Klucz - zestaw atrybutów (cech) których
wartości jednoznacznie wyznaczają
wiersz w tablicy
Klucz nadmiarowy – z niego możemy
usunąć jakąś cechę (kolumnę)
Klucz właściwy – z niego nie możemy
usunąć jakieś cechy gdyż przestanie
być kluczem. W definicji tabeli
wskazujemy jeden klucz właściwy
i ustawiamy go na klucz główny
Wyróżniamy klucze proste i złożone.
Jeżeli zbiór identyfikacyjny jest zbiorem
jednoelementowym to tworzy klucz
prosty, w przeciwnym wypadku klucz
jest kluczem złożonym. W relacji możemy
wyróżni wiele kluczy, które nazywamy
kluczami kandydującymi (potencjalnymi).
Wybrany spośród nich klucz nazywamy
kluczem glównym (pierwotnym), pozostałe
kluczami alternatywnymi.
BCMF Formalny sposób dekompozycji
tabeli nazywa się proc. normalizacji tabel
i przebiega etapowo:
1 forma normalna – wartość atrybutów tej
tabeli są wielkościami atomowymi nie
podzielnymi dla przyszłego przetwarzania
( nie może składać się z różnych typów)
2 forma normalna – spełnia 1 formę i każdy
atrybut zwykły (nie wchodzi w skład
klucza), jest w pełni funkcjonalnie zależny
od wszystkich kluczy właściwych
3 forma normalna – spełnia 1i 2 formę
i żaden atrybut zwykły (nie wchodzący
w skład klucza głównego) nie zależy
funkcjonalnie przechodnio od
jakiegokolwiek z kluczy właściwych
4 postać normalna. Dana relacja R jest
w czwartej postaci normalnej wtedy
gdy jest w trzeciej postaci normalnej i
wielowartościowa zależność zbioru Y
od X pociąga za sobą funkcjonalną
zależność wszystkich atrybutów tej
relacji od X.
5 postać normalna. Dana relacja r o
schemacie R jest w piątej postaci normalnej
wtedy i tylko wtedy, gdy jest w czwartej
postaci normalnej i w przypadku występowania
w niej połączeniowej zależności funkcjonalnej
*R[R1, ..., Rm] zależność ta wynika
z zależności atrybutów od klucza.
Dwa atrybuty są funkcjonalnie zależne
gdy wartość jednego z nich jednoznacznie
określa wartość drugiego, czyli z daną
wartością klucza będzie powiązana zawsze
część klucza właściwego to ten atrybut nie
jest w pełni funkcjonalnie zależny od
klucza właściwego atrybut zwykły ma
zależeć funkcjonalnie jedynie wprost
od 1 klucza właściwego
zależność funkcjonalnie przechodnio
– nie chcemy sytuacji w której jakikolwiek
atrybut mógłby być funkcjonalnie zależny
przechodnio przez cokolwiek co nie jest
kluczem właściwym
1 typ tabel do przechowywania danych
(podstawowe)
2 typ do przechowywania informacji
o związkach logicznych m.:n
3 typ integralności danych (aby uniknąć
błędów wpisywania np. płeć
Anomalie i Wady BD:
1) Redundancja- powtarzanie,
gromadzenie ponowne tych samych
danych, np. jeżeli chcielibyśmy wpisać
następną książkę Urbanowi to musielibyśmy
wpisać jeszcze raz każdą jego daną.
2) Anomalia dołączania- wadą jest to, że
musimy wpisywać wszystko albo nic, np.
przychodzi Wałęsa, ale nic nie pożyczył
więc nie możemy go wpisać, tym samym
nie możemy zapisać jego wizyty.
3) Anomalia automatyzacji- np. przychodzi
Urban w czerwcu 1981 i z Wiejskiej
przeprowadza się na Śliską, zmieniamy
więc mu pierwsza pozycję i nagle
zbrakło prądu. Reszta pozycji pozostała
niezmieniona i powstała niezgodność
w adresie. Jest pewna niespójność,
sprzeczność.
4) Anomalia usuwania- np. Mazowiecki
zarządził, że odkreślamy wszystko, co było
pożyczone przed 13.12.81, włącznie
z 13.12.81. Wtedy tracimy wszystkie dane,
np. te, że Urban i Jaruzelski byli w bibliotece.
Sql -Deklaratywne co my chcemy od
systemu . Proceduralne w jaki sposób
uzyskujemy informację
Algebra relacji.– określony zbiór na którym
można wykonywać działania , A=<A,F>
Grupy operacji:
Zwyczajne działania algebry zbirów:
suma, przecięcie (część wspólna), różnica.
Operacje zawężania: selekcja, rzut.
Operacje komponowania krotek z innych
krotek pochodzących z innych relacji
np. iloczyn kartezjański.
Operacje przemianowania- nie zmieniają
krotek relacji ale jej schemat: nazwę atrybutu
i / lub nazwę relacji.
Język zapytań buduje się z wyrażeń algebry.
Rozszerzony model relacyjny
Chcemy mieć rozszerzenie umożliwiające
określić prawa dostępu użytkownikom
bądź grupom. Kontrolę dostępu musi zapewnić
SZBD a nie programy korzystające z BD
Kontrola integralności danych – funkcja SZBD
Odpowiedzialna za kontrolę dostępu.
Dodatkowe elementy zapewniające kontrolę
Integralności danych :
1) tablice słownikowe (walidacyjne) wykaz
dopuszczalnych wartości
2) wartości domyślne jeśli użytkownik
nie podaje żadnej wartości
3) unikalność wartości danej – system SZBD
pilnuje aby w danej kolumnie wartości
się nie powtórzyły
4) NULL wartością niedopuszczalną
5) określamy daną jako wymaganą (obowiązkowa)
6) reguły wprowadzania – dla danego
atrybutu ustala regułę wprowadzania
wartości która odsyła do procedury która
określa : - co zrobić gdy użytkownik nie
poda żadnej wartości
- obliczamy wartość na podstawie innych
danych
reguła wprowadzania może zawierać
- polecenia SQL
- inne warunki sprawdzające integralność
7) warunki aktualizacji i dopisywania
8) integralność klucz głównego czyli
sprawdzenie unikalności klucz głównego
9) warunek integralności referencyjnej
połączenia tablic za pomocą kluczy
10) ustalenie klasy przynależności wierszy
obowiązkowa musi istnieć odpowiednik
danego wiersza w drugiej tabeli
Restrykcyjny charakter kasowania rekordów
SZBD pilnuje aby była zachowana integralność
referencyjna pomiędzy kluczem głównym
a kluczem obcym
Kaskadowy charakter kasowania rekordów
Jeżeli chcemy usunąć wiersz o danym kluczu
głównym to system wykasuje z innych
tablic wszystkie wiersze o kluczu obcym
odpowiadającym danemu kluczowi głównemu
11) stopień uczestnictwa – jeśli mamy
zależność typu 1:n będziemy mogli określić
n min i n max
12) reguły biznesowe – pewne reguły opisujące
aspekty opisywanej rzeczywistości których
nie udało się wyrazić za pomocą tych ogólnych
13) ustalamy na stałe że w modelu istnieje
tablica wynik tworzona na podstawie
określonej komendy SELECT
System jest to całość środków zgromadzonych
i zorganizowanych dla realizacji określonego
celu. Środki :
1) komputery 2) oprogramowanie
podział ze względu na sposób realizacji
1) systemy obliczeniowe –dla realizacji
obliczeń od najprostszych do wielkiej skali
2)metody symulacyjne symulujący jakąś
rzeczywistość są trudniejsze i większe
od obliczeniowych
3) systemy do przetwarzania danych
masowych
4) systemy czasu rzeczywistego – których
zadaniem jest generowanie sygnałów
sterujących w czasie rzeczywistym
bardzo ważna jest kontrola poprawności
danych wejściowych
1) sprawdzenie każdej pojedynczej danej
( typ ,wartość, ograniczenie zakresu)
2) powiązanie logiczne grupy danych
umożliwiające sprawdzenie niektórych
danych należących do tej grupy (pesel)
3) można próbować wykorzystać już
wcześniej wprowadzone dane do
sprawdzenia tych nowowprowadzanych.
Funkcje systemu
1) przechowywanie
2) wyszukiwanie / przetwarzanie
kodowanie danych – przechowujemy nie
daną w jej oryginalnej postaci ale
w postaci kodu
a) szyfrowanie w celu utajnienia informacji
b) zmniejszenie objętości danych w pamięci
masowej
c) ułatwienie przetwarzania lub wyszukiwania
d) kody kontrolne (detekcyjne)
e) kody kontrolno - korekcyjne pozwala
stwierdzić w którym miejscu informacja
uległa przekłamaniu
organizacja pliku przechowującego dane:
a) plik seryjny
b) plik z rekordami które zawsze
uporządkowane - plik sekwencyjny podział
na obszary które są z kolei są podzielone na
jeszcze mniejsze elementy
c) organizacja randomizowana: indeksowanie
haszowanie
Podejścia przy projektowaniu i tworzeniu
a) Diagnostyczne stosuje się gdy mamy
pewien zastany system informatyczny
(struktury dane przepływ informacji)
i chcemy go skomputeryzować.
b) Prognostyczne rzadko stosowane przed
powstaniem jakiejkolwiek struktury
informatycznej zastanawiając się na budową
sys. komputerowego dostosujemy ten
ten dopiero tworzony sys. informacyjny do
tworzonego sys. komputerowego.
c) Prototypowanie – nie wytwarzamy
końcowego systemu docelowego tylko
tworzymy pewien fragment systemu
(prototyp) ale w taki sposób abyśmy
mogli go później łatwo rozbudować aż do
uzyskania ostatecznego produktu.
d) extreme programing
Najczęściej stosowane -podejście
diagnostyczne : a / tanie b/ klasyczne
w podejściu klasycznym cały proces dzielimy
na etapy (etapowanie prac)
Etapy w podejściu klasycznym
(diagnostycznym) 0 – postawienie problemu
próbujemy zdefiniować problem
który będziemy chcieli żeby system nam
rozwiązał cel tworzrnia systemu. Postawienie
problemu wskazuje na pewne uwarunkowania
które przy realizacji CELU będą musiały
zostać uwzględnione najtrudniejszy do
formalizacji. 1- opis (rzeczywistość której
ma dotyczyć system) opisujemy to co istnieje,
obieg dokumentów w firmie dokumentacja
prowadzona w podczas działalności firmy,
funkcjonowanie firmy itp. Opis staje się
znacznie czytelniejszy gdy wprowadzimy
schematy (działania, funkcjonowania
elementów opisywanej rzeczywistości )
i komentarze do tych schematów schemat
strukturalny opis tego czego będzie dotyczył
nasz system, opis przydaje się szczególnie
przy pracy nad dużymi projektami.
2 - analiza – analizujemy wszystkie elementy
tego świata który opisaliśmy oraz wszystkie
metody rozwiązania podstawowego problemu
3 - tworzenie koncepcji systemu (jeszcze
nie projekt systemu). wizja naszego przyszłego
systemu- pewne ogólne założenia elementów
składowych systemu. Koncepcja bez zbędnych
szczegółów, na tym etapie powinniśmy
określić ogólny sposób realizacji naszego
systemu. Może składać się z kilku warstw:
a) Ogólna
b) Koncepcja funkcjonalna
c) Koncepcja techniczna
d) Koncepcja sprzętowa
4 – projekt musimy szczegółowo określić
wszystkie elementy naszego przyszłego
systemu. Pod koniec tego etapu powinniśmy
dostać bardzo dokładna dokumentację
projektowa – na jej podstawie będzie się
odbywała implementacja systemu.
5 – implementacja będzie różna w zależności
od tego jakich narzędzi będziemy używać.
6 – testowanie jest bardzo złożonym etapem
tworzenia systemu - warstwy (etapy)
testowania: a) testowanie kodu
b) testowanie zakładanej funkcjonalności
c) testowanie funkcji od strony użytkownika
bardzo często będziemy mieli do czynienia
ze sprzężeniem zwrotnym(->implementacja;
-> projekt; -> analiza;-> opis;-> ; jest bardzo
źle jeżeli musimy cofnąć się do koncepcji)
d) testowanie wydajności systemu
e) testowanie na danych próbnych –
sprawdzamy czy system na danych
wprowadzonych z rzeczywistości się sprawdza.
Te dane powinny być różnorodne
Trzeba mieć przygotowany projekt testowania
7 – eksploatacja próbna próbujemy
rzeczywiście ten system używać ale nie
usuwamy jeszcze starego systemu.
8 – eksploatacj + rozwój.
Standaryzacja I podejście diagnostyczne
Techniki wykonywania pewnych etapów
tworzenia Oprogramowania
a) formularze – pewien wzór według
którego postępujemy, opusujemy itp.
Zaletą jest to że nie zapominamy o żadnym
podpunkcie do wypełnienia.
Np. Schematy Bachmona ??, metoda Coda
Duży nacisk na metody graficzne(czytelność)
Z załącznikami uszczegułowiającymi
konkretne elementy.
Np. diagramy DFD, ERD – nadają się najlepiej
gdy przyszły model logiczny bazy będzie
modelem relacyjnym.
Jakie są możliwości poprawienia już
skończonego systemu ? potrzebne są
narzędzia wspomagające rozwijania (tworzenia)
systemów baz danych
II podejście prognostyczne ( musimy
przewidzieć kształt całej organizacji pod
przyszły kształt systemu informatycznego)
zaczynamy od najlepszego rozwiązania
a) najnowsze technologie sprzętowe
b) najnowsze tech. tworzenia oprogram.
c) najnowsze języki programowania
d) najnowsze sposoby rozwiązywania
problemów typu sterowanie, diagnostyki,
komputerowego wspomagania
program w języku C ze wstawkami np. SQL
przy napotkaniu poleceń w SQL’u są one
przekazywane do SZBD. SZBD może
zwrócić żądane dane komunikat.
Dodatkowe biblioteki pośredniczące :
ODBC, JDBC(java)
(Dopasowują elementy programu użytkowego
do elementów baz danych) uzyskujemy:
a) przenośność programu użytkowego
b) uniezależnienie od SZBD
możemy mieć program (narzędzie
wspomagające) umożliwiające wizualne
składanie (definiowanie) z predefiniowanych
elementów, formatek do naszego programu
użytkowego.
Uzyskujemy ujednolicenie (standaryzację)
formularzy naszego programu użytkowego
Kolejnym elementem do standaryzacji są raporty
1 burz mózgów – najlepiej bardzo
zróżnicowany zespół ludzi
2 podejście teoretyczno- optymalne to najlepsze ale nie sprawdzone i drogie
3 podejście akceptowalne:
a) sprzętowo, technologicznie
b) finansowo
wydawać by się mogło ze dostaniemy projekt
taki jak przy metodzie diagnostycznej ale :
a) system będzie lepiej przygotowany na
przyszły rozwój (tworzymy system ze
świadomością tych najnowszych technologii)
b) część z tych najnowszych rozwiązań
z pewnością ” uratujemy ”
Cykl życia projektu
wdrożenie
pełne
problem
opis 1
wdrożenie
próbne
EiR
analiza 2
testowanie
koncepcja 3
implementacja XX
projekt
XX w tym momencie możemy pokazać
użytkownikowi ale się okaże że to nie
działa tak jak powinno lub robi inaczej
musimy wrócić do 1 i 3
E –eksploatacja
Można zastosować inne podejście
Prototyp1
problem
opis 2
analiza 3
koncepcja 4
projekt 5
implementacja 6
testowanie 7
T2
wartości dodane do systemów baz danych
a) narzędzia wspomagające projektanta
baz danych w tworzeniu całego projektu
najlepiej stosować te narzędzia tam gdzie pewne
rzeczy są najbardziej sformalizowane
.” C ”..
SO
SZBD
Kolejny element do standaryzacji -> MENU
( nasz program wspomagający generuje kod
dla tego standardowego MENU w sposób
automatyczny). Następnie – pewien ogólny
szkielet programu Kolejny – pewne gotowe
elementy do tworzenia procedur (funkcji)
w języku w którym piszemy nasz program
użytkowy Ostatnie – pewne gotowe
wstawki w SQL’u
Narzędzia wspomagające – obiektowe –
budowanie oprogramowania przy użyciu
gotowych obiektów Możemy mieć jeszcze
moduł wspomagający tworzenie definicji
bazy danych. W ostateczności otrzymujemy
pewien generator aplikacji Bridge –
oprogramowanie powstałe między
” wersjami pośrednimi ”
Możemy zapisywać elementy naszego
systemu w celu późniejszego wykorzystania
( ale nie program tylko projekt )
to są tzw. słowniki lub repozytoria
narzędzia wspomagające typu CASE
moduł kontroli
poprawności danych
moduł inżynierii
odwrotnej
Słownik
repzytorium
generator kodu
moduł dokumentowania
J2
P2 A2 O2 W
Prototyp 2
opis2 – pobieżny opis tylko najważniejsze
elementy
analiza 3 najistotniejszych problemów
budowa koncepcji 4 systemu w oparciu
o pobieżnej analizie i opisu nie musi
uwzględniać szczegółowych problemów
testy 7 coś możemy pokazać
system mamy wcześniej ale nie mamy
całej funkcjonalności
W tym drugim modelu posiadamy narzędzia
(systemy, case’y, środowiska)wspomagające
tworzenie oprogramowania. Dzięki temu
osiągnięcie etapu pierwszego prototypu nie
wymaga tyle czasu i wysiłku od nas.
Umożliwiają tez łatwe wprowadzanie zmian
i ich automatyczne uwzględnienie w systemie
Te środowiska muszą być w stanie
dokumentować nasz kod (-> XP Extreme
Programming)
Metoda punktów
węzłowych
(Szyjewskiego)
na każdy taki węzeł składa się kilka zadań
które trzeba wykonać aby móc przejść do
następnego węzła. Część tych węzłów
może być powiązane relacjami
1 zgłoszenie potrzeby
2 analiza
3 zdefiniowanie zadania projektowego
4 opis
5 analiza
Szukamy i opisujemy wszystkie
normatywy ( używamy obowiązujące normy)
moduł pracy grupowej
moduł pracy sieciowej
Interesują nas następujące cechy
systemów
a) duża pamięć
zewnętrzna i szybki dostęp do niej
b) dostęp wieloużytkownikowy
c) szybkość
program użytkowy
DEF
definiu
je
moduły
integralności dostępu
system operacyjny
ZSBD
fizyczna BD
Każda kopia SZBD obsługuje pojedynczego
użytkownika (program użytkowy) przy wielu
użytkownikach potrzebujemy większej
pamięci operacyjnej i mocniejszego procesora.
Tych wielu użytkowników tak naprawdę
”podłącza się ” się przez system operacyjny.
Fizycznie podłączają się za pomocą terminali.
Wprowadzamy wielowątkowość –
oszczędzamy znacznie na pamięci
operacyjnej Musimy mieć wielowątkowy
system operacyjny, SZBD i być może
oprogramowanie użytkowe.
Wprowadzamy wieloprocesorowość.
System operacyjny rozdziela procesy na
poszczególne procesory. Musimy mieć
nowy SZBD, który potrafi zarządzać
wielozadaniowością swoich zadań
(wątków) na poszczególnych procesorach.
Możemy przyspieszać operacje dyskowe
-> striping. Szybszy zapis i szybszy odczyt
Plusy takiej zwartej architektury
a) mniejsze nakłady na organizację
i administrację
b) mniejsze nakłady na użytkowników
(terminale)
c) większe bezpieczeństwo
moduł projektowania
interfejsu użytkownika
ta architektura była podstawą koncepcji,
którą przez lata była niepopularna
a teraz staje się coraz częściej wykorzystywana
-> ”mainframe” np. IBM 5390
Taki system można wykorzystać w
następujących etapach :
1 projekt
LOW CASE
2 implementacja
(CASE’y niskiego
3 testowanie
poziomu)
systemy wspomagające wcześniejsze etapy
nazywamy UPPER CASE
usługi outsourcingowe – wykonywanie na
zlecenie obliczenia itp.usługi outsourcingowe
konserwacja systemu a) przystosowanie
systemu użytkowego do zmieniających się
warunków zewnętrznych np. przepisów
prawnych b) przystosowanie do coraz to
nowszych wymagań zleceniodawców
architektura terminalowa – jest typowa
dla systemów zbudowanych w oparciu o
komputery klasy mainframe i minikomp.
oraz wczesne systemy unixowe
w takich systemach SZBD oraz aplikacje
działają na centralnym komputerze a
użytkownicy maja do dyspozycji
inteligentne terminale (najczęściej znakowe).
Architekturę te spotyka się głównie w
dużych instytucjach np. banki
W miarę upływu czasu użytkownicy
terminalowi (podłączeni do maszyny typu
mainframe) zaczęli wymieniać terminale
na pełne komputery, które maja dużą
niewykorzystana moc. Zastanawiano się
jak ja wykorzystać, aby odciążyć maszynę
mainframe. SZBD został na mainframe
a aplikacje zostały przeniesione na komputery.
Problem- w Mainframe aplikacje były
dwuczęściowe( jezyk progr + jezyk
manipulacji danymi, który był
wykorzystywane przez SZBD) Rozwiązanie
-na każdym komp instalujemy pewien pseudo
SZBD ( żeby aplikacje działały bez potrzeby
większych zmian), który odwołuje się do
SZBD na mainframe.
SERWER
SZBD STAR
CLIENT
SZBD NET
APLIKACJA
Mainframe w tej architekturze realizuje
już tylko dostęp do danych dla programów
użytkowych uruchamianych na innych
komputerach.= > architektura
klient-serwer. SZBD działa tu na centralnym
komputerze serwerze, zaś aplikacje działają
na komputerze klientów. Rolę serwerów
pełnią najczęściej systemy unixowe, zaś
stacjami klientów sa komputery PC albo
stacje robocze Na serwerze odbywa się
przechowywanie danych , wykonywanie
zapytań i przetwarzanie danych, natomiast
stacje klientów wykonują logikę aplikacji
(w tym obsługę złożonego interfejsu
graficznego GNU i niekiedy także
elementy przetwarzania danych .
Arch. Ta jest dobrze dostosowana
do możliwości małych i niedrogich
komputerów, daje duże możliwości
rozbudowy i skalowania podłączenie tutaj
nowego klienta jest bardzo łatwe i zwykle
nie wymaga inwestowania w sprzęt, na
ogół nowy użytkownik ma już PC.
Potrzebna jest na ogół instalacja
odpowiedniego oprogramowania .
Architektura świetnie przystaje do sposobu
przetwarzania SQL-owych relacyjnych baz
danych. W tym modelu przetwarzania zapytania
(krótkie testy) Są wysyłane do serwera danych,
a serwer odpowiada odsyłając jedynie te ( na
ogół nieliczne) dane, które są potrzebne, nie
jest potrzebne masowe przesyłanie danych
przez siec. System klient-serwer oszczędnie
wykorzystuje sieć a komputer centralny jest
odciążony od zadań, które z powodzeniem
mogą być wykonane na klientach.
Podstawową wadę tej architektury stanowią
znaczne koszty użytkowania komputerów
klientów. Okazuje się że wyposażenie klientów
w PC. Powoduje szereg problemów
np. konieczność instalowania oprogramowania
na wielu różnych skonfigurowanych komputerach
konieczność częstej wymiany sprzętu wraz ze
wzrostem wymagań systemów , problemów z
bezpieczeństwem (np. tworzenie przez
użytkownika niebezpiecznych lokalnych kopii
d anych, zagrożenie przez wirusy, brak pełnej
kontroli nad działaniami pracowników,
brak kontroli licencji.
Plusy :
a) tworzenie aplikacji jest tańsze
* prostszy system
* więcej tańszych specjalistów i
narzędzi do tworzenia oprogram.
b) rozlozenie obciążenia
Minusy: a) musimy stworzyć oprog.
na więcej, różnych platform sprzętowych
i systemowych.
b) problemy z administracja- oprogr.
trzeba aktualizować u wielu użytkowników
c) problemy z „dograniem” oprogramowania
z tymi wieloma platformami systemowymi.
=> ta architektura jest nie do utrzymania
***
Ponieważ ciężko zarządzało się aplikacjami
u klientów to je stamtąd zabieramy
Dodajemy drugi duży komputer na którym
uruchamiamy aplikacje użytkowe
Wracamy do poprzedniej arch. ponieważ
ciężko zarządzało się aplikacjami u klientów,
wiec je stamtąd zabieramy.
Dodajemy drugi duży komputer na którym
uruchamiamy aplikacje użytkowe
Powód –utrzymanie poprzedniej arch.
jest ostatecznie droższe od tego drugiego
mocnego komputera
Serwer
Serwer
BD
Aplikacji
Klient
Architektura wielowarstwowa
Użytkownicy chcą jednak wykorzystać
w pełni swoje komputery klienckie
możemy założyć ze wszyscy maja
zainstalowane przeglądarki WWW.
W aplikacjach użytkowych do SZBD
(tych działających na drugim mainframe’ie)
dokonujemy modyfikacji-teraz generują
one tylko kod html a interpretuje go
przeglądarka WWW na komp klienta
SERVER
(odciążenie serwera
aplikacji.)
SZBD
DEF
Dodatkowo na serwerze
aplikacji
musimy uruchomić serwer WWW.
Logicznie mamy architekturę
4-warstwowa: 1) syst baz danych
SO
2) serwer aplikacyjny
3) serwer WWW
4) klient + przegladarka WWW
F. BD
Jak wygląda komunikacja pomiędzy
serwer BD a serwer aplikcji
Wszystkie SZBD maja wymagania w jakiej
postaci chciałyby dostać komendy SQL-owe
zanurzone w kodzie(np. C). Taki
standardowy dla danej bazy interfejs(~API)
nazywa się CLI. Potrzebny jest specjalny
interfejs pośredniczący ( bridge ) który
odbiera zapytanie do SZBD z aplikacji i
automatycznie zamienia go na pewne
konkretne CLI danego SZBD.=> została
opracowana pewna norma takich
odwołań => ODBC. Sterowniki ODBC
przerabiają zapytanie na określone CLI
Dla Javy JDBC. Dla każdej bazy danych
potrzebujemy osobny sterownik
ODBC=>który wybiera automatycznie
który sterownik ODBC w danej chwili
użyć. Drugim problemem jest różne
interpretowanie kodu HTML’a przez
przeglądarki WWW różnych producentów.
Rozproszone bazy danych
Tworzymy model logiczny i okazuje się
ze jest on bardzo duży =>chcemy to
podzielić na np. dwa serwery.
rozproszenie na
poziomie fizycznym
i logicznym
Odwołujemy się do dowolnego serwera
i ten serwer ma obowiązek nas obsłużyć.
Jeżeli nie posiada określonych danych to
on sam odwołuje się do innych serwerów
i zwraca nam dane.
Transakcje rozproszone => dwufazowe
potwierdzenie transakcji. Operacje
przeprowadza się na każdym serwerze
Wszystkie serwery wykonują je do końca.
Gdy wszystkie serwery potwierdza
wykonanie następuje realne wykonanie
transakcji. Gdy mamy wiele serwerów to
pojawia się problem koordynacji. Możemy
mieć koordynatora :
-fizycznego-jeden z serwerów; pojedynczy
punkt uszkodzenia całego systemu.
-wirtualnego-tak naprawdę nie ma
koordynatora, serwery dogadują się
miedzy sobą same.
A
Około 80% danych w starszych niż model
relacyjny modelach.
Sieciowo-codasylowy
hierarchiczny.
Grupowanie danych w wierszach.
Grupowanie danych w plikach fizycznych.
Organizacja seryjna-rekord jeden po drugim,
czytamy po kolei i szukamy aż znajdziemy,
rekordy nie są uporządkowane
Organizacja sekwencyjna-jak seryjna, ale
rekordy są uporządkowane według
jakiegoś atrybutu.
Model logiczny hierarchiczny
Róże typy danych przechowywano na
różnych plikach fizycznych. Dodatkowo
można łatwo przechowywać związki
logiczne pomiędzy rekordami z różnych
plików. Właściwie mamy w takiej sytuacji
rekordy logiczne(które przez system są
odwzorowywane na rekordy fizyczne).
Zadajemy pytania do modelu logicznego
za pomocą deklaratywnego języka zapytań.
Mamy logiczne rekordy, które mogą być
odwzorowywane w pewne rekordy fizyczne
powiązane miedzy sobą – te powiązane są
automatycznie tworzone przez SZBD na
podstawie modelu logicznego
Organizacja listowa jest bardzo efektywna.
Kolejna optymalizacja było przechowywanie
po dwa adresy w każdym rekordzie
-lista dwukierunkowa.
Wydział
Pracownik
sssss
ss student
ocen
a
Po dodaniu połączenia między pracownikiem
a oceną tracimy hierarchie w tradycyjnym
modelu hierarchicznym nie da się zrobić
połączeń do więcej niż jednego zwierzchnika
danego elementu.
Sieć elementów powiązań między nimi
Model sieciowy
Struktura hierarchiczna
master owner
detail
member
struktura sieciowa
set
owner
member
member może należeć do wielu setów
Bezpieczeństwo sys. bazodanowych:
1) dostęp do danych tylko przez
upoważnione osoby
2) zabezpieczenie przed utrata danych
Z punktu widzenia funkcji systemu:
-dostępność systemu- syst jest dostępny
dla użytkowników którzy są uprawnieni
-ochrona poufności - całościowo traktowane
elementy poufności w systemie(nie tylko
poufność danych)
-zadbanie o wiarygodność danychzapewnienie integralności danych w
systemie(pewność przechowywanych
danych)
Można wyróżnić wiele warstw
z niebezpieczeństwami, którym trzeba
przeciwdziałać 1) warstwa sprzętowa
2) System operacyjny
3 ) oprogramowanie, a konkretnie SZBD
4) programy użytkowe działające na bazie
danych 5) warstwa organizacyjna
działania naszego systemu
Bezpieczny system = bezpieczny
sprzet + bezp oprogramowanie +
warstwa organizacyjna
Niebezpieczeństwa:
a) kradzież
b) różnego typu uszkodzenia
c) nieupoważniony dostęp do różnych
części systemu
80% utraty danych wynika z umyślnego
działania własnych pracowników.
Formy zabezpieczeń :
1) dokładna selekcja pracowników
a) trzeba stworzyć pewne reguły
poprawnego zachowania pracowników
oraz egzekwować ich przestrzeganie
-nie zapisywanie haseł
-automatyczne blokowanie systemu po
pewnym czasie nieaktywności
b) sprawy formalno-prawne – trzeba
wyraźnie określić użytkownikom czego
im nie wolno robić -> w przeciwnym razie
brak odpowiedzialności pracownika
c) administratorzy, serwisanci, sprzątaczki, ...
2) procedury obsługi
a) dla administratora – komu może nadać
uprawnienia oraz nadać hasło i login
b) przekazywania danych
c) procedury dla serwisów
- ewidencja całej obsługi sprzętu
-wzór umowy przekazywania sprzętu
do naprawy
d) zachowania w sytuacjach zagrożenia
e) procedury obsługi dokumentów
źródłowych i raportów.
f) procedury obsługi kopii zapasowych
-jak maja być opisane
-sposób przechowywania
-sposób usuwania
3)bezpieczeństwo sieci
Trzy elementy bezpieczeństwa
1)dostępność danych
2)ochrona poufności danych
3)integralność danych
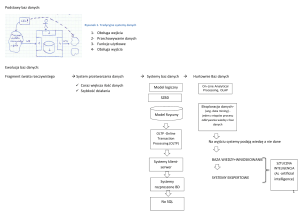
OLTP – bazy operacyjne, które nie nadają
się do analizy danych. Przeznaczone są
do dodawania, usuwania i edycji danych
czyli do manipulowania danymi.
OLAP- narzędzia zapewniające analizie
danych. Kluczowym komponentem jest
serwer OLAP który znajduje się pomiędzy
klientem a SZBD. Serwer OLAP rozumie
organizacje na danych w bazie danych
i posiada specjalne funkcje służące do
analizy danych.
Dla potrzeb analizy pracujemy na replikach
OLTP
(bazy operacyjne)
repliki
stary system
tutaj możemy
działał tak jak sobie dokonywać
działał
analiz
wady: pracujemy na danych których
struktura nie jest przygotowana
dobrze do analiz
meta-dane
ładowanie
hurtowni
Serwer OLAP
GUI
Warstwa sprzętowa
1) zasilanie-jeśli mamy bezpieczną sieć
elektryczna na UPS to zdecydowanie
z niej korzystamy
Jak mamy normalne zasilanie to korzystamy
z ups’a a) filtrowanie
b) podtrzymane zasilanie
Może być on-line lub off-line
Agregaty prądotwórcze – w przypadku
dużych systemów wymagających długiego
podtrzymywania zasilania. Bardziej
zaawansowane UPS’y maja kartę
sieciową - zarządzanie komputerami przez
siec, powiadomienie administratora, zdalne
administrowanie. Urządzenia sieciowe tez
powinny być podłączone przez UPS’y.
2) Systemy o wysokim stopniu
niezawodności kwestia zwiększenia
niezawodności systemu związana jest
z porównaniem kosztów z potencjalnymi
stratami(lub stawka ubezpieczenia)
3) pamięci masowe- macierze dyskowe
4) systemy backupowe archiwizacja
danych. Dwa typy archiwum:
- danymi archiwalnymi, z poprzednich
okresów działalności
- kopia bezpieczeństwa danych
Różnego rodzaju metody kopiowania:
-proste, zwykle kopiowanie danych
+ dziennik zmian od czasu ostatniej
kopii
-kopie bezpieczeństwa syst działających
24/h => specjalne oprogramowanie
działające pod kontrola SZBD.
-kompresja
-szyfrowanie
-zrzut systemu operacyjnego
5) bezpieczeństwo sieci : Zagrozenia
- bierne – podsłuchy oraz analiza
ruchu w sieci
- czynne
a) maskarada – udawanie kogoś innego
b) modyfikacja treści
c)podpinanie się pod legalne pakiety
d) DOS
e) ’tylne drzwi’
Trzy elementy bezpieczeństwa na
poziomie SZBD
1) dostępność danych
a) w najprostszych SZBD mamy tylko
instrukcje, które pliki mamy sobie
sami archiwizować
b) w lepszych SZBD są specjalne
moduły, które wykonują za nas
kopie bezpieczeństwa, odtwarzają dane.
c) w najnowszych SZBD mamy możliwość
robienia kopii bezpieczeństwa
Kopia == replika
Repliki służą także do odciążania
oryginalnej bazy danych. W najnowszych
i największych SZBD wiele replik może
być równoprawnych i nawzajem się
uaktualniają -> technologia grid’owa
2) ochrona poufności danych
DEF opisują prawa dostępu do danych
w bazie. My musimy zapewnić ochronę
przed niepowołanym dostępem do DEF.
3) integralność danych
-sprawdzenie poprawności danych
-pole wymagane / niewymagalne
-może być NULL albo nie
-unikalność danego pola
-integralność referencyjna
OLTP
OLAP
Hurtownia danych
Pobieramy dane z różnych systemów
OLAP i poddajemy je różnym operacjom
Operacje na danych:
a) uzgadnianie danych (pochodzących
z różnych systemów baz danych)
b) czyszczenie danych-do analizy mogą
nam nie być potrzebne oryginalne dane
c) agregaty-do analiz zazwyczaj są nam
potrzebne pewne dane zbiorcze a nie
wszystkie szczegółowe dane
d) ziarnistość danych-musi być taka sama
ziarnistość danych (ziarnistość
np. dzienna tyg, miesięczna)
e) ładowanie bazy danych-a dokładnie
ładowanie hurtowni danych.
Hurtownia danych jest pewna zbiorcza
baza danych ukierunkowana dla potrzeb
dokonywania analiz danych. W takim
kształcie tworzymy hurtownie za
pomocą procesu ‘ładowania hurtowni
danych’. Hurtownia danych nie jest
jeszcze systemem OLAP.
W systemach OLAP model logiczny
danych to wielowymiarowa kostka danych.
Wartości w poszczególnych komórkach
kostki są wyliczane na podstawie danych
pochodzących z hurtowni danych.
Te wyliczone dane można przechowywać
na trzy sposoby:
1) MOLAP – do przechowywania struktur
wielowymiarowych używa bazy
wielowymiarowej
2) ROLAP – do przechowywania struktur
wielowymiarowych używa tabel w relacyjnej
bazie danych
3) HOLAP – do przechowywania struktur
wielowymiarowych używa dedykowanej do
tego bazy wielowymiarowej(dla danych
zagregowanych) w połączeniu z tabelami w
relacyjnej bazie danych
MOLAP jest bardzo szybkie, ale źle się
sprawdza przy dużych kostkach , natomiast
ROLAP jest wolniejszy ale radzi sobie z
bardzo dużymi kostkami
Sposoby realizacji modelu logicznego:
MOLAP: szybki, nie nadaje się do dużej
ilości danych
ROLAP: wolny, bardziej elastyczny
HOLAP: sys. o różnych arch. za każdym
razem zależy od implementacji
OLTP: w tym systemie musimy tworzyć
hurtownie danych, a interfejs jest między
hurtownią a użytkownikiem, interfejs musi
pozwolić na łatwy sposób zadawania pytań
OLAP: oparte o zupełnie inna technologię,
nowy model logicznych danych, nowy
język zapytań (warunek intuicyjności),
nowy sposób raportowania(wykresy,
eksport danych do innych systemów)
Hurtownia danych:
-etap projektowania: ładowanie (zagregowanych
informacji, różny stopień szczegółowości)
okresowo, aktualizowanie, doładowywanie,
budowanie zasad działania bez danych ze
względu na zgodność gł. model logiczny to
model gwiazdy (bardziej skomplikowany to
model płatki śniegu)=>ROLAP
model fizyczny – odwzorowania kostki
w pliki=>MOLAP
oprogramowanie power shut instalowane
jest na komp., jest możliwość wpięcia
do sieci przez UPS który jest prolongowany,
analiza kosztów i strat w przypadku awarii,
wieloseryjne połączenia, stosowanie macierzy
dyskowych, backup serwer, ochrona poufności
danych (logowanie)
Systemy:
-hurtownie danych(warehouse)
-systemy OLTP
-systemy DataMining
OLTP-on line transaction processing
Mamy w bazie informacje ale nie mamy do
nich dostępu, ponieważ mamy język zapytań
Problemy systemów:
-spowolnienie działania systemów OLTP
-rozbicie danych w różnych systemach OLTP,
-sposób zadawania pytań
-brak spójności danych różnych systemów
warstwa organizacyjna:
-zabezpieczenie przed kradzieżą
-zabezpieczenie przed uszkodzeniem
-zastosowanie środków organizacyjnych
zagrożenia występują w:
-otoczenie sprzętu komp.
-ochrona sprzętu przed własnymi
pracownikami
-ochrona przemieszczeń gdzie znajduje się
nasz system (strefy bezpieczeństwa z dobrze
dobranym personelem)
-ustalenie procedur postępowania w sytuacjach
awaryjnych (kto odpowiada, jaki czas,
procedura dostępu, zgłaszanie, sytuacje
nietypowe)
-opracowanie procedur odnośnie dokumentów
źródłowych -ochrona sieci (dostępność
regulowania: kodeks karny, ustawa o ochronie
danych objętych klauzulami, ustawa o ochronie
danych osobowych)
-organizacja outsource’ingu
warstwa sprzętowa:
-zabezpieczenie zasilania sprzętu przez
UPS: on line (na linii), in line (wygładza,
stabilizacja sygnałami) jeśli UPS nie jest
zasilany to energia bierze się z baterii
-najbardziej zaawansowane urządzenie:
ma dodatkowy kabel do odpowiedniego
oprogramowania sygnału, że jest zasilany
z UPS lub wysyła komunikat shutdown
SZBD
-Powinien rozdzielać zadania między
procesory
-powinien sterować rozdziałem zasobów
-powinien przyjąc definicję modelu fizycznego
-powinien być transparentny (nasz użytkownik
nie widzi skąd są brane dane)
-powinien znajdować się monitor transakcji