERE wykonawca LIKE 'The %s';
SELECT * FROM albumy
WHERE album NOT LIKE 'The Best in 197_';
Sortowanie wyników
Sortowanie wyników wg zadanej kolumny:
ORDER BY pole – w porządku rosnącym
ORDER BY pole ASC – jw.
ORDER BY pole DESC – w porządku malejącym
SELECT * FROM albumy
ORDER BY rok DESC, wykonawca;
Grupowanie wyników
Tworzenie zestawień przez grupowanie wyników:
użycie funkcji, np. COUNT, SUM, MAX, MIN, AVG
nazwanie kolumny z wynikami (opcjonalnie) – AS
zgrupowanie wyników – GROUP BY
Przykład – obliczenie ilości albumów wszystkich
wykonawców:
SELECT wykonawca, COUNT(*) FROM albumy
GROUP BY wykonawca;
SELECT wykonawca, COUNT(*) AS ilosc FROM albumy
GROUP BY wykonawca ORDER BY ilosc DESC;
Grupowanie wyników
Ograniczenie rekordów uzyskanych w wyniku
grupowania - operator HAVING
Przykład – obliczenie ilości albumów wszystkich
wykonawców, wyświetlenie tylko tych, którzy
mają więcej niż 5 albumów:
SELECT wykonawca, COUNT(*) AS ilosc FROM albumy
GROUP BY wykonawca
HAVING ilosc > 5;
Ograniczenie liczby wyników
Ograniczenie liczby zwracanych wyników –
LIMIT
LIMIT n – n pierwszych wyników
LIMIT m,n – n wyników, pomijając m pierwszych
Przykład: 10 wykonawców o największej liczbie
albumów:
SELECT wykonawca, COUNT(*) AS ilosc FROM albumy
GROUP BY wykonawca
LIMIT 10;
20 następnych wyników (11-30):
SELECT wykonawca, COUNT(*) AS ilosc FROM albumy
GROUP BY wykonawca
LIMIT 10,20;
Wyszukiwanie w wielu tabelach
Pobieranie danych z więcej niż jednej tabeli
Przykład bazy danych – dwie tabele:
albumy IDA Wykonawca Album Rok
utwory
IDU Utwór Czas IDA
Gatunek
Wybranie wszystkich możliwych kombinacji
rekordów z obu tabel (iloczyn kartezjański):
SELECT * FROM albumy, utwory;
Wyszukiwanie w wielu tabelach
Uwzględnienie relacji między tabelami:
SELECT * FROM albumy, utwory
WHERE albumy.IDA = utwory.IDA;
Łączy ze sobą rekordy obu tabel mające takie same
dane w polach, które są połączone relacją:
albumy
utwory
IDA Wykonawca Album Rok
IDU Utwór
Czas IDA
Gatunek
Wyszukiwanie w wielu tabelach
Wybór kolumn:
SELECT albumy.wykonawca, albumy.album,
utwory.utwor, utwory.czas
FROM albumy, utwory
WHERE albumy.IDA = utwory.IDA;
Aliasy nazw tabel:
SELECT a.wykonawca, a.album, u.utwor, u.czas
FROM albumy a, utwory u
WHERE a.IDA = u.IDA;
Wstawianie danych – inne
metody
Wstawianie do tabeli danych uzyskanych w wyniku
zapytania:
INSERT INTO nowa (autor, dzielo)
SELECT DISTINCT wykonawca, album
FROM albumy;
Wstawianie danych z pliku na komputerze klienta (pola
rozdzielone tabulatorami, rekordy – znakiem nowej linii) komenda mySQL (nie standard):
LOAD DATA LOCAL INFILE ‘dane.txt’
INTO nowa_tabela;
Usuwanie rekordów
Usunięcie rekordów spełniających zadane kryteria
– instrukcja DELETE. Warunki takie same jak w
SELECT.
Usuwane są zawsze całe rekordy.
Przykład:
DELETE FROM albumy
WHERE wykonawca = 'Pink Floyd';
UWAGA! Te komendy czyszczą całą tabelę:
DELETE FROM albumy;
TRUNCATE TABLE albumy;
Uaktualnianie rekordów
Zmiana danych rekordów już istniejących w tabeli –
komenda UPDATE.
Nowe wartości określane są komendą SET.
Przykład:
UPDATE albumy
SET wykonawca = 'Pink Floyd'
WHERE wykonawca = 'Fink Ployd';
Ta komenda uaktualni WSZYSTKIE rekordy:
UPDATE albumy SET wykonawca = 'Pink Floyd';
Operacje na bazach danych
Tworzenie bazy danych:
CREATE DATABASE baza;
Usuwanie całej bazy:
DROP DATABASE baza;
Wyświetlenie istniejących baz danych:
SHOW DATABASES;
Przełączenie się na inną bazę danych:
USE baza;
Operacje na tabelach
Tworzenie tabeli (przykład):
CREATE TABLE tabela (id INT, nazwa VARCHAR(30));
Usuwanie tabeli:
DROP TABLE tabela;
Wyświetlenie istniejących tabel w bazie danych:
SHOW TABLES;
Wyświetlenie struktury tabeli:
DESCRIBE tabela;
Operacje na tabelach
Zmiana nazwy:
RENAME TABLE tabela TO nowa_tabela;
Zmiana struktury tabeli – ALTER TABLE
Dodanie kolumny:
ALTER TABLE tabela ADD (opis TEXT);
Usuwanie kolumny:
ALTER TABLE tabela DROP opis;
Operacje na tabelach
Modyfikacja typu kolumny (ograniczenia typu!):
ALTER TABLE tabela MODIFY opis VARCHAR(50);
Zmiana nazwy kolumny:
ALTER TABLE tabela CHANGE opis info VARCHAR(50);
Za pomocą ALTER TABLE możliwe jest również
dodawanie i usuwanie atrybutów pól.
Atrybuty pól tabeli
Przy tworzeniu lub zmianie tabeli można podać
opcjonalne atrybuty pól (kolumn) tabeli:
CREATE TABLE (pole typ atrybuty, ...);
Dostępne atrybuty:
NULL – można nie podawać wartości (domyślnie)
NOT NULL – wartość musi być podana
DEFAULT wartość – gdy nie podamy wartości
AUTO_INCREMENT – automatycznie zwiększany licznik
COMMENT 'opis' – komentarz
PRIMARY KEY, KEY – indeksy główne
AUTO_INCREMENT i
DEFAULT
AUTO_INCREMENT – nie wpisujemy danych, baza wpisuje
aktualny stan licznika i zwiększa go o 1.
DEFAULT – jeżeli nie wprowadzimy danych, zostanie wpisana
wartość domyślna
CREATE TABLE wykonawcy {
id
INT NOT NULL AUTO_INCREMENT,
wykonawca
VARCHAR(30),
opis
TEXT DEFAULT 'brak opisu'
};
INSERT INTO wykonawcy (wykonawca) VALUES ('XYZ');
Wynik: (1, 'XYZ', 'brak opisu')
TIMESTAMP
Wartością domyślną dla kolumny o typie
TIMESTAMP jest aktualny znacznik czasu (data
i czas).
Kolumna tego typu umożliwia zachowanie czasu
wprowadzenia lub ostatniej modyfikacji rekordu.
Jeżeli zostanie podana wartość – jest ona
wpisywana.
Jeżeli nie zostanie podana wartość (NULL) –
wpisywany jest znacznik czasu.
Sprawdzanie poprawności
danych
NOT NULL – w tej kolumnie muszą być wpisane dane
CHECK (wyrażenie) – dane muszą spełniać podany
warunek
CREATE TABLE dane {
nazwisko
VARCHAR(30) NOT NULL,
rok_ur
INT,
CHECK(rok_ur BETWEEN 1900 AND 2040)
};
My SQL nie obsługuje polecenia (CHECK).
Indeksowanie tabel
Na wybrane kolumny tabeli mogą być nakładane
indeksy (klucze) w celu:
przyspieszenia wyszukiwania
zdefiniowania relacji pomiędzy tabelami
Typy indeksów w MySQL:
KEY, INDEX
UNIQUE
PRIMARY KEY
FULLTEXT
Tworzenie indeksów
Tworzenie indeksu podczas definiowania tabeli –
komenda INDEX lub KEY (obie są równoważne):
KEY nazwa (kolumny)
CREATE TABLE dane {
nazwisko
VARCHAR(30) NOT NULL,
rok_ur
INT,
KEY indeks (nazwisko)
};
Indeks może obejmować wiele kolumn
Tworzenie indeksów
Tworzenie indeksu w już istniejącej tabeli:
CREATE INDEX indeks ON dane(nazwisko);
Indeks wielokolumnowy, indeksowanych 10 pierwszych
znaków pola nazwisko:
CREATE INDEX indeks
ON dane (nazwisko(10), rok_ur);
Usunięcie indeksu (nie usuwa danych!):
DROP INDEX indeks ON dane;
Wartości niepowtarzalne
UNIQUE – żadne dwa rekordy w tabeli nie mogą mieć
jednakowych danych w indeksowanej kolumnie. Jest to
jednocześnie INDEX.
Jeżeli indeksowana kolumna ma atrybut NOT NULL,
dana kolumna musi zawierać dane unikatowe i pola nie
mogą być puste.
Jeżeli indeksowana kolumna ma atrybut NULL, dane w
kolumnie muszą być unikatowe, ale mogą nie być
wprowadzane (pole może pozostać puste).
Tworzenie indeksu UNIQUE
Tworzenie indeksu podczas definiowania tabeli:
CREATE TABLE dane {
nazwisko
VARCHAR(30) NOT NULL,
pesel
CHAR(11),
UNIQUE indeks (pesel)
};
Tworzenie indeksu w istniejącej tabeli:
CREATE UNIQUE INDEX indeks ON dane (pesel);
Indeks główny
Indeks główny – PRIMARY KEY
identyfikuje jednoznacznie każdy rekord w tabeli
może istnieć tylko jeden w tabeli
jest typu UNIQUE
indeksowana kolumna otrzymuje automatycznie
atrybut NOT NULL
ma nazwę PRIMARY (nie można podać własnej)
bierze domyślnie udział w relacjach z innymi tabelami
Tworzenie indeksu głównego
Tworzenie indeksu głównego podczas definiowania
tabeli – w definicji kolumny:
CREATE TABLE dane {
nazwisko
VARCHAR(30) NOT NULL,
pesel
CHAR(11) PRIMARY KEY,
};
To samo w definicji tabel
CREATE TABLE dane {
nazwisko
VARCHAR(30) NOT NULL,
pesel
CHAR(11),
PRIMARY KEY (pesel)
};
Tworzenie indeksu głównego
Tworzenie indeksu głównego w już istniejącej tabeli:
ALTER TABLE dane ADD PRIMARY KEY (pesel);
Usuwanie indeksu głównego w tabeli (nie usuwa
danych!):
ALTER TABLE dane DROP PRIMARY KEY;
Wyszukiwanie w całym tekście
MySQL posiada specjalny typ klucza FULLTEXT, umożliwiający
wyszukiwanie informacji w polach tekstowych. Indeks ten nie
wchodzi w skład standardu SQL.
Tworzenie indeksu FULLTEXT:
CREATE TABLE albumy {
tytul
VARCHAR(30) PRIMARY KEY,
wykonawca
VARCHAR(30),
recenzja
TEXT,
FULLTEXT indeks (tytul, recenzja)
};
ALTER TABLE albumy ADD FULLTEXT ind (recenzja);
Wyszukiwanie w całym tekście
Wyszukiwanie dosłowne:
MATCH (kolumny) AGAINST (napis)
SELECT * FROM albumy
WHERE MATCH (tytul, recenzja)
AGAINST ('best of');
Dla każdego zwróconego rekordu baza oblicza wskaźnik
podobieństwa (score) – im większa liczba, tym lepsze
dopasowanie szukanego ciągu.
Znalezione rekordy są sortowane w kolejności od
najwyższego wyniku.
Wyszukiwanie w trybie
logicznym
Wyszukiwanie w trybie logicznym
– operator IN BOOLEAN MODE
Operatory wyszukiwania:
+słowo – słowo musi wystąpić
–słowo – słowo nie może wystąpić
„kilka słów" – musi wystąpić podana fraza
wyr* – słowo zaczynające się od podanych liter
() – grupowanie operatorów
~ – zaprzeczenie
Wyszukiwanie w trybie
logicznym
Przykłady:
rock jazz
+rock +jazz
+rock jazz
+rock -jazz
"rock music"
rock*
słowa rock LUB jazz
słowa rock ORAZ jazz
słowo rock musi wystąpić,
słowo jazz zwiększa score
słowo rock musi wystąpić,
słowo jazz nie może wystąpić
musi wystąpić fraza rock
music
pasują m.in. rock, rocks,
rocking
Funkcje SQL
Język SQL udostępnia szereg funkcji umożliwiających
wykonywanie operacji na danych w zapytaniach.
Funkcje:
matematyczne
tekstowe
daty i czasu
Funkcje te mogą być wykorzystywane w instrukcji
SELECT, w warunku wyboru kolumn lub w warunku
wyboru wierszy.
Funkcje SQL
Przykład stosowania funkcji w instrukcji SELECT
Funkcja UPPER() zamienia litery na wielkie.
SELECT UPPER(wykonawca) FROM albumy;
Użycie w warunku wyboru kolumn – zamienia
litery na wielkie w zwracanych danych:
SELECT * FROM albumy
WHERE UPPER(wykonawca)='U2';
Użycie w warunku wyboru rekordu – zawartość
pola po konwersji musi odpowiadać warunkowi:
Funkcje matematyczne (1)
ABS(x) – wartość bezwzględna
SIGN(x) – znak liczby (-1, 0, 1)
MOD(m,n) – reszta z dzielenia M/N
FLOOR(x) – zaokrąglenie w dół
CEIL(x) – zaokrąglenie w górę
ROUND(x) – zaokrąglenie do najbliższej l. całkowitej
m DIV n – część całkowita z dzielenia m/n
EXP(x) – ex
LN(x), LOG2(x), LOG10(x), LOG(b,x) – logarytmy
POWER(x,y) = xy
Funkcje matematyczne c.d.
SQRT(x) – pierwiastek kwadratowy
PI() – wartość
SIN(x), COS(x), TAN(x), COT(x) – funkcje trygonometr.
ASIN(x), ACOS(x), ATAN(x) – odwrotne funkcje tryg.
CRC32('wyr') – kod CRC wyrażenia wyr
RAND() – liczba losowa od 0 do 1
LEAST(x,y,...) – najmniejsza wartość z listy
GREATEST(x,y,...) – największa wartość z listy
DEGREES(x), RADIANS(x) – konwersja stopnie/radiany
TRUNCATE(x,d) – skrócenie x do d miejsc po przecinku
Funkcje tekstowe
ASCII(x) – kod ASCII znaku
ORD(x) – suma na podstawie kodów ASCII
CONV(x,m,n) – konwersja między systemami liczbowymi
BIN(x), OCT(x), HEX(x) – konwersja między systemami
CHAR(x) – ciąg złożony ze znaków o podanych kodach
CONCAT(s1,s2,...) – łączy podane napisy w jeden
CONCAT_WS(sep,s1,s2,...) – łączy napisy separatorem
LENGTH(s) – długość napisu
LOCATE(s1,s2,p) – pozycja napisu s1 w s2 (szuk. od p)
INSTR(s1,s2) – pozycja napisu s2 w s1
Funkcje tekstowe (2)
LPAD(s1,n,s2) – poprzedza s1 ciągiem s2 do długości n
RPAD(s1,n,s2) – dopisuje do s1 ciąg s2 do długości n
LEFT(s,n) – n pierwszych znaków z napisu s
RIGHT(s,n) – n ostatnich znaków z napisu s
SUBSTRING(s,m,n) – n znaków z napisu s od poz. m
SUBSTRING_INDEX(s,sep,n) – część napisu s przed
n-tym wystąpieniem separatora sep
LTRIM(s) – usuwa początkowe spacje
RTRIM(s) – usuwa końcowe spacje
TRIM(s) – usuwa początkowe i końcowe spacje
SPACE(n) – napis złożony z n spacji
Funkcje tekstowe (3)
REPLACE(s1,s2,s3) – zamień s2 na s3 w napisie s1
REPEAT(s,n) – napis z n powtórzeń s
REVERSE(s) – odwraca napis s
INSERT(s1,m,n,s2) – wstawia n znaków s2 do s1 na poz. m
ELT(n,s1,s2,...) – zwraca n-ty napis ze zbioru
FIELD(s,s1,s2,...) – zwraca indeks napisu s w zbiorze
LOWER(s) – zmienia litery na małe
UPPER(s) – zmienia litery na wielkie
LOAD_FILE(plik) – odczytuje zawartość pliku
QUOTE(s) – poprzedza znaki specjalne znakiem '\'
STRCMP(s1,s2) – porównanie dwóch napisów
Funkcje daty i czasu (1)
DATE(s) – pobiera datę z wyrażenia s
TIME(s) - pobiera czas z wyrażenia s
TIMESTAMP(s) – pobiera datę i czas z wyrażenia s
DAYOFWEEK(data) – podaje dzień tygodnia
DAYOFMONTH(data) – podaje dzień miesiąca
DAYOFYEAR(data) – podaje dzień w roku
MONTH(data) – podaje numer miesiąca
DAYNAME(data) – podaje nazwę dnia
MONTHNAME(data) – podaje nazwę miesiąca
WEEK(data) – podaje numer tygodnia (od 0)
WEEKOFYEAR(data) – podaje numer tygodnia (od 1)
Funkcje daty i czasu (2)
YEAR(data) – podaje rok
YEARWEEK(data) – podaje rok i numer tygodnia
HOUR(data) – podaje godzinę
MINUTE(data) – podaje minutę
SECOND(data) – podaje sekundę
MICROSECOND(data) – podaje ułamki sekundy
PERIOD_ADD(p,m) – dodaje m miesięcy do daty p
PERIOD_DIFF(p1,p2) – różnica dwóch dat
DATE_ADD(data, INTERVAL wyr typ)
– dodaje do daty podany czas
DATE_SUB(data, INTERVAL wyr typ) – odejmowanie daty
Funkcje daty i czasu (3)
ADDDATE(data,n) – dodaje n dni do daty
SUBDATE(data,n) – odejmuje n dni od daty
ADDTIME(s1,s2) – dodawanie czasu
SUBTIME(s1,s2) – odejmowanie czasu
EXTRACT(typ FROM data) – pobranie części daty
TO_DAYS(data) – zamienia datę na numer dnia
FROM_DAYS(n) – zamienia numer dnia na datę
DATE_FORMAT(data,format) – formatowanie daty
TIME_FORMAT(czas,format) – formatowanie czasu
Funkcje daty i czasu (4)
MAKEDATE(rok,dzień) – podaje datę
MAKETIME(godz,min,sek) – podaje czas
CURDATE() – bieżąca data
CURTIME() – bieżący czas
NOW() – bieżąca data i czas
UNIX_TIMESTAMP() – bieżąca data i czas w formacie
UNIX
SEC_TO_TIME(sek) – konwersja sekund na czas
TIME_TO_SEC(czas) – konwersja czasu na sekundy
Przykład operacji na datach
Dodawanie i odejmowanie
DATE_ADD('1997-12-31 23:59:59', INTERVAL 1 DAY);
DATE_ADD('1997-12-31 23:59:59',
INTERVAL '1:1' MINUTE_SECOND);
DATE_SUB('1998-01-02', INTERVAL 31 DAY);
Pobranie części daty
EXTRACT(YEAR FROM "1999-07-02");
Formatowanie daty
DATE_FORMAT('1997-10-04 22:23:00', '%W %M %Y');
Inne funkcje (1)
DATABASE() – nazwa bieżącej bazy danych
USER() – nazwa bieżącego użytkownika
PASSWORD(s) – koduje napis s jako hasło
ENCRYPT(s) – koduje napis s
ENCODE(s,pass) – koduje napis s przy użyciu hasła pass
DECODE(s,pass) – dekoduje napis s przy użyciu hasła pass
COMPRESS(s) – kompresja napisu s
UNCOMPRESS(s) – dekompresja napisu s
LAST_INSERT_ID() – ostatnio użyta wartość AUTO_INCREMENT
Inne funkcje (2)
FORMAT(n,d) – formatuje liczbę n do d miejsc
dziesiętnych
VERSION() – wersja bazy danych MySQL
CONNECTION_ID() – identyfikator połączenia
BENCHMARK(n,wyr) – oblicza czas wykonania
wyr (n razy)
FOUND_ROWS() – liczba rekordów z ostatniego
SELECT
Transakcje
Domyślnie wszystkie instrukcje są wykonywane od razu
po ich wprowadzeniu – zmiana danych w bazie.
W pewnych sytuacjach nie chcemy aby wykonywane
operacje modyfikowały fizyczny zbiór danych.
Tryb transakcji – wprowadzane operacje zostaną
wykonane dopiero po podaniu odpowiedniej komendy.
MySQL obsługuje kilka typów tabel, nie wszystkie
umożliwiają przeprowadzanie transakcji
Transakcje
START TRANSACTION – rozpoczęcie transakcji
Kolejne operacje są zapamiętywane, ale nie są wykonywane.
COMMIT – wykonanie operacji z całej transakcji
ROLLBACK – cofnięcie do początku transakcji
Niektóre komendy automatycznie wykonują COMMIT,
np. CREATE INDEX, DROP INDEX, DROP TABLE,
DROP DATABASE, ALTER TABLE, RENAME TABLE,
TRUNCATE
Transakcje
Możliwe jest ustawienie w trakcie transakcji punktów
zapisu za pomocą komendy
SAVEPOINT nazwa
Wykonanie komendy
ROLLBACK TO SAVEPOINT nazwa
powoduje cofnięcie do punktu zapisu o podanej nazwie
COMMIT nadal wykonuje całą transakcję.
Blokowanie tabel
W pewnych sytuacjach potrzebne jest czasowe
zablokowanie tabeli, aby inny użytkownik nie
zmodyfikował danych.
Blokowanie:
LOCK TABLES tabela1 typ, tabela2 typ, ... ;
Typ blokady:
READ – blokada do odczytu
WRITE – blokada do zapisu
Odblokowanie tabel:
UNLOCK TABLES;
Typy tabel w MySQL
MySQL obsługuje różne standardy zapisywania tabel.
Typy nie udostępniające mechanizmu transakcji:
MyISAM (domyślny), ISAM (stary), HEAP, MERGE
Typy udostępniające mechanizm transakcji i blokowania:
InnoDB, BDB
Indeks pełnego tekstu (FULLTEXT) działa tylko w
tabelach MyISAM.
Typy tabel w MySQL
CREATE TABLE tworzy domyślnie tabelę MyISAM.
Aby utworzyć tabelę innego typu, należy podać żądany
typ na końcu instrukcji:
CREATE TABLE nazwa (definicja) TYPE=InnoDB;
Zmiana typu tabeli (w praktyce utworzenie nowej tabeli,
przepisanie danych i usunięcie starej tabeli):
ALTER TABLE nazwa TYPE=InnoDB;
Autoryzacja dostępu do bazy
System zarządzania bazą danych obsługuje tzw. system
przywilejów (privilege system):
autoryzacja użytkownika łączącego się z bazą z określonego
komputera (login, hasło),
określenie praw do wykonywania poszczególnych operacji na
bazie danych (przywileje)
Przywileje są ustalane na podstawie:
nazwy użytkownika
nazwy sieciowej komputera klienta
operacji, którą chce wykonać użytkownik
Autoryzacja dostępu do bazy
Sprawdzanie przywilejów odbywa się na dwóch
poziomach
Poziom 1 – połączenie z bazą
Sprawdzanie czy użytkownik o podanej nazwie ma prawo połączyć
się z bazą z danego komputera
Poziom 2 – wykonanie operacji
Sprawdzanie czy użytkownik ma prawo wykonać żądaną operację
na danych w określonej tabeli.
Użytkownicy i hasła
Użytkownik łącząc się z bazą podaje swój identyfikator (login) oraz
hasło (jeżeli jest ustawione).
Identyfikatory i hasła bazy MySQL są niezależne od identyfikatorów
i haseł systemu operacyjnego.
Połączenie z bazą z linii poleceń systemu:
mysql -h serwer -u użytkownik -p baza_danych
Jeżeli nie podany zostanie identyfikator użytkownika, (-u)
przyjmowany jest identyfikator (login) systemowy bieżącego
użytkownika.
Opcja -p wymaga podania hasła
Nadawanie praw dostępu
Nadanie praw wykonywania określonych operacji na
danych w bazie:
GRANT przywilej (kolumny_tabeli)
ON baza_danych.tabela
TO użytkownik@host IDENTIFIED BY 'hasło';
Odbieranie praw dostępu:
REVOKE przywilej (kolumny_tabeli)
ON baza_danych.tabela
FROM użytkownik@host;
Rodzaje przywilejów
ALL – prawo do wykonywania wszystkich operacji
ALTER – zmiana def. tabeli (ALTER TABLE)
CREATE – tworzenie tabel (CREATE TABLE)
DELETE – kasowanie danych z tabeli (DELETE)
DROP – usuwanie tabel (DROP TABLE)
FILE – ładowanie danych z/do plików
INDEX – tworzenie i usuwanie indeksów
INSERT – wstawianie danych (INSERT)
SELECT – pobieranie danych (SELECT)
UPDATE – uaktualnianie danych (UPDATE)
USAGE – bez żadnych praw
Poziomy przywilejów
Przywileje dostępu do danych (ON) mogą
dotyczyć:
wszystkich baz danych na serwerze (poziom
globalny):
GRANT ... ON *.*
wszystkich tabel w określonej bazie:
GRANT ... ON baza_danych.*
określonej tabeli:
GRANT ... ON baza_danych.tabela
pojedynczych kolumn w określonej tabeli
Przywileje dla użytkowników
Przywileje dla użytkowników (TO)
użytkownik user z dowolnego komputera:
user@'%'
użytkownik user z komputera w domenie:
user@'%.eti.pg.gda.pl'
użytkownik z określonego komputera:
[email protected]
user@localhost
[email protected]
Ustawianie hasła
Domyślnie utworzony użytkownik nie posiada hasła, o ile nie użyta
zostanie opcja IDENTIFIED BY.
Ustalenie hasła przy nadawaniu praw:
GRANT ALL ON *.* TO user IDENTIFIED BY 'hasło';
Inna instrukcja do nadania hasła:
SET PASSWORD FOR user = PASSWORD('hasło');
Prawa dostępu – przykłady
Nadanie wszystkich praw do bazy forum dla użytkownika www
łączącego się z serwera
GRANT ALL ON forum.* TO www;
Nadanie wybranych praw do tabeli dane użytkownikowi robert
łączącemu się z podanej domeny
GRANT SELECT,INSERT,UPDATE ON forum.dane
TO robert@'%.eti.pg.gda.pl'
IDENTIFIED BY ‘robert_haslo';
Uwaga – ta instrukcja jest niebezpieczna!
GRANT ALL ON *.* TO joe@'%';
Administrator bazy danych
Użytkownik root ma prawo dostępu do całej bazy – jest
administratorem bazy.
Po zainstalowaniu MySQL każdy może zalogować się jako root bez
hasła. Zatem należy ustawić hasło z linii poleceń:
mysql -u root mysql;
Po połączeniu się z bazą systemową należy ustawić hasło:
SET PASSWORD FOR root = PASSWORD('tajnehaslo');
Można również użyć programu mysqladmin:
mysqladmin -u root password tajnehaslo;
Dodawanie użytkowników
Dodanie użytkownika z jednoczesnym nadaniem praw dostępu
do danych:
GRANT ALL ON baza.* TO user IDENTIFIED BY 'haslo1';
Dodanie użytkownika bez nadania praw:
GRANT USAGE ON baza.* TO user
IDENTIFIED BY 'haslo2';
Dodanie na końcu opcji WITH GRANT OPTION pozwala
użytkownikowi na przekazywanie praw innym użytkownikom.