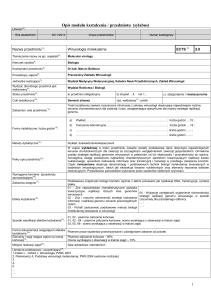
Replikacja bazy danych
Replikacja bazy danych
Replikacja bazy danych polega na kopiowaniu (powielaniu) i przesyłaniu danych lub obiektów bazodanowych
między serwerami oraz na synchronizowaniu tych danych w celu utrzymania ich spójności.
Dane kopiowane nazywamy danymi źródłowymi, dane docelowe — repliką.
Replikacja danych najczęściej wykorzystywana jest w systemach rozproszonych baz danych, gdzie dane z jednego
zdalnego węzła (serwera) są kopiowane do innych zdalnych węzłów. Celem replikacji jest skrócenie czasu
dostępu do danych oraz uniezależnienie się od czasowej niedostępności serwerów i awarii sieci.
Wadą replikacji jest konieczność aktualizowania repliki w przypadku zmian danych źródłowych. Proces
uaktualniania nazywamy synchronizacją (ang. synchronization) lub odświeżaniem (ang. refreshing) repliki.
Zalety replikacji
Dzięki replikacji możemy poprawić niezawodność i wydajność systemu bazodanowego
Replikując dane:
• umożliwiamy lokalny dostęp do danych
użytkownikom z oddalonych miejsc;
• pozwalamy na częściową niezależność
serwerów bazodanowych;
• możemy podzielić dane w sposób
odpowiadający wymaganej strukturze;
• możemy fizycznie rozdzielić serwery
bazodanowe realizujące różne zadania oparte
na tych samych danych.
REPLIKACJA
Modele replikacji
Model replikacji serwera SQL Server definiuje trzy role, które
mogą zostać przypisane serwerom bazodanowym.
Serwer może zostać skonfigurowany jako:
• wydawca (ang. publisher),
• dystrybutor (ang. distributor),
• subskrybent (ang. subscriber).
Wydawca to serwer baz danych, który przesyła dane do innego serwera lub do innej bazy danych.
Jego zadaniami są:
• utrzymanie wzorcowej bazy danych,
• udostępnianie tej bazy innym serwerom (wysyłanie danych do subskrybenta)
• monitorowanie zmian w replikowanych danych i przesyłanie informacji o tych zmianach do
serwera pełniącego funkcję dystrybutora.
Modele replikacji -dystrybutor
Dystrybutor to serwer baz danych, który zarządza przepływem
danych między wydawcą a subskrybentami.
Serwer ma bazę dystrybucyjną (ang. distribution), która jest
automatycznie tworzona podczas przypisywania serwerowi roli
dystrybutora.
Ponadto dystrybutor zarządza informacjami związanymi z replikacją danych, takimi jak:
• historia zmian danych,
• transakcje przeprowadzone na serwerach,
• konfiguracja serwerów biorących udział w replikacji.
Modele replikacji -subskrybent
Subskrybent to serwer (lub baza danych), który otrzymuje replikowane dane
od innego serwera (lub od innej bazy danych) i przechowuje ich lokalną kopię.
Dane przechowywane przez subskrybenta mogą zostać
udostępnione użytkownikom:
• tylko do odczytu
• do odczytu i modyfikacji.
Dane (publikacje) mogą być dostarczane:
• automatycznie (ang. push ) przez wydawcę
• mogą być pobierane okresowo (ang. pull) przez subskrybenta,
który w celu ich pobrania łączy się z bazą dystrybucyjną.
• Replikacja typu push zalecana jest w przypadku synchronizowania poufnych danych pomiędzy małą liczbą
serwerów i wymaga wydajnego serwera pełniącego funkcję dystrybutora.
• Replikacja typu pull zalecana jest w przypadku synchronizowania danych pomiędzy dużą liczbą serwerów.
Typy replikacji
W serwerze MS SQL Server występują trzy typy replikacji:
• migawkowa,
• transakcyjna,
• łączeniowa.
Replikacja migawkowa (ang. snapshot replicalion ) polega na systematycznym przesyłaniu danych z
określonych momentów od wydawcy do subskrybentów. Ten typ replikacji stosowany jest dla danych, które
nie są często modyfikowane.
Replikacja transakcyjna (ang. transactional replication ) — wszystkie zmiany w danych źródłowych są na
bieżąco przesyłane do replik w kolejności, w jakiej zostały wprowadzone. Ponieważ zmiany zapisywane są na
bieżąco, nie występują konflikty. Ten typ replikacji wymaga szybkiego i niezawodnego połączenia wszystkich
serwerów i dlatego w praktyce jest stosowany głównie w sieciach lokalnych.
Replikacja łączeniowa (ang. merge replication) — zmodyfikowane dane są przechowywane i w określonym
czasie przesyłane do dystrybutora, który rozwiązuje konflikty i wysyła dane do subskrybentów.
Konfiguracje replikacyjne
Każdy typ replikacji może zostać zaimplementowany w jednym
z fizycznych modeli replikacji. Najczęściej spotykane modele to:
model centralnego wydawcy — w tym modelu jeden serwer pełni funkcje
wydawcy oraz dystrybutora, który replikuje dane do dowolnej liczby
subskrybentów. Często role wydawcy i dystrybutora są przypisywane temu
samemu serwerowi. Jest to najczęściej spotykana konfiguracja.
model centralnego subskrybenta — w tym modelu
zakłada się, że dowolna liczba wydawców przesyła dane
do jednego subskrybenta, gdzie są analizowane
subskrybent
model równorzędny — w tym modelu zakłada się,
że w replikacji bierze udział dowolna liczba
wydawców oraz dowolna liczba subskrybentów
REPLIKACJA
Typy tabel w MySQL
W serwerze MySQL występuje wiele mechanizmów obsługi tabel. Każdy
z nich jest przeznaczony do innego zastosowania. Przy użyciu polecenia
CREATE DATABASE i jego klauzul lub TYPE można zdefiniować mechanizm
przechowywania danych, który zostanie użyty w definiowanej tabeli.
• MyISAM Jest to domyślny typ tabeli. Tego typu tabele pozwalają na szybkie odczytywanie danych, ale nie
obsługują transakcji. Powinny być wykorzystywane do przechowywania rzadko zmienianych danych.
• MEMORY Tabele. tego typu są przechowywane w pamięci operacyjnej, a dane w nich zapisane są tracone
bezpowrotnie po wyłączeniu serwera. Wykorzystywane są w nich indeksy mieszane (ang. Hash), dlatego
modyfikacje danych są bardzo szybkie. Tabele tego typu powinny być używane jako tabele tymczasowe.
Każda tabela typu MEMORY przechowywana jest w postaci pojedynczego pliku z rozszerzeniem frm, który
zawiera jedynie definicję tabeli.
• FEDERATED Tabele tego typu definiują dane znajdujące się na innym serwerze. W przeciwieństwie do tabel
innych typów tabele FEDERATED są bezpośrednio dostępne ze zdalnych serwerów MySQL Serwer lokalny
łączy się z serwerem zdalnym i bezpośrednio zapisuje dane w tabeli lub odczytuje je.
Typy tabel w MySQL
Aby wyświetlić informacje o dostępnych na serwerze
typach tabel, należy użyć polecenia : SHOW ENGINES\G
• BLACKHOLE Dane zapisywane w tego typu tabelach nie są przechowywane. Zapisywane w nich wiersze są
automatycznie usuwane. Ze względu na to, że informacje o operacjach wykonywanych na nich są zapisywane
w dzienniku zdarzeń serwera MySQL, tabele tego typu są przydatne podczas diagnozowania i testowania baz
danych.
• CSV Tabele tego typu służą do przechowywania danych w plikach tekstowych typu csv. Są używane do
importowania i eksportowania danych pomiędzy serwerem MySQL a innymi serwerami lub programami.
• ARCHIVE Tabele tego typu służą do przechowywania dużych ilości danych. Dane są przechowywane bez
indeksów i są kompresowane przed umieszczeniem w tabeli. Podczas odczytu danych następuje ich
dekompresja. Zmienianie lub usuwanie tych danych jest niedozwolone. Tabele typu ARCHIVE są używane
głównie do przechowywania zarchiwizowanych danych lub danych diagnostycznych.
• InnoDB Są to tabele obsługujące transakcje. Serwer MySQL automatycznie blokuje odczytywane i
modyfikowane wiersze tych tabel. Tabele InnoDB pozwalają również definiować i sprawdzać ograniczenia
klucza obcego.
Replikacja bazy danych na serwerze MYSQL
• Replikacja na serwerze MySQL działa na podstawie schematu master-slave.
• Serwer master wszelkie zmiany wprowadzane w bazie danych (aktualizację, usuwanie danych) zapisuje w plikach
logowania binarnego (binary logs). Dlatego, aby wykonać replikację bazy danych, należy włączyć rejestrowanie
binarne na serwerze master.
• Serwer (lub serwery) slave pobiera dane i zapisuje je w replice. Każda zmiana danych na serwerze głównym (master)
powoduje identyczną zmianę danych na serwerze zapasowym (slave).
• Ten typ replikacji jest replikacją jednokierunkową. Po podłączeniu do serwera master serwer slave przesyła
informacje o stanie uaktualnienia wpisów z dziennika replikacji.
• Jeżeli z jakiegoś powodu połączenie między serwerami master i slave zostanie przerwane, serwer slave będzie
próbował okresowo łączyć się z serwerem master, aż połączenie ponownie zostanie nawiązane. Po uzyskaniu
połączenia serwer slave zaktualizuje swoją bazę danych.
• Serwer slave może być skonfigurowany jako serwer master dla innych serwerów MySQL
Podstawowe cechy replikacji
• skalowalność — możliwość rozłożenia obciążenia na
wiele serwerów;
• bezpieczeństwo — tworzona kopia istniejącej bazy
danych może pomóc w przypadku awarii serwera
głównego;
• separacja — możliwość udostępnienia kopii bazy
danych wielu użytkownikom.
Zasada działania replikacji
• Zasada działania replikacji polega na zapisywaniu do dziennika przez serwer master każdej czynności,
którą wykonał. Wykorzystuje się do tego bin-logi. Są to pliki binarne zawierające instrukcje, które
wykonał serwer master.
• Serwer slave odczytuje te pliki i kolejno wykonuje zapisane w nich instrukcje. Efektem takiego
działania są dwie identyczne bazy danych.
• Po skonfigurowaniu mechanizmu replikacji na serwerze master pojawia się dodatkowy wątek dla
każdego serwera slave, który odpowiada za wysyłanie bin-logów do serwerów slave.
• Każdy serwer slave tworzy dwa wątki. Pierwszy (wątek I/O Thread) odpowiada za odbieranie
dziennika replikacji z serwera master i zapisanie go na dysku w plikach tymczasowych (relay-log).
• Drugi (wątek SQL Thread) zajmuje się parsowaniem plików tymczasowych i wykonaniem zapytań do
bazy.
Bin-log
Bin-logi przechowują informacje o wszystkich zdarzeniach, które
prowadziły do zmian w bazie danych. Są wykorzystywane do:
• tworzenia replikacji,
• odzyskiwania danych.
Włączenie rejestrowania binarnego na serwerze zmniejsza jego wydajność, jednak korzyści płynące ze
skonfigurowania replikacji są na tyle istotne, że przewyższają spadek wydajności serwera.
Rodzaje replikacji:
• SBR (Statement Based Replication, replikacja bazująca na zapytaniach) - serwer do pliku zapisuje polecenia, które
wykonał,
• RBR (Row-Based Replication, replikacja bazująca na wierszach) - do bin-logów zapisywane są wyniki działań zapytań
na serwerze MASTER. Zapisywana jest informacja, jaki rekord w jaki sposób został zmieniony,
• MFL (Mixed-Format Replication, replikacja typu mieszanego) - połączenie dwóch powyższych replikacji.
Technika SBR jest bardzo wydajna i szybka, ponieważ w jej przypadku serwer główny zapisuje do pliku zapytanie, jakie
wykonał, następnie serwer zapasowy je odczytuje i wykonuje. Niestety do plików zapisywane są tylko zapytania SQL, co
może przysporzyć kłopotów, gdy zapytania będą bardziej złożone.
Problem ten rozwiązała metoda RBR, która do bin-logów zapisuje wyłącznie zmiany, które zaszły po wykonaniu
polecenia: zapisywane są informacje na temat sposobu modyfikacji konkretnych rekordów. Niestety ta metoda jest
znacznie wolniejsza od poprzedniej oraz zwiększa ilość wysyłanych danych pomiędzy replikującymi się serwerami.
Z pomocą przyszła metoda MFL, w której w większości przypadków logowane są zapytania SQL, tak jak w przypadku
metody SBR, natomiast dla zapytań, których wynik nie jest przewidywalny włączana jest replikacja RBR.